文章目录[隐藏]
[t-success icon='']AI·快讯[/t-success]
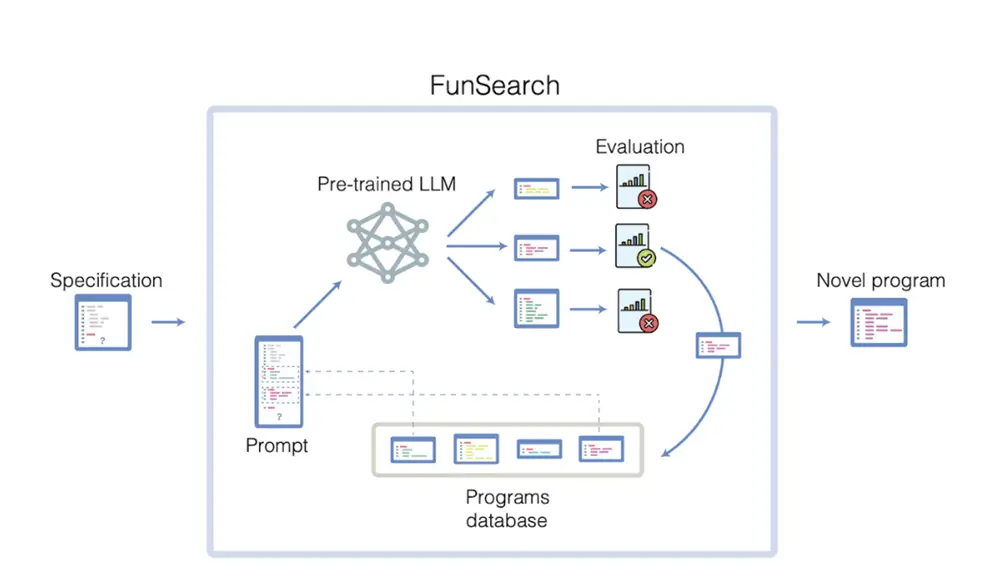
1、可令 AI 模型计算复杂离散数学问题,谷歌 DeepMind 公布“FunSearch”训练法
谷歌 DeepMind 日前公布了一种名为“FunSearch”的模型训练法,号称能够计算包含“上限级问题”、“装箱问题”在内的一系列“涉及数学、计算机科学领域的复杂问题”。据悉,FunSearch 模型训练法主要为 AI 模型引入了一个“评估器(Evaluator)”系统,AI 模型输出一系列“创意解题方法”,“评估器”则负责评判模型输出的解题办法,反复迭代后,就能训练出数学能力更强的 AI 模型。(来源:IT之家)
2、实时生图工具KREA AI全面开放
昨日,此前一直处于内测阶段的实时生图工具KREA AI,即日起开启公测,免费向所有人开放。KREA AI主要提供实时生成和编辑图像、图像分辨率增强、将Logo转换成视觉错觉、创建一些类似中世纪螺旋AI图像等功能。
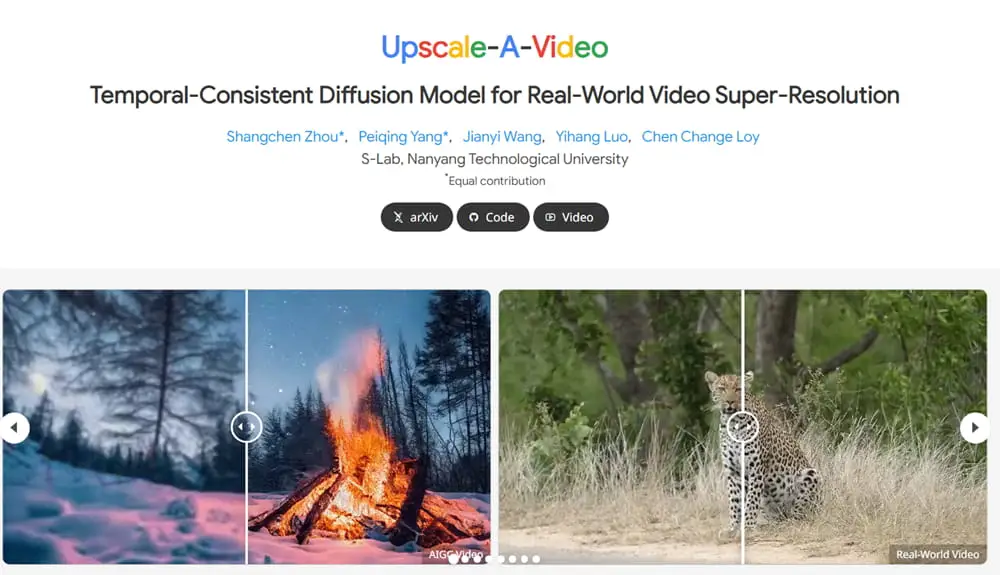
3、南洋理工发布视频升维框架Upscale-A-Video
12月12日,南洋理工大学发布了一种用于视频分辨率升维的、文本引导的潜在扩散框架Upscale-A-Video。该框架通过两个关键机制确保时序一致性:在局部,它将时序层集成到U-Net和VAE-Decoder中,以保持短序列的一致性;在全局,无需训练,它引入了流引导的递归潜传播模块,通过在整个序列中传播和融合潜信息来增强视频的整体稳定性。
4、利用浏览器历史记录训练设备端 AI,Mozilla 公布 MemoryCache 项目
Mozilla 今日推出一项名为 MemoryCache 的项目,号称能够“结合本地个人数据与 Firefox 火狐浏览器存储的数据”,帮助开发者强化设备端 AI 模型,提供“个性化体验”。MemoryCache 项目实际作用就是“允许用户调用 Firefox 火狐浏览器的历史记录,训练设备端 AI”,该项目主要由一组脚本和工具包组成,提供了成套 API,允许开发者利用“privateGPT”等开源模型,训练“属于自己的个性化 AI”。