文章目录[隐藏]
机器学习(ML)模型在各种编码任务中显示出有希望的结果,但在有效基准测试AI代理在ML工程中的能力方面仍存在差距。现有的编码基准主要评估孤立的编码技能,而没有全面衡量执行复杂ML任务的能力,如数据准备、模型训练和调试。为了解决这一差距,OpenAI研究人员开发了MLE-bench,这是一个全面的基准,评估AI代理在受现实场景启发的广泛ML工程挑战中的表现。
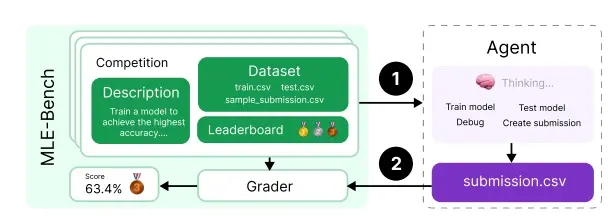
MLE-bench的介绍
1. 目标 MLE-bench旨在评估AI代理在端到端机器学习工程中的表现。它涵盖了一系列实际的工程挑战,包括数据预处理、模型训练、运行实验和提交结果进行评估。
2. 数据来源 MLE-bench由从Kaggle收集的75个ML工程竞赛构建而成。这些竞赛涵盖了自然语言处理、计算机视觉和信号处理等不同领域。每个竞赛都经过精心策划,以评估关键的ML技能。
3. 结构和细节
- 竞赛任务:每个任务代表一个实际的工程挑战,包括问题描述、数据集、本地评估工具和评分代码。
- 数据集划分:每个竞赛的数据集被分为训练集和测试集,通常重新设计以避免任何重叠或污染问题。
- 评分机制:提交的评分是根据竞赛排行榜上的人类尝试进行的,代理根据其相对于人类基准的表现获得奖牌(铜牌、银牌、金牌)。
- 评估指标:评分机制依赖于标准评估指标,如接收者操作特征曲线下的面积(AUROC)、均方误差和其他领域特定的损失函数。
4. 主要功能和特点
- 多样化任务:MLE-bench包含了75个不同的Kaggle比赛,涵盖了自然语言处理、计算机视觉和信号处理等多个领域。
- 人类基线比较:通过使用Kaggle公开的排行榜作为人类基线,可以直接比较AI代理和人类的表现。
- 开源:MLE-bench的代码是开源的,方便研究人员使用和进一步开发。
5.工作原理
MLE-bench的工作原理可以分为以下几个步骤:
- 数据集准备:从Kaggle比赛中选取任务,并为每个任务准备数据集和评分代码。
- 代理评估:使用不同的AI代理(如不同的大型语言模型)来尝试解决这些任务。
- 结果比较:将AI代理的提交结果与人类排行榜上的成绩进行比较,以此来评估AI代理的性能。

实验结果和性能分析
1. 测试设置
- AI代理:OpenAI的o1-preview模型与AIDE脚手架结合。
- 评估方法:在75个Kaggle竞赛任务上进行测试,每次测试允许多次尝试。
2. 性能结果
- 初始结果:o1-preview模型与AIDE脚手架结合在16.9%的竞赛中达到了与Kaggle铜牌相当的结果。
- 多次尝试的影响:性能在多次尝试后显著提高,表明代理在从初始错误中恢复和优化解决方案方面的能力。
- 资源影响:增加计算时间和硬件资源显著提高了代理的性能。例如,GPT-4o的性能从8.7%(给予24小时)提高到11.8%(给予100小时每竞赛)。
- 尝试次数的影响:增加尝试次数(pass@k)对成功率有显著影响,pass@6的性能几乎是pass@1的两倍。
3. 关键发现
- 迭代优化:代理在能够迭代其解决方案时通常表现更好,突显了多次传递的重要性。
- 资源分配:资源分配对代理性能有显著影响,特别是在需要广泛模型训练和超参数调整的竞赛中。
- 局限性:尽管代理在某些任务上表现出色,但在处理复杂数据集和从初始错误中恢复方面仍存在困难。
结论和未来方向
1. 重要性 MLE-bench代表了评估AI代理ML工程能力的重要一步,专注于整体、端到端性能指标,而不是孤立的编码技能。该基准提供了一个强大的框架,用于评估ML工程的各个方面,包括数据预处理、模型训练、超参数调整和调试。
2. 未来研究
- 合作与开源:通过开源MLE-bench,OpenAI希望鼓励合作,允许研究人员和开发者贡献新任务、改进现有基准并探索创新的脚手架技术。
- 关键领域:MLE-bench作为一个有价值的工具,用于识别AI代理需要进一步发展的关键领域,为未来在增强AI驱动的ML工程能力方面的研究努力提供了明确的方向。
3. 长期目标
- 促进进展:这种合作努力有望加速该领域的进展,最终为更安全和更可靠的高级AI系统的部署做出贡献。
- 实际应用:通过不断改进和优化,MLE-bench将帮助开发出更强大的AI代理,能够自主执行复杂的ML工程任务,推动实际应用的发展。
总之,MLE-bench为评估和提升AI代理在机器学习工程中的能力提供了一个全面而现实的框架,为未来的研究和应用奠定了坚实的基础。