文章目录[隐藏]
[t-success icon='']AI·快讯[/t-success]
1、三星发布Galaxy S24系列手机,搭载谷歌Gemini
三星今日推出Galaxy S24系列手机,引入“Galaxy AI”功能。Galaxy AI大部分新功能都由谷歌Gemini大模型提供支持,包括视频和照片编辑工具、实时语音翻译等。据悉,这是Gemini Pro首次部署在Vertex AI上供客户使用,用于笔记、语音录音和键盘的摘要;手机使用Imagen 2对照片进行生成式编辑,以及Gemini Ultra用于复杂任务,Gemini Nano作为设备上的小型语言模型。三星美国及澳大利亚官方新闻稿角注中提到,Galaxy AI功能将在受支持的三星Galaxy设备上免费提供,直到2025年底。(来源)

2、工信部发布AI产业建设指南草案
工业和信息化部科技司公开征求对《国家人工智能产业综合标准化体系建设指南》(征求意见稿)的意见,公示时间为2024年1月17日至2024年1月31日。指南提出到2026年,共性关键技术和应用开发类计划项目形成标准成果的比例达到60%以上,新制定国家标准和行业标准50项以上,开展标准宣贯和实施推广的企业超过1000家,参与制定国际标准20项以上。(来源)
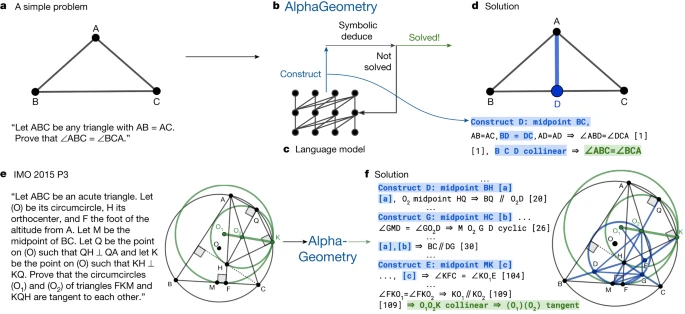
3、谷歌DeepMind数学几何AI 数学模型 AlphaGeometry登上Nature
谷歌 DeepMind 宣布推出 AI 数学模型 AlphaGeometry,能够以接近人类金牌得主的水平解决奥林匹克几何问题,相关论文也于今日登上国际顶刊《自然》(Nature)。为了训练模型,研究团队生成了 1 亿个合成定理及其解决方案,涵盖各种复杂程度的问题,AlphaGeometry 完全基于这些数据进行了从头训练。在针对 30 道奥数几何题的基准测试中,AlphaGeometry 在规定的奥数解题时间内成功解决了 25 道题。相比之下,此前最先进的机器系统仅解决了其中 10 道题,而人类金牌得主的平均解题数量为 25.9 道。( 来源 )
4、智源FlagEval大模型评测榜单1月榜发布
据智源研究院微信公众号发文,今日,FlagEval大语言模型测评榜单1月榜发布,本期新增近期开源的Mistral(MoE模型)、BlueLM、MindSource、SUS-chat-34B、DeepSeek等模型的评测结果,并使用平行测验增强主观评测可靠性。评测显示,Mixtral-8x7B系列模型英文能力远优于中文能力,其基座模型英文能力接近Aquila2-34B;vivo发布的BlueLM系列模型中英文能力较为均衡,整体评测结果在10B以下模型中位于中上游。(来源)
详细测评结果:flageval.baai.ac.cn
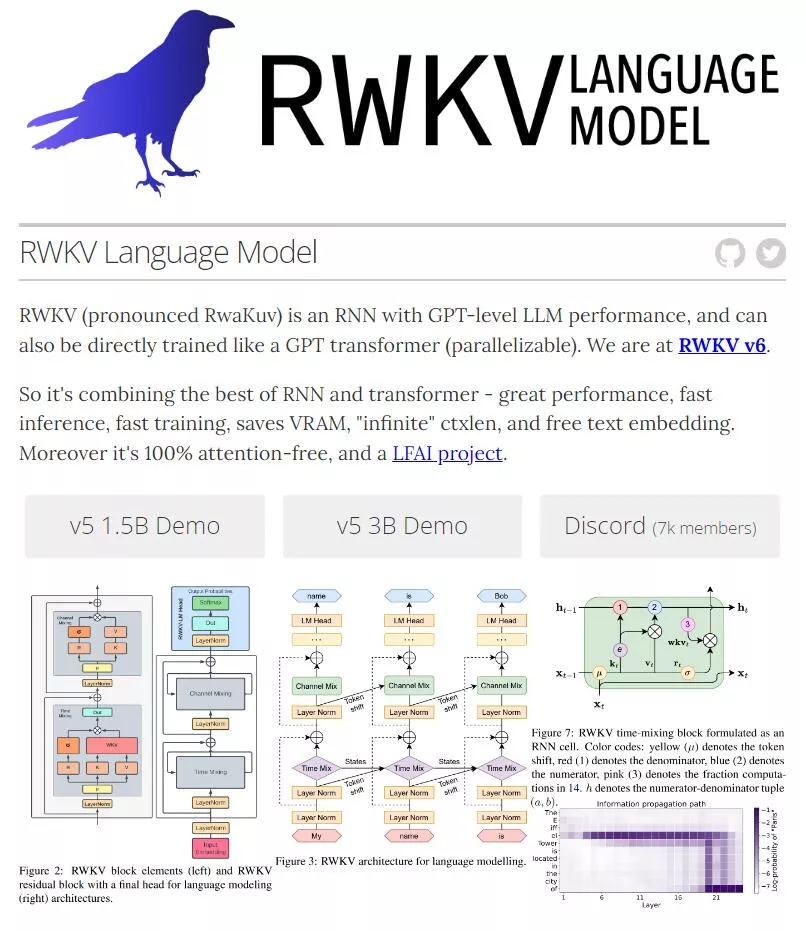
5、RWKV母公司元始智能获种子轮融资
开源大模型RWKV背后的公司元始智能,已于1月16日完成种子轮融资,由奇绩创坛和某匿名投资者投资,目前元始智能已开始继续融第二轮。RWKV是国产开源的首个非Transformer架构的大语言模型,目前已经迭代到第六代RWKV-6。据悉,RWKV-5的15亿和30亿参数版本已发布,且70亿参数版本会在今年1月发布,而RWKV-6的15亿和30亿参数版本将在今年2月发布,然后将继续训练70亿和140亿参数版本。
RWKV体验地址:https://www.rwkv.com
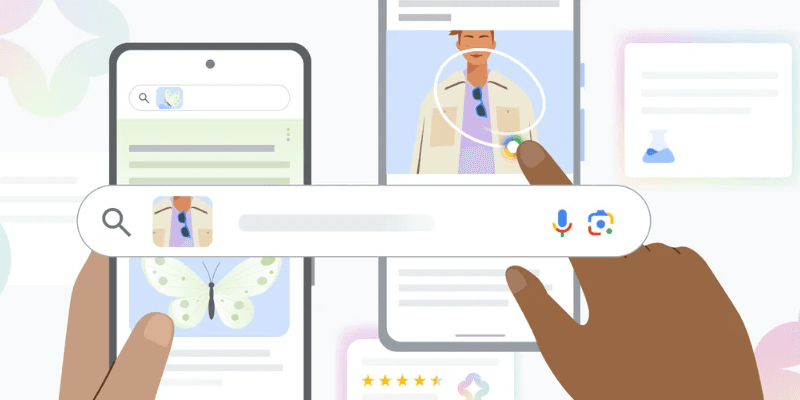
6、谷歌推出画圈搜索及生成式AI多重搜索功能
当地时间1月17日,谷歌推出两项新的搜索功能:画圈搜索(Circle to Search)和AI驱动的多重搜索(Multisearch)。画圈搜索可以使用户无需切换应用程序,使用画圈、涂鸦、点击等简单的交互方式获取更多信息。AI驱动的多重搜索允许用户在上传照片或屏幕截图时,不仅获得视觉匹配结果,还能获得AI提供的智能见解,如用户可以上传一个棋盘游戏的照片,并追问这是什么游戏、该怎么玩等。(来源)