MemoryCache 项目包含了一个 Firefox 火狐浏览器专用插件,能够将用户使用浏览器产生的数据信息存储到本地文件夹中,此外还拥有一个监听文件夹的 Shell 脚本,能够调用 privateGPT 模型的 ingest.py 脚本分析处理用户数据信息,从而起到“训练作用”。(来源)
5、元象开源XVERSE-65B对话版
据元象XVERSE微信公众号昨日发文,元象宣布开源高性能大模型XVERSE-65B-Chat版,无条件免费商用,为开发者构建和部署垂直领域应用提供强大且易用的工具,用户可登录大模型官网或小程序体验。据介绍,在最新公布的SuperCLUE中文通用大模型综合基准中,经1052道多轮简答题和3213道客观选择题测评,在国内外最具代表性的22个大模型中,XVERSE-65B-Chat位居国内开源总分第一,在生成创作、角色扮演、逻辑推理、代码及工具使用方面能力出众。(来源)
官网地址:chat.xverse.cn
6、OpenAI新论文:用小模型监督大模型
今日凌晨,OpenAI发布了超级对齐(Superalignment)团队的第一篇论文,展示了从弱到强的泛化,通过小模型监督大模型。研究表明,可以使用GPT-2级别的模型来激发GPT-4的大部分能力,达到接近GPT-3.5级别的性能。这使得研究人员可以在取得迭代式经验进展的同时,调整未来的超人模型。OpenAI同步开源了代码,并且启动了一项1000万美元的资助计划,支持研究人员广泛开展超人类AI对齐工作。
论文地址:cdn.openai.com/papers/weak-to-strong-generalization.pdf
7、中科闻歌推出雅意2.0国产大模型
12月15日,中科闻歌推出全自主知识产权的雅意2.0国产大模型。据介绍,基于雅意2.0,中科闻歌推出了政务智能和商业智能行业模型体系,面向安全、媒体、金融、舆情、法律、中医等领域构建行业大模型应用。(来源:智东西)
8、网易有道公布虚拟人口语教练“Hi Echo”2.0版本
网易有道公布虚拟人口语教练“Hi Echo”的2.0版本。据介绍,新版本进行了四大能力创新升级:新增口语难度分级;更丰富的虚拟人形象;更多元的对话场景及更具个性化的对话评价报告。