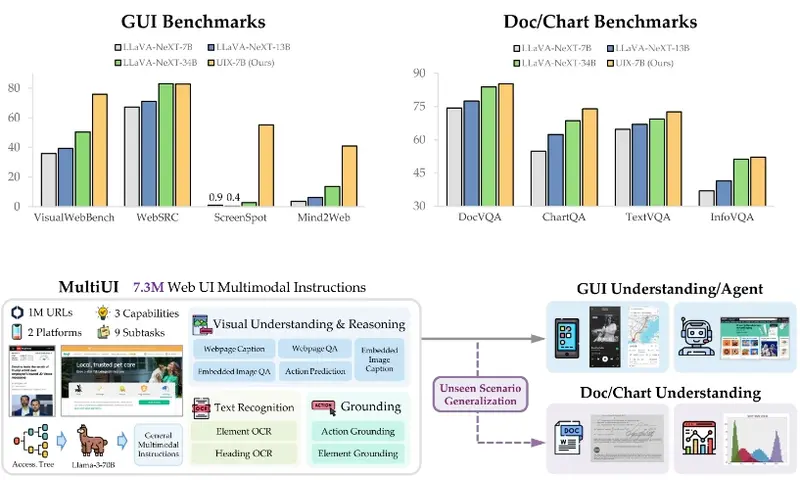
卡内基梅隆大学、香港中文大学、北京大学和滑铁卢大学的研究人员推出一个包含来自 100 万个网站的 730 万个样本的数据集MultiUI,涵盖了多样化的多模态任务和 UI 布局。在 MultiUI 上训练的模型不仅在网页 UI 任务中表现出色——在 VisualWebBench 上提高了 48%,在 Mind2Web 上元素准确性提高了 30%——而且在非网页 UI 任务和甚至非 UI 领域(如文档理解、OCR 和图表解释)中也具有惊人的泛化能力。这些结果突显了网页 UI 数据在推进各种场景中文本丰富的视觉理解方面的广泛适用性。
- 项目主页:https://neulab.github.io/MultiUI
- GitHub:https://github.com/neulab/multiui
- 数据:https://huggingface.co/collections/neulab/mulitui-67117f52c4c257b78213fd25
主要功能和特点:
- 多模态学习:让模型同时处理视觉信息(如图片)和文本信息(如文字描述)。
- 网页UI数据利用:通过分析网页的结构化文本表示,生成有意义的指令,用于训练多模态模型。
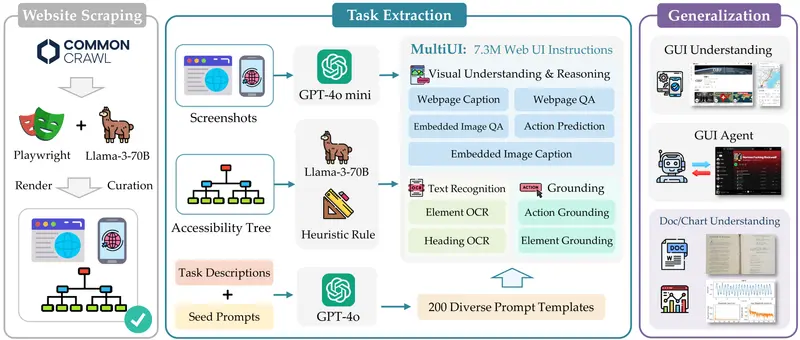
- 数据集构建:研究者们创建了一个名为MultiUI的数据集,包含从100万个网站中提取的730万个样本,覆盖多种多模态任务和UI布局。
工作原理:
- 网页数据抓取:使用网络爬虫技术从网页中抓取HTML、CSS、高分辨率屏幕截图和可访问性树。
- 网页内容清洗:通过可访问性树(一种结构化的网页HTML和元数据表示)来清洗和提炼网页内容。
- 指令生成:利用基于文本的大型语言模型(LLMs)读取可访问性树,并生成描述网页内容和交互的指令。
- 模型训练:将生成的指令与UI屏幕截图配对,训练多模态模型,使其能够从文本和视觉表示中学习。