7、亚马逊App测试AI问答功能
亚马逊正在其iOS和安卓移动应用程序中测试一项新的AI功能,该功能可以让客户询问有关产品的具体问题,如帮助准确计算出新架子的尺寸、确定电池的使用寿命,甚至写一首关于雪地靴的圣诞颂歌。亚马逊发言人透露该功能仍在测试中,它不能进行与产品无关的对话或回答问题。(来源)

8、苹果发布自回归视觉模型AIM
来自苹果的团队昨日在arXiv上发表论文,提出一组使用自回归生成目标进行预训练的视觉模型AIM,展示了图像特征的自回归预训练具有与文本对应物(即大型语言模型)类似的缩放属性。具体来说,该论文主要有两个发现:模型容量可以轻松地扩展到数十亿个参数;AIM有效地利用了大量未经筛选的图像数据集。
GitHub地址:https://github.com/apple/ml-aim
9、新型注意力机制Lightning Attention-2发布
OpenNLPLab团队于1月16日在arXiv上发表论文,提出并开源了Lightning Attention-2,这是一种能够实现线性注意力的理论计算优势的线性注意力实现。为了实现这一点,团队利用了Tiling思想,分别处理线性注意力计算中的内部块和间隔块组件。无论输入序列长度如何,Lightning Attention-2都保持一致的训练和推断速度,并且比其他注意力机制快得多。