文章目录[隐藏]
Zyphra发布了Zamba2-7B,这是一款先进的紧凑型语言模型,性能超过了诸如Mistral-7B、Gemma-7B和Llama3-8B等领先的7B模型。它的推理效率极高,比Llama3-8B等模型快25%达到首个令牌的时间,每秒令牌处理量提高了20%,并且显著降低了内存使用。Zamba2-7B是运行在设备上和消费者GPU上的领先模型,也是许多需要强大但紧凑和高效模型的企业应用程序的领先模型,用于自然语言任务。
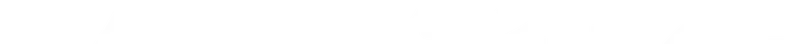
Zamba2-7B亮点
- Zamba2-7B在评估基准性能和推理效率方面达到了SOTA,与当前领先的7B模型如Mistral-7B、Gemma-7B和Llama3-8B相比,具有优越的推理效率。
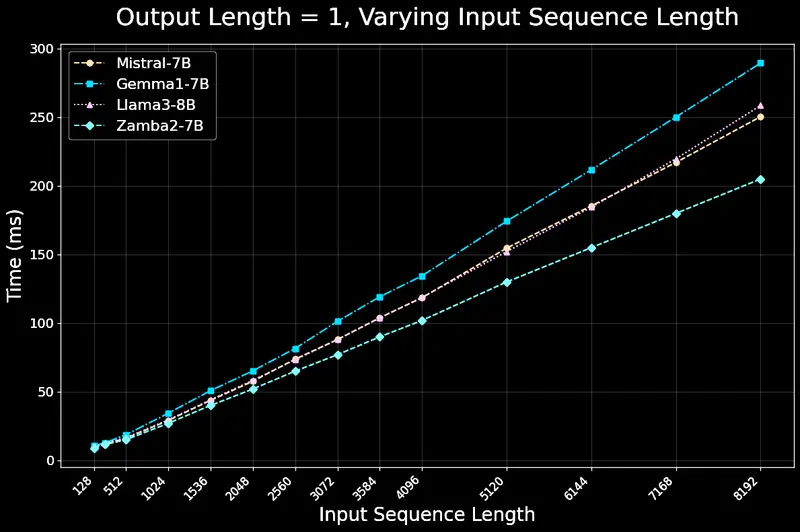
- Zamba2-7B的推理效率极高,首次生成令牌的时间缩短了25%,每秒令牌数提高了20%,与Llama3-8B等模型相比,内存使用量显著减少。
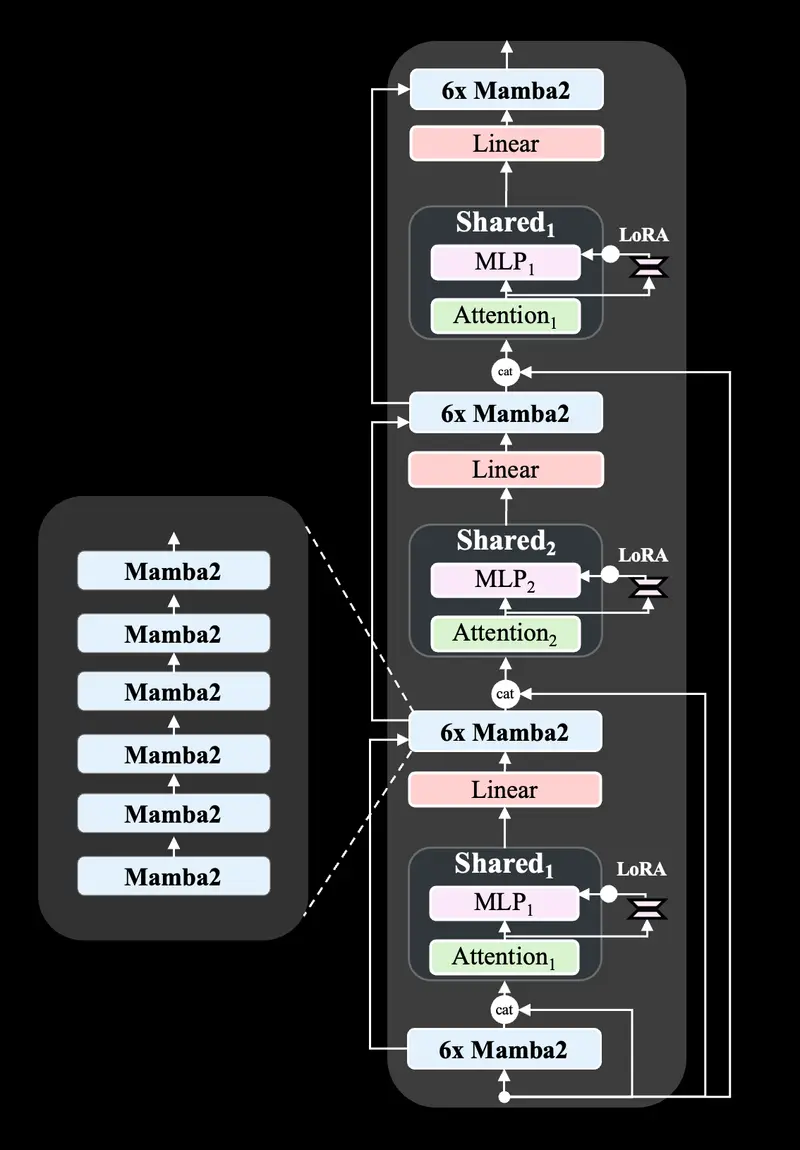
- Zamba1-7B的架构改进:
- Mamba1块已被Mamba2块取代
- 我们不是使用单一的共享注意力块,而是使用两个共享注意力块,这些块在整个网络中以ABAB模式交错排列。
- 我们对每个共享MLP块应用LoRA投影仪,这使得网络能够在每次调用共享层时在深度上专门化MLP。
- 我们开放源代码模型权重(Apache 2.0)
