文章目录[隐藏]
[t-success icon='']AI·快讯[/t-success]
1、Anthropic 发布 AI 模型 Claude Instant 1.2
据 Anthropic 官方消息,Claude Instant 1.2 版本现已正式发布。Anthropic表示,Claude Instant 1.2 版本将拥有更低的成本和更快的响应速度,它可以完成对话、分析、摘要、文档理解等一系列的任务。据悉,Claude Instant 1.2 模型可以处理最高 10 万个 tokens,可以同时处理故事、信件、备忘录等大量文本内容。(来源:IT之家)

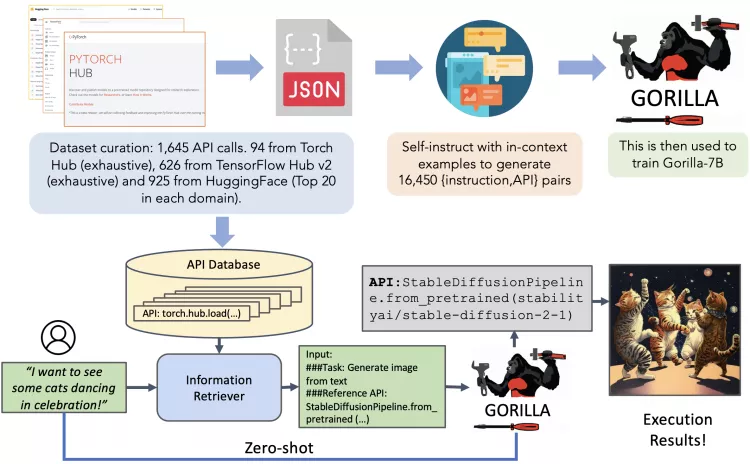
2、微软发布Gorilla LLM,API调用优于 GPT-4
据伯克利大学研究页面显示,微软研究院近日联手加州大学伯克利分校的研究者推出了一款全新的大语言模型Gorilla。研究论文显示,Gorilla在准确性、灵活性等 API 调用方面有着比 GPT-4更出色的表现。论文显示,即使 API 文档发生更改,Gorilla 也可以在调用 API 时保证生成语言的准确性。此外Gorilla还可以为没有训练数据集的 API,生成正确的 API 调用。
3、ChatGPT 自定义指令功能已向所有用户开放,可打造自己的专属聊天机器人
ChatGPT 上个月推出了一个新功能,叫做自定义指令(Custom instructions)。这个功能可以让用户给机器人设置一些特定的规则和条件,来控制机器人的行为和输出。这个功能原本只对 ChatGPT Plus 付费用户开放,但是 ChatGPT 在 8 月 10 日宣布,自定义指令功能正对所有用户免费开放。这意味着任何人都可以使用这个功能来定制自己的聊天机器人,包括免费用户。(来源:IT之家)
4、微软更新服务协议,以防止通过人工智能服务进行逆向工程和数据抓取
微软最近悄悄地更新了其官方服务协议,新规则于 9 月 30 日生效,并有多项新增内容和变化。最大的变化是关于使用微软人工智能服务的新部分,这涉及使用其 Bing Chat 聊天机器人以及 Windows Copilot 和 Microsoft 365 Copilot 服务。(来源:IT之家)
下面是该部分的完整内容:
-
一、逆向工程。不得使用人工智能服务来发现模型、算法和系统的任何底层组件。例如,不能尝试确定和删除模型的权重。
-
二、提取数据。除非明确允许,否则不得使用网络抓取、网络收集或网络数据提取方法从人工智能服务中提取数据。
-
