
文章目录[隐藏]
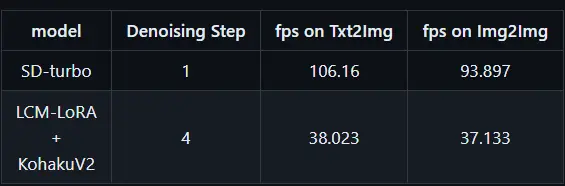
由来自日本和美国大学的开发人员联合打造的StreamDiffusion近期在推特上引发热议,这是一款基于LCM和SDXL Turbo模型的实时生图项目,目前已经上架GitHub正式开源,该项目主要是为了实时图像生成服务而设计的,能够以超过100fps的速度实时生成图片,可以在10ms内生成一张图像,一分钟可以生成超过6000张图像。StreamDiffusion支持多种模型和输出帧率。其中,SD-turbo模型在1步的情况下,t2i每秒帧率达到106,i2i每秒帧率达到93。LCM-LoRA+KohakuV2模型在4步的情况下,t2i每秒帧率为38,i2i每秒帧率为37。这些数据显示了StreamDiffusion在图像生成方面的高效性能。
[t-success icon='']StreamDiffusion[/t-success]
StreamDiffusion号称批处理策略比传统的序列去噪方法快约 1.5 倍,RCFG 技术比传统的无分类引导快达 2.05 倍。在 RTX 4090 显卡上,图生图速度可达 91.07fps,比 Diffusers 团队的 AutoPipline 快 59.56 倍。StreamDiffusion特别适合于需要快速生成图像的应用场景,如实时视频处理、游戏开发、艺术创作等,能够在短时间内生成高质量的图像,为用户提供了强大的创作和编辑能力。
- 实时图像快速生成:适用于需要即时反馈的场景
- 文本到图像转换:适用于创意设计和内容创作
- 交互式绘图体验:可以实时交互以获得所需的图像输出
- 多样化的图像风格:支持生成不同风格和类型的图像
[t-success icon='']如何安装StreamDiffusion?[/t-success]
本人以 Windows11 系统安装为例,要安装StreamDiffusion,还有前提条件:python>=3.8、CUDA>=11.3、ffmpeg 和 git,大家需要先安装这几个软件后才能进行下一步安装,而 CUDA 和ffmpeg会有环境变量的问题,可以参考《「FaceFusion」安装教程》里如何设置环境变量
- Python:https://www.python.org/downloads
- git: https://git-scm.com/download/win
- ffmpeg:https://ffmpeg.org
- CUDA:https://developer.nvidia.com/cuda-toolkit
如果网络环境允许,可使用以下命令行来安装 Python、GIT 和 FFmpeg,请在 命令提示符(CMD)或者 终端 进行下载及安装:
Python winget install -e --id Python.Python.3.10 GIT winget install -e --id Git.Git FFmpeg winget install -e --id Gyan.FFmpeg
1、安装完以上软件后即可正式开始安装 StreamDiffusion,选择安装位置,需要注意的是安装路径不要有中文,使用以下代码下载此项目:
git clone https://github.com/cumulo-autumn/StreamDiffusion.git
👇使用 命令提示符(CMD)或者 终端 进行下载及安装,右键单击即可选择 终端 打开

2、下载完 StreamDiffusion后,需要为 StreamDiffusion安装及激活 python 环境,使用以下命令:
cd StreamDiffusion python -m venv .venv .\.venv\Scripts\activate
3、为此项目安装CUDA支持,选择适合您的系统的版本,11.8或12.1都可以,选择其中一个进行安装
CUDA 11.8
pip3 install torch==2.1.0 torchvision==0.16.0 xformers --index-url https://download.pytorch.org/whl/cu118
CUDA 12.1
pip3 install torch==2.1.0 torchvision==0.16.0 xformers --index-url https://download.pytorch.org/whl/cu121
4、安装StreamDiffusion项目以及TensorRT扩展和pywin32
pip install git+https://github.com/cumulo-autumn/StreamDiffusion.git@main#egg=streamdiffusion[tensorrt] 或者(上面一个是官方推荐,可紧跟官方更新) pip install streamdiffusion[tensorrt]
👇安装TensorRT扩展和pywin32
python -m streamdiffusion.tools.install-tensorrt pip install pywin32 pip install accelerate
[t-success icon='']如何使用StreamDiffusion?[/t-success]
一、官方示例
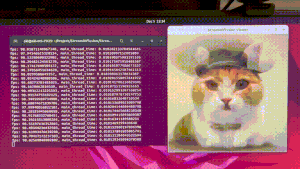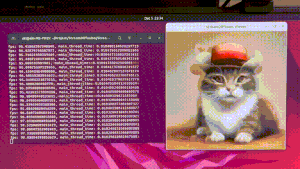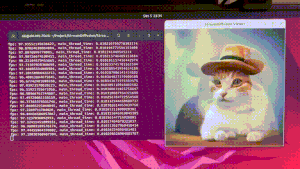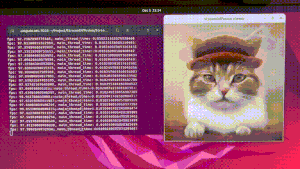
在官方的示例中,给出了多种示例,其中最直观的就是screen,也最能体现此应用的生图能力,其他的如benchmark是测试性能、optimal-performance文生图、img2img图生图、txt2img文生图、vid2vid视频转绘,因为是以LCM和SDXL Turbo为基础,生图质量并不是很高,因此主要给大家讲screen
screen
该脚本仅适用于 Windows,运行脚本时,会出现一个半透明窗口,将其放置在您想要捕获屏幕的位置,然后按 Enter 键确定捕获区域。
首先需要安装依赖,执行以下命令:
cd examples pip install -r screen/requirements.txt
执行以下命令启用此脚本
python screen/main.py
👇在StreamDiffusion文件夹下新建一个文本文档,输入以下命令行,然后将文件名从.txt 改为.bat,之后点击该.bat 文件即可快速启动应用
@echo off call .venv\Scripts\activate cd examples python screen/main.py
来看看效果:
其他例子可在以下页面查看如何执行:也可以直接查看examples文件夹下的README.md文档
地址:https://github.com/cumulo-autumn/StreamDiffusion/tree/main/examples
二、实时文生图演示
想要使用实时文生图,需要先安装Node.js才可以,不过依照官方给出的安装方法,我尝试了几次都没有成功,无法在最后一步启动demo,大家可自行尝试。
Node.js地址:https://nodejs.org/en/download
cd demo/realtime-txt2img pip install -r requirements.txt cd view npm i npm run build cd ../server python main.py
[t-success icon='']使用StreamDiffusion遇到的一些问题[/t-success]
网络问题和模型加载
如果你的网络没办法打开GitHub和Hugging Face,那么此官方示例中的一些示例是无法正常启动的,按照官方给出的方法加载本地模型,会出现报错无法识别的情况。
vid2vid和实时文生图演示
这两个都无法在Windows平台上正常启动,需要自己进行代码修改或者等待官方开发人员修复,也可查看GitHub上Issues其他人给出的解决方法。也可安装第三方修改后的版本。
模型、提示词修改
模型、提示词等都可以在screen文件夹下的main.py里进行修改

此开源项目以及所需软件已上传到国内网盘:
网盘地址:https://www.123pan.com/s/I1oZVv-fMUGA.html 提取码:PZIy