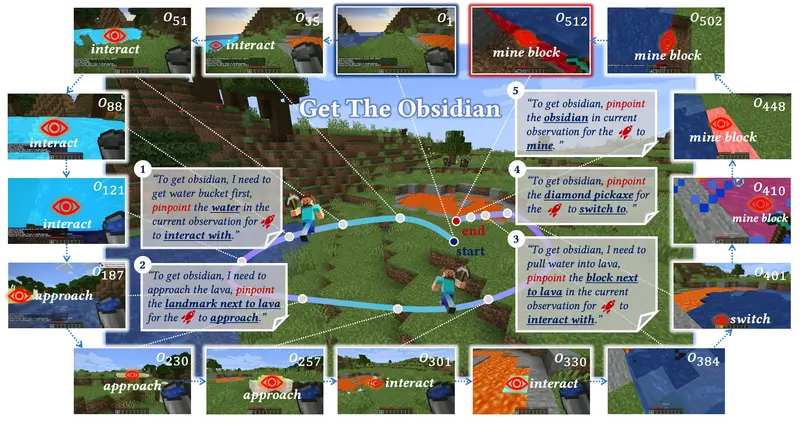
北京大学、北京通用人工智能研究院和加州大学洛杉矶分校的研究人员所组成的CraftJarvis团队发布了一个名为ROCKET-1的系统,它是一个用于开放世界环境中交互的视觉-时间上下文提示模型。ROCKET-1旨在解决在复杂环境中,如何让视觉语言模型(VLMs)更好地进行决策和控制的问题。这个系统通过结合视觉观察和时间上下文信息,提高了模型在空间理解方面的能力,尤其是在需要精确空间信息来规划行动的场景中。
例如,你在一个像《我的世界》这样的开放世界游戏中,需要完成一个复杂的任务,比如“在特定的位置放置一个橡木门”。ROCKET-1能够理解这个任务的空间要求,并在游戏世界中导航到正确的位置,然后执行放置门的动作。这展示了ROCKET-1如何在没有明确指令的情况下,通过视觉和上下文信息来理解和执行任务。
主要功能和特点
- 视觉-时间上下文提示:ROCKET-1使用视觉观察和时间上下文信息来提示行动,这有助于在复杂的开放世界环境中进行精确的交互。
- 无需显式对齐信息:与以往的方法不同,ROCKET-1不需要文本和语音之间的显式对齐信息,也不需要预测音素级别的持续时间。
- 层次化代理架构:ROCKET-1结合了高级推理器(如VLMs)和低级策略,使得复杂任务可以被分解成可执行的子任务。
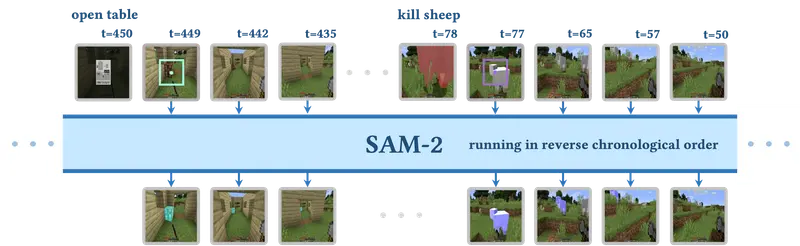
- 实时对象跟踪:通过集成SAM-2模型,ROCKET-1能够在推理过程中增强其对象跟踪能力。
工作原理
ROCKET-1的工作原理包括以下几个关键步骤:
- 对象分割:使用SAM-2模型从过去和现在的观察中分割出对象,以指导策略模型与环境的交互。
- 空间敏感策略:ROCKET-1学习一个基于视觉观察和分割掩码串联的视觉-时间上下文提示的空间敏感策略。
- 因果变换器:使用变换器(Transformer)模型来模拟观察之间的依赖关系,这对于表示部分可观察环境中的任务至关重要。
- 行为克隆损失优化:通过行为克隆损失来优化策略,使ROCKET-1能够直接使用行为克隆进行学习。
具体应用场景
- 游戏环境:在《我的世界》等沙盒游戏中,ROCKET-1可以用于执行复杂的建造、探索和资源收集任务。
- 机器人控制:在现实世界的机器人应用中,ROCKET-1可以帮助机器人理解和执行基于视觉的空间任务。
- 增强现实:在增强现实应用中,ROCKET-1可以提供基于视觉的交互,使用户能够更自然地与虚拟对象进行交互。
- 自动驾驶:在自动驾驶车辆中,ROCKET-1可以帮助车辆理解复杂的交通场景,并做出相应的驾驶决策。