三、AI 服务数据的使用限制。不得使用人工智能服务或人工智能服务中的数据来创建、训练或改进(直接或间接)任何其他人工智能服务。
-
四、使用你的内容。作为提供 AI 服务的一部分,微软将处理和存储你对服务的输入以及服务的输出,以监控和防止滥用或有害的服务使用或输出。
-
五、第三方索赔。你全权负责根据适用法律回应有关你使用 AI 服务的任何第三方索赔(包括但不限于版权侵权或与你使用 AI 服务期间内容输出相关的其他索赔)。
5、报告称 ChatGPT 每日成本为 70 万美元,OpenAI 可能在 2024 年破产
OpenAI 可能正处于潜在的财务危机之中,据 Analytics India Magazine 的一份报告称,该公司可能在 2024 年底破产。报告称,OpenAI 仅运行其人工智能服务 ChatGPT 每天就要花费约 70 万美元(IT之家备注:当前约 506.8 万元人民币)。OpenAI 目前正处于烧钱的状态,尽管该公司试图通过 GPT-3.5 和 GPT-4 来实现盈利,但该目前还没有能够产生足够的收入来实现收支平衡。(来源:IT之家)
6、加州用 AI 监测野火:1032 个摄像头联网扫描森林异常
美国加州林业和消防保护局(Cal Fire)近日公布了一个新的项目,利用人工智能(AI)来检测森林火灾。该项目是与加州大学圣地亚哥分校(UCSD)合作开发的,名为“Alert California AI”,使用 1032 个 360 度旋转摄像头的视频信号,通过 AI 来“识别摄像头画面中的异常情况”。一旦发现潜在的火灾,就会通知紧急服务和其他有关部门,以判断是否需要采取应对措施。(来源:IT之家)
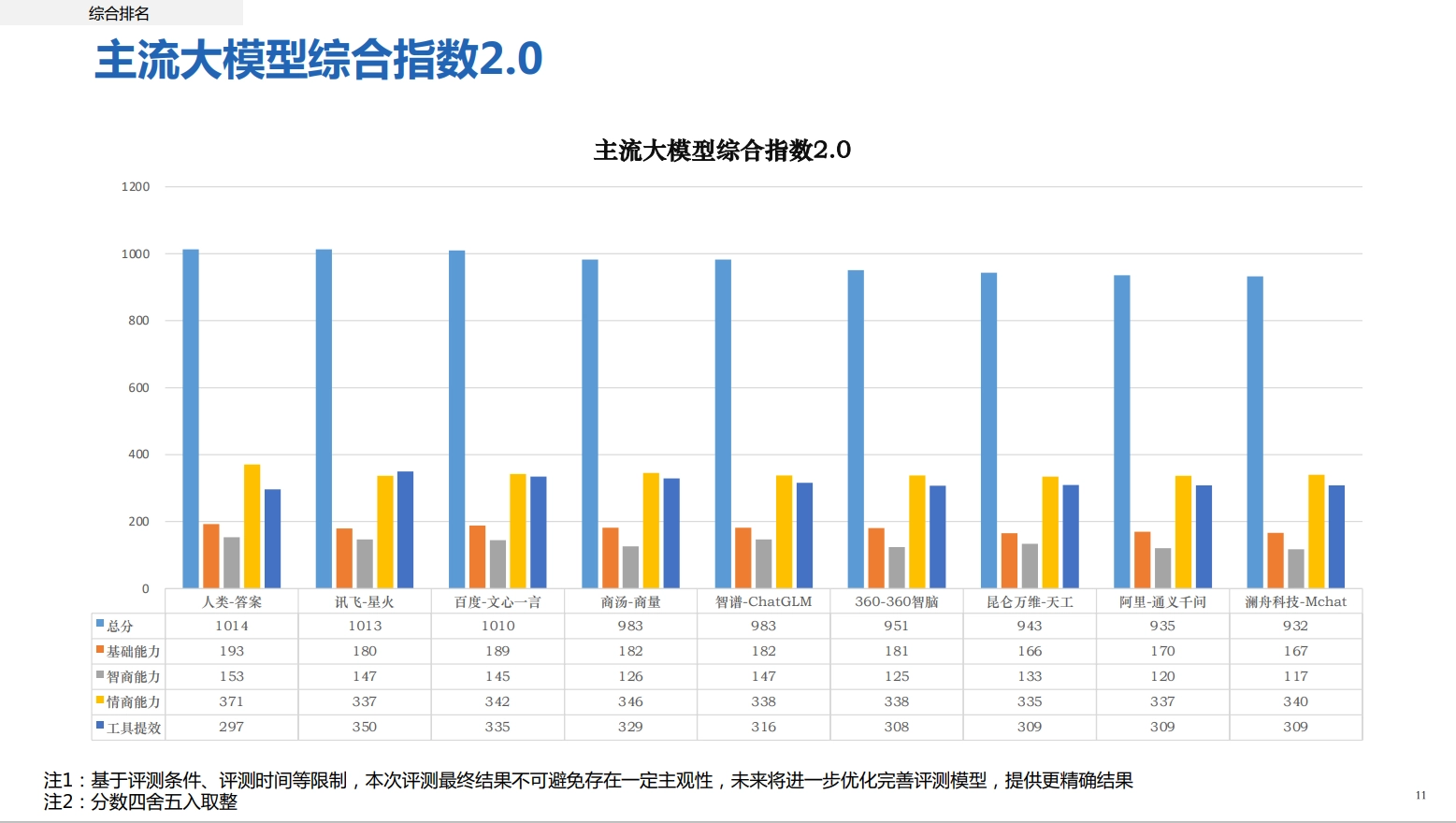
7、新华社研究院发布国产大模型报告,讯飞星火、百度文心一言分列 TOP 2
新华社研究院中国企业发展研究中心昨日发布了《人工智能大模型体验报告 2.0》(下称《报告》)。《报告》指出,当前国产大模型产品已具有显著进步,但与接受过高等教育的人类相比,在智商、情商等方面仍存在一定程度差距。《报告》选取 360 智脑、百度文心一言、澜舟 Mchat、商汤商量、讯飞星火、阿里通义千问、昆仑天工、智谱 ChatGLM 共 8 种大模型产品进行评测,根据基础能力、智商能力、情商能力、工具提取四个维度计算总分。IT之家附总分排名如下:
-
讯飞星火:1013 分
-
百度文心一言:1010 分
-
商汤商量:983 分
-
智谱 ChatGLM:983 分
-
360 智脑:951 分
-
昆仑万维天工:943 分
-
阿里通义千问:935 分
-
澜舟 Mchat:932 分