文章目录[隐藏]
大语言模型(LLMs)的最新进展已经重塑了AI的格局,为创建多模态大语言模型(MLLMs)铺平了道路。这些先进的模型扩展了AI的能力,超越了文本,允许理解和生成图像、音频和视频等内容,标志着AI发展的一个重大飞跃。尽管MLLMs取得了显著的进步,但当前的开源解决方案在多模态能力和用户体验质量方面存在许多不足。像GPT-4o这样的新型AI模型展示了其令人印象深刻的多模态能力和交互体验,突显了其在实际应用中的关键作用,但需要一个高性能的开源对应物。
Baichuan-Omni 的介绍
为了解决这些问题,来自百川、西湖大学和浙江大学的研究人员引入了Baichuan-Omni,这是一个可以同时处理音频、图像、视频和文本数据的开放源代码模型。Baichuan-Omni 设计了一个多模态训练方案,以促进高级多模态处理和更好的用户交互。它还为英语和中文等语言提供多语言支持。
这个模型就像一个多才多艺的超级助手,能够同时处理和分析图像、视频、音频和文本等多种类型的数据。这就好比有一个助手,不仅能听懂你说的话(音频),还能看懂你给它的图片和视频(视觉),并且能阅读和理解你给它的文件(文本)。
主要功能和特点:
- 多模态处理能力: Baichuan-Omni能够处理多种类型的数据,包括图像、视频、音频和文本,这使得它在理解和生成内容方面非常强大。
- 开放源代码: 这是一个开源模型,意味着任何人都可以访问它的代码,进行修改或者在自己的项目中使用。
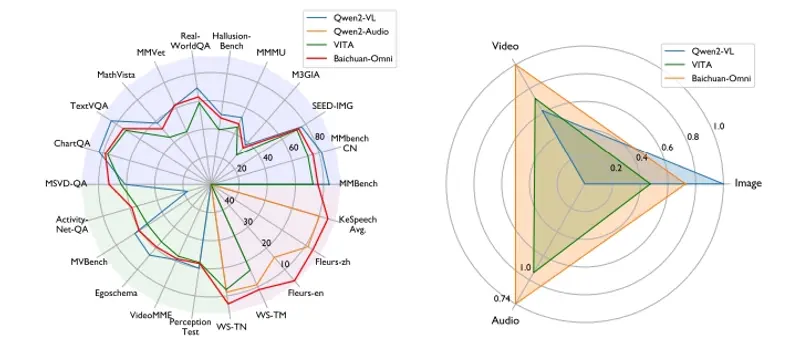
- 高性能: 论文中提到,Baichuan-Omni在多个多模态和单模态的基准测试中表现出色,尤其是在中文的测试中。
- 多任务微调: 模型通过多任务微调来提高其在各种任务中的表现,这些任务包括图像理解、视频理解、音频理解和文本处理。
训练框架
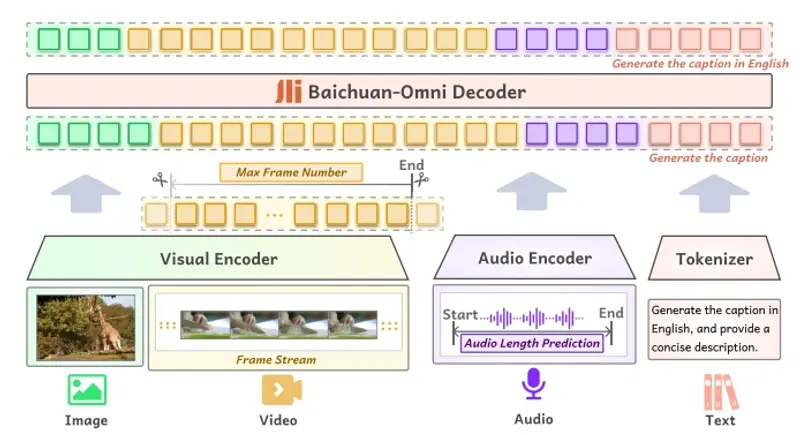
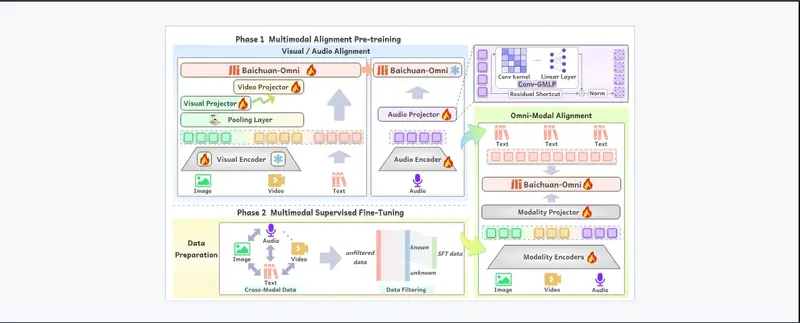
Baichuan-Omni的工作原理可以分成几个阶段。首先,它通过多模态预训练来学习如何处理不同类型的数据。然后,通过多任务微调来进一步提高其在特定任务上的表现。在处理数据时,模型会使用特定的编码器来提取图像、视频和音频的特征,并将这些特征转换成模型能够理解的格式。最后,模型会结合这些特征和文本信息来生成响应或者完成特定的任务。
- 多模态训练数据构建:
- 图像数据:使用标题、OCR和图表等数据。
- 视频数据:来自分类和运动识别等任务,其中一些标题由GPT-4生成。
- 音频数据:从各种环境、口音和语言中收集,通过语音识别和质量检查进行处理,细化多个转录以提高准确性。
- 文本数据:来自网站、博客和书籍等来源,注重多样性和质量。
- 跨模态数据:使用文本到语音技术来增强模型理解不同类型数据之间交互的能力。
- 多模态对齐预训练:
- 图像语言分支:模型分阶段训练以改进图像文本任务,如标题和视觉问答(VQA)。
- 视频语言分支:通过将视频帧与文本对齐来建立在此基础上。
- 音频语言分支:使用先进技术在将音频映射到文本时保留音频信息。
- Omni-Alignment:结合图像、视频和音频数据,进行全面的多模态学习。
- 多模态监督微调:
- 任务多样性:模型在超过200个任务上进行训练,以提高其遵循涉及多种类型信息和数据的详细指令的能力。
性能评估
- 自动语音识别(ASR):Baichuan-Omni 在汉语转录和语音到文本翻译等领域优于其他领先模型。
- 视频理解:研究强调了视觉编码器分辨率和帧数在视频处理中的重要性,指出使用自适应分辨率时显著改进。
- 数学推理和视频描述:训练数据扩展到涵盖更广泛的任务,包括数学推理和视频描述等。
多语言支持
Baichuan-Omni 提供多语言支持,能够处理英语、中文等多种语言的数据,使其在国际化的应用场景中更具优势。