模型质量
Zamba2在标准语言建模评估集上表现出色,尤其是在其延迟和生成速度方面。在小型语言模型(≤8B)中,我们在质量和性能方面领先。
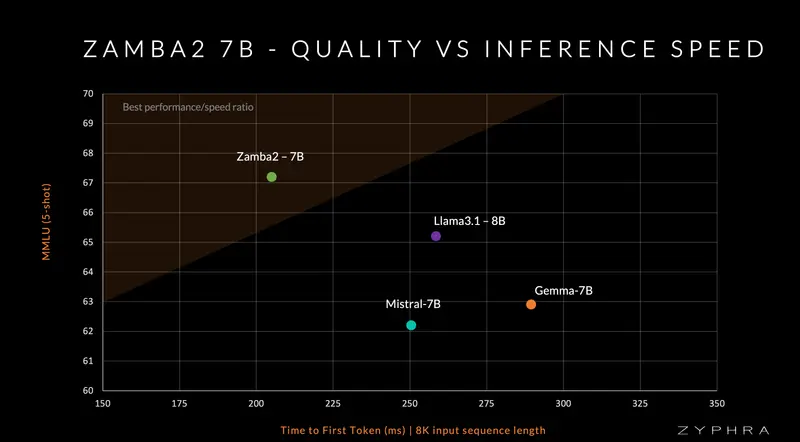
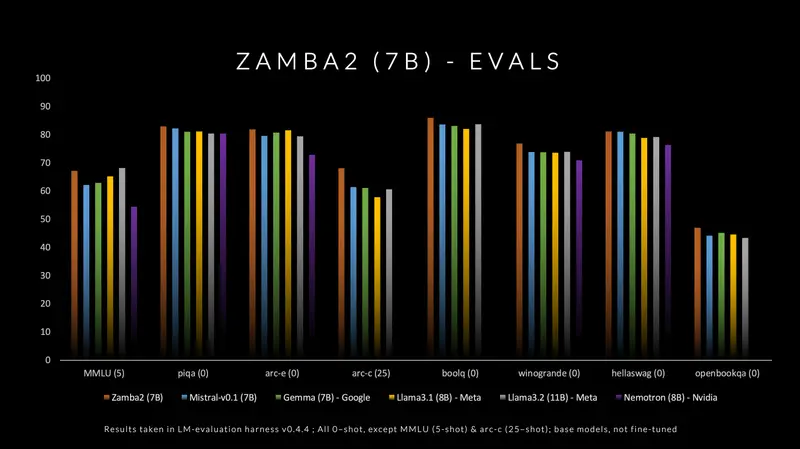
我们的模型优于现有最先进模型的原因如下:
- 我们新颖的共享注意力架构允许将更多参数分配给Mamba2主干。反过来,共享变换器块保留了注意力计算的丰富跨序列依赖性。
- 我们的3万亿令牌预训练数据集,由Zyda和公开可用的数据集组合而成,经过积极过滤和去重,在消融实验中达到了现有顶级开源预训练数据集的最先进质量。
- 我们有一个单独的“退火”预训练阶段,在1000亿高质量令牌上快速衰减学习率。我们的退火集经过精心策划,质量高,来自各种高质量来源。
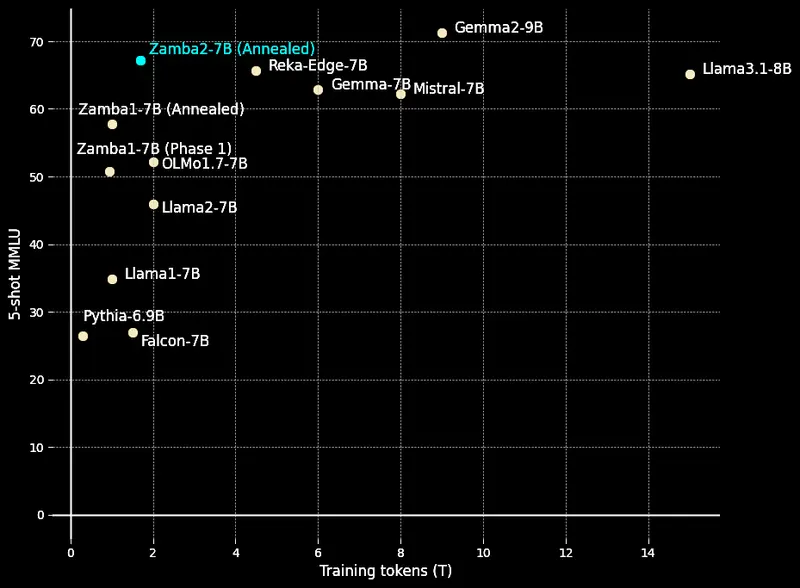
由于我们预训练和退火数据集的卓越质量,Zamba2-7B在每个训练令牌的基础上表现出色,舒适地位于竞争对手模型所绘制的曲线上方。
Zamba2-7B利用并扩展了我们原始的Zamba混合SSM-注意力架构。Zamba架构的核心由Mamba层与一个或多个共享注意力层交错组成(Zamba1中有一个共享注意力,Zamba2中有两个)。这种注意力具有共享权重,以最小化模型的参数成本。我们发现,将输入的原始模型嵌入连接到这个注意力块可以提高性能,这可能是因为更好地维护了深度上的信息。Zamba2架构还对共享MLP应用LoRA投影矩阵,以在每个块中获得一些额外的表达能力,并允许每个共享块在保持额外参数开销小的同时稍微专门化到其独特的位置。
