文章目录[隐藏]
全模态语言模型(OLMs)是AI中一个快速发展的领域,能够理解和推理多种数据类型,包括文本、音频、视频和图像。这些模型旨在通过同时处理多样化的输入来模拟人类般的理解,使其在复杂的现实世界应用中非常有用。该领域的研究旨在创建能够无缝整合这些不同数据类型并在不同任务中生成准确响应的AI系统。这代表了AI系统与世界互动方式的飞跃,使其更符合人类交流,其中信息很少局限于一种模态。
持续挑战
开发OLMs的一个持续挑战是它们在面对多模态输入时的不一致表现。例如,在现实世界情况下,模型可能需要分析包含文本、图像和音频的数据以完成任务。然而,许多当前模型在有效结合这些输入时遇到困难。主要问题在于这些系统无法完全跨模态推理,导致其输出存在差异。在许多情况下,模型在以不同格式呈现相同信息时(例如,以图像显示的数学问题与以音频形式大声朗读)产生不同的响应。
现有基准测试的局限性
现有的OLMs基准测试通常局限于两种模态的简单组合,如文本和图像或视频和文本。这些评估必须评估现实世界应用所需的全范围能力,通常涉及更复杂的场景。例如,许多当前模型在处理双模态任务时表现良好,但在要求跨三种或更多模态组合进行推理时,它们需要显著改进,例如整合视频、文本和音频以得出解决方案。这种局限性在评估这些模型真正理解和推理多种数据类型的能力方面造成了差距。

Omni×R:新的评估框架
为了解决这些挑战,来自谷歌DeepMind、谷歌和马里兰大学的研究人员开发了Omni×R,这是一个新的评估框架,旨在严格测试OLMs的推理能力。该框架通过引入更复杂的多模态挑战而与众不同。Omni×R使用必须整合多种数据形式的场景来评估模型,例如回答需要同时跨文本、图像和音频进行推理的问题。
该框架包括两个数据集:
- Omni×Rsynth:一个通过自动将文本转换为其他模态创建的合成数据集。
- Omni×Rreal:一个从YouTube等来源精心策划的现实世界数据集。
这些数据集提供了比以前基准测试更全面和更具挑战性的测试环境。
数据集详情
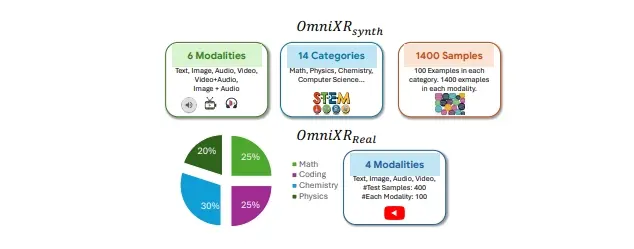
- Omni×Rsynth:框架的合成部分,旨在通过将文本转换为图像、视频和音频来推动模型的极限。例如,研究团队开发了Omnify!,一个将文本翻译成多种模态的工具,创建了一个包含1,400个样本的数据集,分布在六个类别中,包括数学、物理、化学和计算机科学。每个类别包括六个模态(文本、图像、视频、音频、视频+音频和图像+音频)的100个示例,挑战模型处理复杂输入组合。研究人员使用此数据集测试了各种OLMs,包括Gemini 1.5 Pro和GPT-4o。这些测试的结果显示,当前模型在要求整合来自不同模态的信息时,性能显著下降。
- Omni×Rreal:现实世界数据集,包括100个涵盖数学和科学等主题的视频,其中问题以不同模态呈现。例如,视频可能以视觉形式显示数学问题,而答案选项则以音频形式大声朗读,要求模型整合视觉和听觉信息以解决问题。现实世界场景进一步突显了模型在跨模态推理方面的困难,结果显示的不一致性与合成数据集中观察到的一致。值得注意的是,在处理文本输入时表现良好的模型在处理视频或音频输入时准确性急剧下降。
实验结果
研究团队进行了广泛的实验,并发现了几项关键见解:
- Gemini 1.5 Pro:在大多数模态中表现良好,文本推理准确率为77.5%。然而,其在视频和图像输入上的性能分别下降到57.3%和36.3%。
- GPT-4o:在处理文本和图像任务时表现更好,但在处理视频时遇到困难,在整合文本和视频数据时性能下降了20%。
这些结果突显了在多种模态中实现一致性能的挑战,这是推进OLM能力的关键步骤。
关键观察
Omni×R基准测试的结果揭示了不同OLMs之间的几个显著趋势:
- 文本任务表现良好:像Gemini和GPT-4o这样的模型在处理文本时表现良好,但在多模态推理方面遇到困难。
- 显著的性能差距:在处理基于文本的输入和复杂的多模态任务之间存在显著的性能差距,尤其是在涉及视频或音频时。
- 模型大小和灵活性的权衡:较大的模型通常在跨模态中表现更好,但较小的模型有时在特定任务中表现更优。
合成数据集的价值
合成数据集(Omni×Rsynth)准确模拟了现实世界的挑战,使其成为未来模型开发的有价值工具。通过这些数据集,研究人员可以更好地理解和改进模型在处理复杂多模态输入时的表现。
总结
研究团队引入的Omni×R框架在评估和改进OLMs的推理能力方面迈出了关键一步。通过严格测试模型在不同模态中的表现,该研究揭示了必须解决的显著挑战,以开发能够进行人类般多模态推理的AI系统。在涉及视频和音频整合的任务中观察到的性能下降突显了跨模态推理的复杂性,并指出了需要更先进的训练技术和模型来处理现实世界的多模态数据复杂性。