
文章目录[隐藏]
南洋理工大学团队发布了一款新的视频渲染模型「Rerender A Video」,上传一段视频,加上一段“提示词”,AI 就能帮你把视频重画一遍,此模型最大的有点就是不掉帧。该团队将这个新框架和之前的几类文生视频框架进行了对比,包括 FateZero、vid2vid-zero、Pxi2Video 和 Text2Video-Zero 等,显然新框架目前是最流畅、鬼影也最少的。

[t-success icon='']RERENDER A VIDEO[/t-success]
「Rerender A Video」核心是提升 AI 生成视频时帧与帧之间的连贯性,包含关键帧翻译(key frame translation)和完整视频翻译(full video translation)两部分。第一部分基于扩散模型生成关键帧,基于跨帧约束加强这些关键帧之间的一致性;第二部分则通过基于时间感知的匹配算法将其他帧与关键帧“连接”起来。(具体可参考量子位文章)
论文地址:https://arxiv.org/abs/2306.07954

[t-success icon='']如何使用RERENDER A VIDEO?[/t-success]
目前该模型已经释出Demo,但该Demo并不是完整版,目前只支持最大8帧和最大帧分辨率(512x768)的视频,但该团队已经承诺之后会开源,大家可以先在Huggingface上进行试用,不过需要科学上网才能保证速度,因此大家先准备好工具才能进行下面的操作:
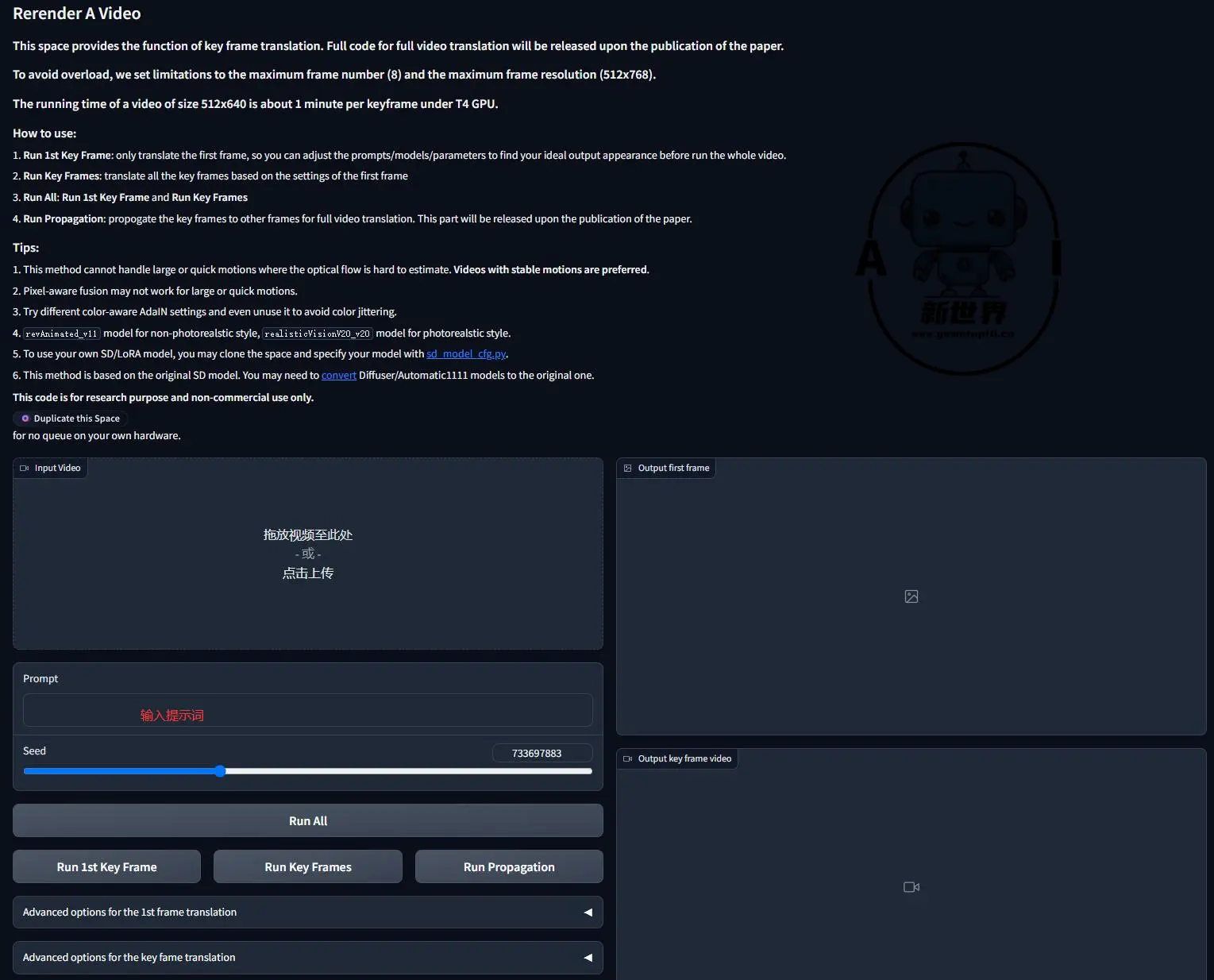
- Run 1st Key Frame: 在处理视频时,可以先翻译第一帧,以便在运行整个视频之前调整提示、模型和参数,以找到您理想的输出外观
- Run Key Frames: 基于第一帧的设置,翻译所有关键帧
- Run All: Run 1st Key Frame and Run Key Frames
- Run Propagation: 将关键帧传播到其他帧,以进行完整的视频渲染。这部分内容将在论文发表后发布
.webp~tplv-t19qeym4ov-resize-crop.webp)
[t-success icon='']结语[/t-success]
该模型是基于Stable Diffusion,大家还是等待完整版释出,到时候可以自己安装进行测试,目前释出的Demo限制还是比较大的,大家可以保持对于该项目的关注。