文章目录[隐藏]
检索增强生成(RAG)是一种关键技术,通过将外部知识融入大语言模型(LLM)的输出来增强其能力。RAG 方法使 LLM 能够从外部来源(如网络数据库、科学文献或特定领域的语料库)获取额外信息,从而在知识密集型任务中表现出更高的性能。然而,RAG 系统在整合检索到的信息与内部知识时常常遇到困难,导致潜在的冲突和模型输出的可靠性下降。
RAG 的挑战
- 不完美检索:
- 不相关、过时或恶意信息:RAG 系统在检索外部数据时,可能会引入不相关、过时或恶意的信息。
- 不一致和错误输出:研究表明,高达70%的检索段落不直接包含正确答案,导致带有 RAG 增强的 LLM 性能下降。
- 知识冲突:
- 内部与外部知识的矛盾:19.2%的实例显示了内部和外部来源之间的知识冲突,其中47.4%的冲突仅通过内部知识正确解决。
Astute RAG 的解决方案
为了解决上述问题,来自 Google Cloud AI Research 和南加州大学的研究人员开发了 Astute RAG,这是一种创新的 RAG 方法,通过自适应框架动态调整内部和外部知识的利用方式,有效管理和缓解知识冲突。Astute RAG的主要功能是帮助这些大型语言模型更好地处理搜索到的信息,确保它们能够给出更准确、更可靠的答案。
Astute RAG就像是给大型语言模型配备了一个智能的过滤器,帮助它们在信息的海洋中筛选出最有价值的知识,以提供给用户最准确的答案。比如,你问一个大型语言模型:“每天吃一块石头对身体有好处吗?”如果模型搜索到的信息是一些讽刺新闻,说每天吃一块石头是必须的,那么模型可能会错误地告诉你这是真的。但实际情况是,吃石头对身体是有害的。
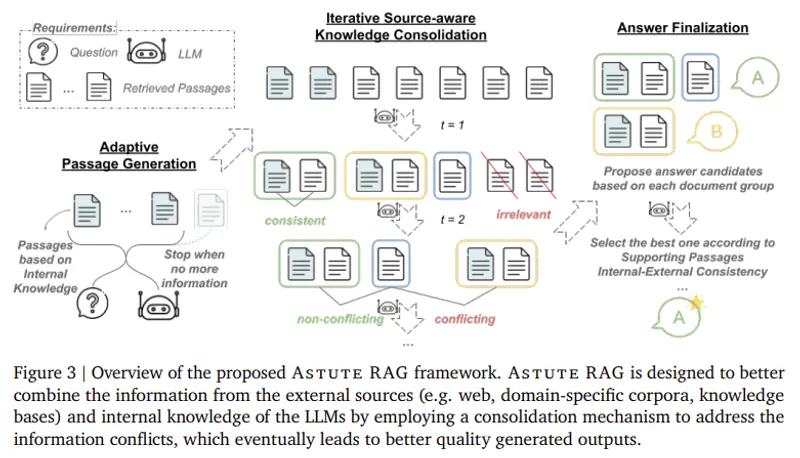
主要特点
- 自适应信息提取:Astute RAG能够从模型内部的知识库中提取关键信息,以补充或纠正外部搜索结果。
- 迭代知识整合:它能够将内部知识和外部搜索结果进行比较和整合,解决它们之间的冲突。
- 信息可靠性评估:Astute RAG会评估不同信息的可靠性,并根据最可靠的信息来确定最终答案。
Astute RAG 的工作原理
- 内部知识提取:
- Astute RAG 首先从 LLM 的内部知识中提取信息,作为外部数据的补充来源。
- 源感知整合:
- Astute RAG 将内部知识与检索段落进行比较,执行源感知整合。这个过程通过迭代优化信息源来识别和解决知识冲突。
- 可靠性评估:
- 最终响应基于一致数据的可靠性确定,确保输出不受错误或误导性信息的影响。
实验结果
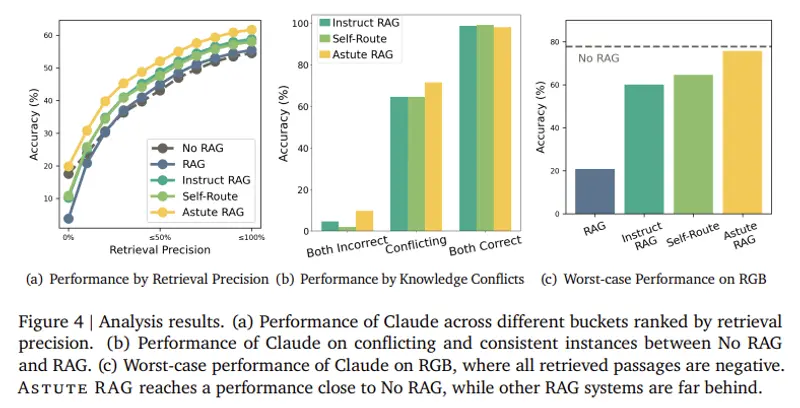
- 总体准确性提升:Astute RAG 在 TriviaQA、BioASQ 和 PopQA 等多样化数据集中的表现优于传统 RAG 系统,总体准确性平均提高了6.85%。
- 最坏情况下的鲁棒性:即使所有检索段落都是无用或误导性的,Astute RAG 仍能保持高性能,接近仅使用内部模型知识的情况。
- 具体数据集表现:
- TriviaQA:经过三次整合迭代后,准确率达到84.45%。
- BioASQ:准确率达到62.24%,超过表现最好的基线 RAG 方法。
关键要点总结
- 不完美检索作为瓶颈:研究确定不完美检索是现有 RAG 系统失败的重要原因,70%的检索段落不包含直接答案。
- 知识冲突:19.2%的实例显示了内部和外部来源之间的知识冲突,其中47.4%的冲突仅通过内部知识正确解决。
- 在各种数据集中的性能:Astute RAG 在多个数据集上表现出色,尤其在 TriviaQA 和 BioASQ 上。
- 在最坏情况下的鲁棒性:即使面对完全不可靠的外部数据,Astute RAG 仍能保持高性能。
- 迭代知识整合:通过多次迭代优化信息,Astute RAG 成功过滤出不相关或有害数据,确保 LLM 生成可靠和准确的响应。
结论
Astute RAG 通过引入自适应框架有效整合内部和外部信息,解决了检索增强生成中的关键知识冲突挑战。这种方法不仅减轻了不完美检索的负面影响,还增强了 LLM 在实际应用中的鲁棒性和可靠性。实验结果表明,Astute RAG 是解决现有 RAG 系统局限性的有效解决方案,特别是在外部来源不可靠的挑战性场景中。