
文章目录[隐藏]
Zyphra 是一家专注于开发多模态代理系统的公司,最近发布了 Zyda-2,这是一个包含 5 万亿个标记的开源预训练数据集。这一数据集不仅体积庞大,而且经过精心提炼,旨在克服现有数据集的局限性,为组织提供在边缘和消费设备上训练高准确性语言模型的方法。
Zyda-2 的独特之处
- 体积和多样性:Zyda-2 是其前身的五倍大,涵盖了广泛的主题和领域,确保训练竞争性语言模型所需的多样性和质量。
- 精炼和去重:与 Hugging Face 上的许多开放数据集不同,Zyda-2 经过过滤和去重,保留了现有顶级数据集的优势,同时消除了它们的弱点。
- 高效的数据处理:Zyphra 使用 Nvidia 的 NeMo Curator,这是一个 GPU 加速的数据管理库,将数据处理速度提高了 10 倍,总拥有成本降低了 2 倍。
构建过程
今年早些时候,Zyphra 开始构建自定义预训练数据集,以支持高效小型模型的研发。最初的 Zyda 数据集包含 1.3 万亿个标记,于 6 月首次亮相,是多个高质量开放数据集(如 RefinedWeb、Starcoder C4、Pile、Slimpajama、pe2so 和 arXiv)的过滤和去重混合。
Zyda-2 在此基础上进一步改进,加入了 DCLM、FineWeb-Edu 和 Dolma v1.7 的 Common-Crawl 部分的开源标记。这些新增内容提高了数据集的多样性和质量。
技术细节
- 去重和质量过滤:Zyphra 对所有数据集进行了交叉去重,删除了重复的文档,提高了每个标记的质量。随后,使用 NeMo Curator 的质量分类器对 Zyda-1 和 Dolma-CC 进行了基于模型的质量过滤,只保留了“高质量”子集。
- 数据处理速度:使用 Nvidia 的 NeMo Curator 将数据处理时间从三周缩短到两天,大大提高了效率。
性能提升
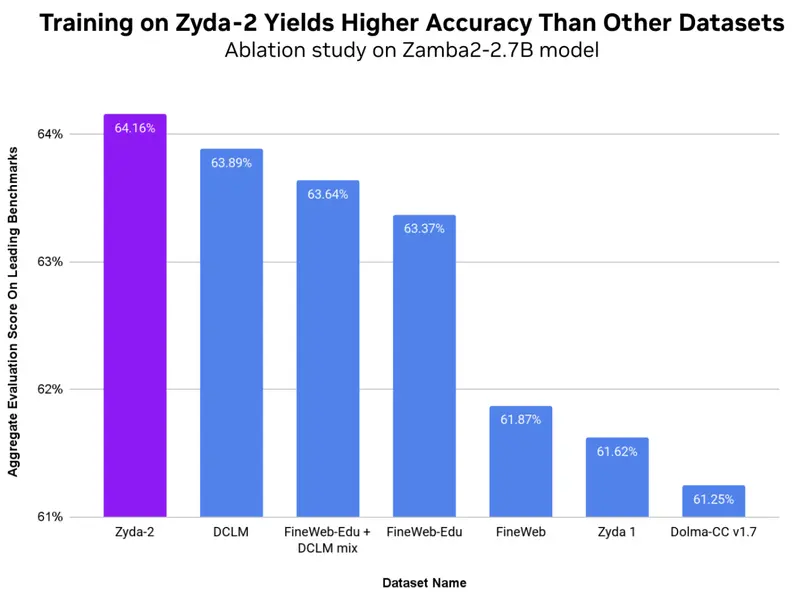
Zyphra 使用 Zyda-2 训练了其 Zamba2 小型语言模型,并发现其性能显著优于使用其他最先进的开源语言建模数据集时的表现。在一项消融研究中,Zamba2-2.7B 在 MMLU、Hellaswag、Piqa、Winogrande、Arc-Easy 和 Arc-Challenge 等领先基准测试中获得了最高的综合评估分数。
未来展望
Zyphra 希望 Zyda-2 能够为更好的小型模型铺平道路,帮助企业在特定的内存和延迟约束下最大化质量和效率,无论是在设备上还是在云部署中。Zyda-2 已经可以通过 Hugging Face 下载,带有 ODC-By 许可证,允许用户根据原始数据源的许可证协议和使用条款在 Zyda-2 上进行训练或构建。