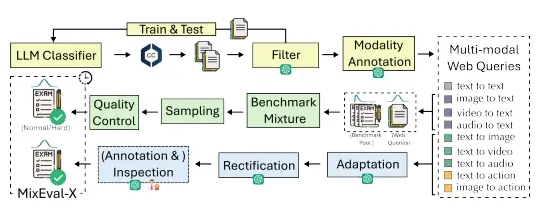
新加坡国立大学、南洋理工大学、北京大学、卡内基梅隆大学和滑铁卢大学的研究人员推出评估框架MixEval-X,它是用来测试和比较不同AI模型在处理多种输入和输出模式时的性能。这些模式包括文本、图像、视频、音频等,可以想象成一个多才多艺的AI裁判,它不仅能看懂文字(文本),还能听懂声音(音频),看懂画面(视频和图像),并且能够根据这些信息做出决策或生成新的相关内容。
- 项目主页:https://mixeval-x.github.io
- GitHub:https://github.com/Psycoy/MixEval-X
- 数据:https://huggingface.co/datasets/MixEval/MixEval-X
例如,你是一名电影制作人,你想要一个AI模型来根据剧本生成预告片。使用MixEval-X,你可以评估不同AI模型将剧本文本转换为视频的能力,看看哪个模型生成的预告片最能吸引观众。这就需要模型不仅要理解文本内容,还要能够创作出视觉上吸引人的视频,MixEval-X提供了一个标准化的评估方法来比较不同模型的性能。

主要功能和特点:
- 多模态评估: MixEval-X能够评估AI模型在多种输入(如图像、视频、音频)和输出(如文本、图像、视频、音频)模式下的表现。
- 真实世界数据混合: 它使用了来自现实世界的数据混合,这意味着评估任务更加贴近实际应用场景。
- 减少偏见: 通过匹配网络挖掘的查询与类似的基准任务,减少了评估过程中的查询偏见、评分偏见和泛化偏见。
- 动态基准测试: 通过自动化的数据更新流程,保持基准测试的动态性,减少了模型对评估数据的过拟合。
工作原理: MixEval-X的工作原理基于几个关键步骤:
- 网络查询检测: 首先,它会从网络上检测和收集真实用户查询,这些查询涵盖了多种输入输出模式。
- 基准混合: 然后,它会从现有的社区基准测试中构建一个大规模的多模态基准池,并从中选择与网络查询最相似的任务,以重现基准分布。
- 质量控制: 接下来,它会进行质量控制,排除错误或极端的样本,确保评估任务的准确性和挑战性。
- 评分机制: 最后,对于有明确答案空间的任务(如多项选择题),使用模型基础的评分器进行评分;对于开放式任务(如图像生成),则可能采用人类评估或基于模型的评分方法。
具体应用场景:
- AI模型开发: 开发者可以使用MixEval-X来测试和优化他们的AI模型,确保模型在处理多种模态数据时的准确性和有效性。
- 教育和培训: 在教育领域,MixEval-X可以用来评估教学AI模型,比如评估一个AI助教在解释概念或回答问题时的表现。
- 内容创作: 在内容创作领域,比如广告或娱乐产业,MixEval-X可以用来评估和改进AI生成创意内容的能力,比如根据文本提示生成视频或音频。