大型视觉语言模型(LVLMs)能够处理图像和文本,实现多模态理解和生成任务。然而,图像作为输入携带了丰富的信息,这导致了显著的计算成本。随着输入图像分辨率的增加,这些成本呈二次方增长,严重影响了训练和推理的效率。先前的研究尝试通过减少图像标记的数量来解决这个问题,但这些方法往往会导致关键图像信息的丢失,从而降低模型性能。
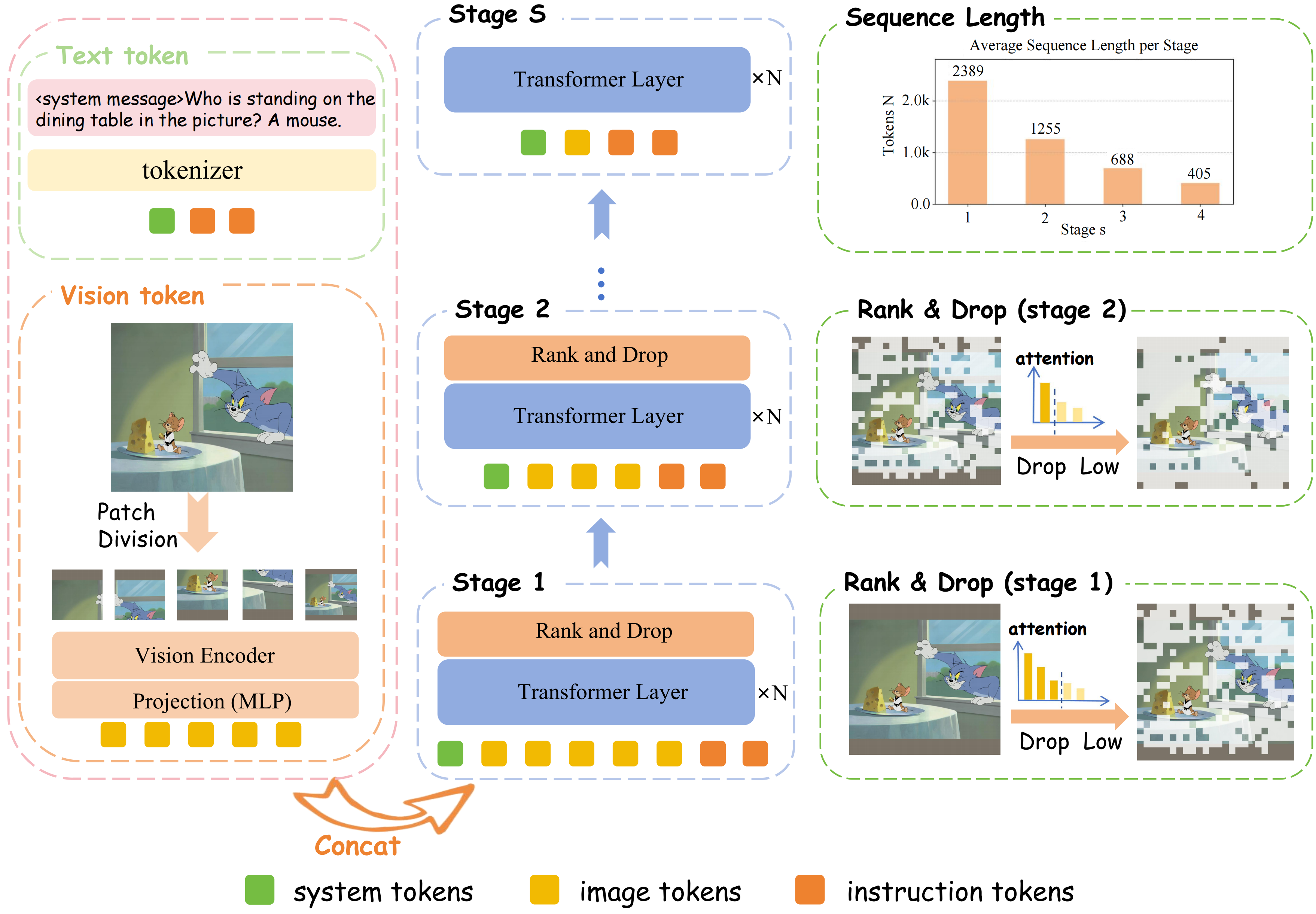
为了解决这一挑战,中国科学技术大学、上海人工智能实验室和香港中文大学的研究人员进行了一项实证研究,揭示了在浅层中所有视觉标记对LVLMs都是必要的,而在模型的深层中标记冗余逐渐增加。基于这一发现,他们提出了一种新的视觉冗余减少策略——PyramidDrop,它就像是一个聪明的图书管理员,能够帮助电脑更高效地处理和记忆图片信息。
主要功能和特点
- 减少冗余:PyramidDrop通过减少不必要的视觉令牌,帮助电脑“瘦身”,减少它需要处理的信息量。
- 保持性能:虽然减少了信息,但PyramidDrop能够保证电脑在回答问题时的性能不会下降,就像图书管理员虽然扔掉了一些不常用的书籍,但关键信息都能快速找到。
- 加速训练和推理:使用PyramidDrop,电脑处理图片的速度会更快,就像图书管理员有了更高效的分类系统,找书的速度大大提升。
工作原理
PyramidDrop的工作原理可以这样理解:
- 分阶段处理:它把电脑处理图片的过程分成几个阶段,每个阶段结束时,都会扔掉一些不再重要的视觉令牌。
- 轻量级计算:在每个阶段结束时,PyramidDrop会进行一些简单的计算,来决定哪些视觉令牌是重要的,哪些可以扔掉。
- 保留关键信息:在电脑的“早期阶段”,它会保留所有的视觉令牌,因为这些信息都很重要。随着阶段的深入,它会逐渐扔掉那些变得不那么重要的视觉令牌。
具体应用场景
PyramidDrop可以应用在很多需要电脑理解和回答图片相关问题的场景中,比如:
- 视觉问答:用户可以问电脑关于图片的问题,比如“图片里的猫是什么颜色的?”电脑能够快速找到答案。
- 图像搜索:在大量的图片中,电脑可以快速识别出用户需要的图片。
- 自动化办公:在处理大量文档图片时,电脑可以快速提取关键信息,提高工作效率。