Zamba2-7B推理性能
我们实现了最先进的推理效率,包括延迟、吞吐量和内存使用,因为:
- Mamba2块非常高效,并且具有大约4倍于等参数变换器块的吞吐量。
- Mamba块只有小的隐藏状态需要存储,不需要KV缓存,所以我们只需要为共享注意力块的调用存储KV状态。 3.我们选择的模型大小非常适合现代硬件的并行化(即GPU上的多个流多处理器,CPU上的多个核心)。
Zamba2-7B在128个H100 GPU上使用我们基于Megatron-LM开发的内部训练框架进行了大约50天的训练。因此,Zamba2-7B表明,在7B规模上,前沿仍然是可及且可超越的,只需一个小团队和适度的预算。

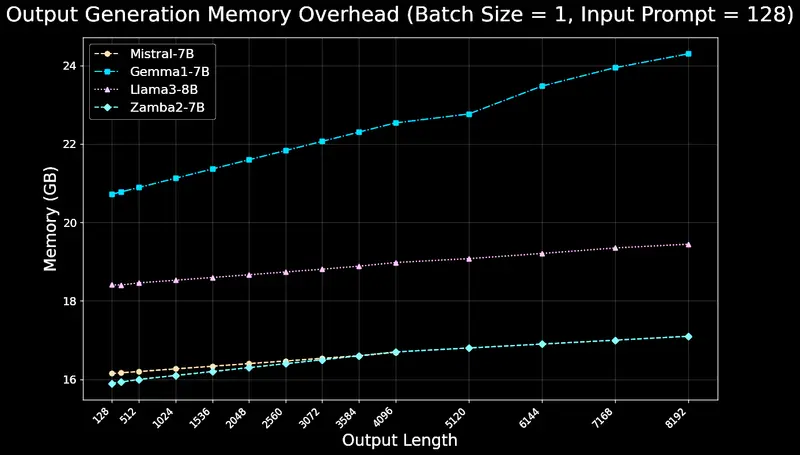
Zamba2-7B以开源许可证发布,允许研究人员、开发人员和企业利用其能力。我们邀请更广泛的AI社区探索Zamba的独特架构,并继续推动高效基础模型的边界。
- Instruct Zamba2-7B: https://huggingface.co/Zyphra/Zamba2-7B-Instruct
- Base Zamba2-7B: https://huggingface.co/Zyphra/Zamba2-7B
- Pure PyTorch: https://github.com/Zyphra/Zamba2