由谷歌支持的AI初创公司Anthropic最近公布了一套针对AI发展的书面道德价值观,以帮助构建“可靠、可解释和可操纵的AI系统”。曾获得谷歌3亿美元投资的Anthropic在3月公布Claude AI模型时,特别强调对人类有益、诚实和无害特性。
该公司的AI聊天机器人“Claude”可以处理一系列较为复杂的任务,为了解决训练过程中无法预测人们可能会问的某些问题,Anthropic采用了一种新的方法,为Claude提供了一套书面的道德价值观,以供其在决定如何回答问题时阅读和学习。

这些价值准则包括“选择劝阻和反对酷刑、奴役、残忍和不人道或有辱人格的回答”,并要求Claude选择最不可能被视为冒犯非西方文化传统的回答。Anthropic的联合创始人杰克·克拉克(Jack Clarke)称,可以修改系统的结构,以便在提供有用的答案和无害之间取得平衡。
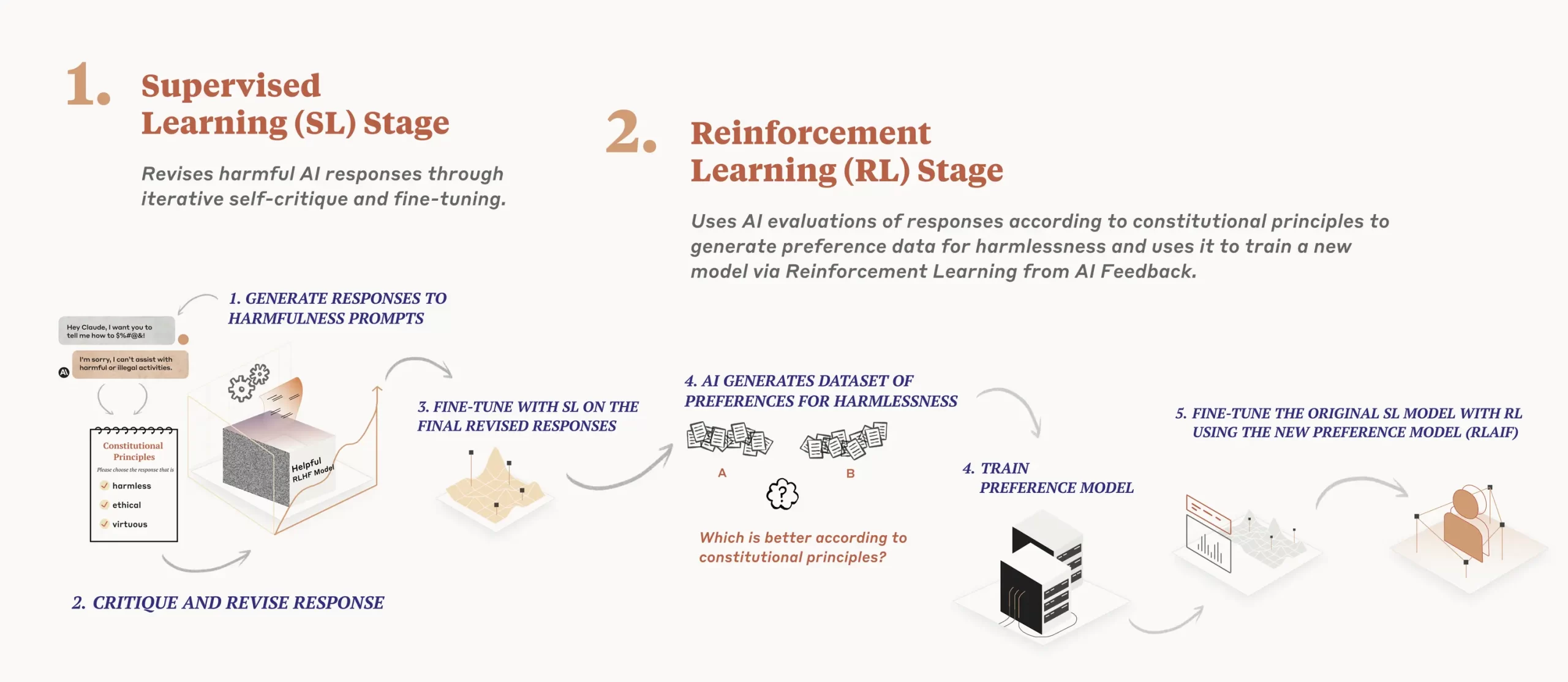
该公司说明,合宪AI是在2个阶段中,使用监督式学习(supervised learning,SL)及强化学习(reinforcement learning,RL)训练模型。
第一阶段(SL)中,他们以原始模型根据AI原则和一些范例,训练模型自我批判和修改其回应,再以此微调原始模型。第二阶段中,研究人员以微调过的模型以RL方法训练,由AI模型评估2种AI回应的样本哪种较好。但此AI模型不是使用人类给的回馈意见作为准则,而是用AI根据一组原则产出的回馈为评估标准,选出更为无害的回应结果。 Anthropic认为,结合SL及RL的这种训练方式可改善人为介入的AI决策过程,最终使AI行为更能精准控制,且大幅减少人类偏见影响。
该公司指出,以合宪AI方法训练出的Claude AI聊天机器人更能应付对话人发动的攻击,并仍以有助益的态度回应,其回应答案中所含的恶意、毒性也大幅减少。另一个好处是更透明,人类可以说明、检查和了解AI遵循的原则。此外,由于使用AI自我监督训练,因此模型训练也能减少有害内容对人类的创伤。
而训练合宪AI模型聊天机器人的原则,正是该公司的“AI宪法”。 Anthropic指出,目前版本的AI宪法以多个经典法则为基础,包括《联合国人权宣言》、DeepMind公司的Sparrow Principles,以及苹果的服务条款等信任与安全的最佳典范。
这部「宪法」用以训练AI聊天机器人的模型,提供其选择回应样本时的价值基准。其中一些原则包括,选择无害及合乎伦理的回应,不要选择有毒、种族偏见或性别歧视,以及鼓励非法、暴力行为的回应。选择展现具道德伦理的回应,不要表现出过于高傲、鄙视的态度。比较回应,避免选择说教及过于激烈的回应,尽可能选择无害、指控语气、礼貌、体贴及尊重的回应该公司说,这些原则并非最终版,只是集结现有的普世价值及AI业界规范,他们也希望未来有其他人加入这部宪法的编撰。
(部分内容来自:ITHOME)