北京大学电子与计算机工程学院、鹏程实验室、Rabbitpre Intelligence、昆仑2050研究中心和Skywork AI 的研究人员推出“多头注意力机制的混合(MoH)”技术,,它被用在像翻译语言、识别图片这样的任务中。这个技术就像有多个脑子同时工作,每个“脑子”(或者说“头”)都关注不同的信息。但是,就像不是每个朋友都擅长所有运动一样,这些“头”并不都是同样重要的。有些“头”可能在处理某些信息时更有效。MoH就是让这些“头”像运动员一样,只参与它们最擅长的任务。这样,整个系统可以更高效地工作,而且不会增加额外的计算负担。
MoH是一种新的架构,将注意力头视为混合专家(MoE)机制中的专家。MoH 有两个显著优势:首先,MoH 使每个令牌能够选择适当的注意力头,从而在不牺牲准确性或增加参数数量的情况下提高推理效率。其次,MoH 用加权求和取代了多头注意力中的标准求和,为注意力机制引入了灵活性,并解锁了额外的性能潜力。在 ViT、DiT 和 LLM 上的广泛实验表明,MoH 仅使用 50%-90% 的注意力头就优于多头注意力。此外,研究团队证明了预训练的多头注意力模型,如 LLaMA3-8B,可以进一步继续微调为我们的 MoH 模型。
值得注意的是,MoH-LLaMA3-8B 在 14 个基准测试中实现了 64.0% 的平均准确率,通过仅使用 75% 的注意力头,比 LLaMA3-8B 高出 2.4%。我们相信,所提出的 MoH 是多头注意力的一个有前途的替代方案,并为开发先进和高效的基于注意力的模型提供了坚实的基础。
主要功能和特点:
- 效率提升:MoH可以让每个信息片段(或叫“token”)选择最适合的“头”来处理,这样可以提高处理的速度和效率。
- 性能优化:通过选择性地激活最有贡献的“头”,MoH可以在不牺牲准确性的情况下减少计算量。
- 灵活性增强:MoH通过加权求和的方式,让不同的“头”对最终结果的贡献不同,增加了模型的灵活性。
工作原理:
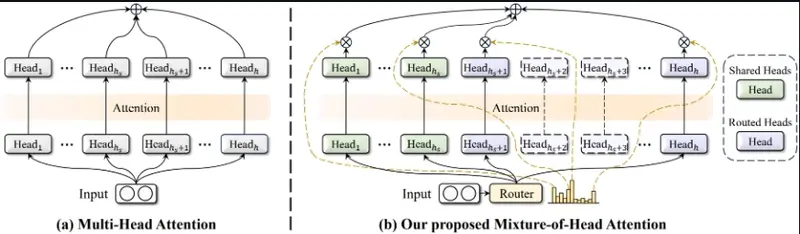
MoH的工作原理是将传统的多头注意力机制中的简单相加操作,改为加权求和。这样,每个“头”都会根据其重要性对最终结果产生不同的影响。同时,MoH还引入了“共享头”和“路由头”的概念,共享头始终被激活,而路由头则根据每个信息片段的需求动态激活。
具体应用场景:
- 图像识别:在识别图片时,MoH可以更有效地识别图片中的不同对象。
- 语言模型:在处理自然语言时,MoH可以更准确地理解句子中的不同部分。
- 图像生成:在生成图片的任务中,MoH可以帮助生成更高质量的图片。
总的来说,MoH就像是一个智能的团队经理,它知道每个队员的长处,并把他们放在最能发挥的地方。这样,整个团队就能以最小的资源消耗,达到最好的效果。