大语言模型(LLMs)的广泛采用在对话式AI、内容生成和设备应用等领域带来了显著进步。然而,对广泛云资源部署这些模型的依赖引发了关于延迟、成本和环境可持续性的担忧。像GPT-4这样的万亿参数模型需要巨大的计算能力,使得基于云的LLMs的财务和能源成本日益不可持续。这些挑战因移动硬件在内存和处理能力方面的限制而进一步加剧,需要开发更小、更高效的模型以适应移动部署。
Meta 的解决方案:MobileLLM
Meta 发布了 MobileLLM,这是一个为移动设备优化的大语言模型(LLM),专注于在参数数量不到十亿的规模上设计高效、高质量的模型,以满足移动设备上对LLM日益增长的需求。这一需求是由于云服务成本的增加和对延迟的担忧所驱动的。
MobileLLM能够在移动设备上运行,处理像“什么是对初学者最好的锻炼方式?”这样的问题,并给出适合初学者的锻炼建议,如体重锻炼、瑜伽、快走等。
主要特点:
- 深度优于宽度:对于小型LLM,更深的网络结构比更宽的网络结构能更好地捕捉抽象概念,从而提高最终性能。
- 嵌入共享:通过共享输入和输出嵌入层的权重,减少模型参数数量,同时保持或提高准确性。
- 分组查询注意力:减少键值头的数量,通过重复使用键值头来提高权重的利用率。
- 块级权重共享:通过在相邻的变换器块之间共享权重,避免了权重在SRAM和DRAM之间的传输,提高了执行速度。
关键创新
- 嵌入共享: 输入和输出层之间重复使用相同的权重,最大化权重利用率同时减少模型大小。
- 分组查询注意力(GQA): 借鉴自 Ainslie et al.(2023),优化了注意力机制并提高了效率。
- 即时块状权重共享: 在相邻块之间复制权重以减少延迟,而不会显著增加模型大小。这种方法减少了权重移动的需求,导致更快的执行时间。
性能表现
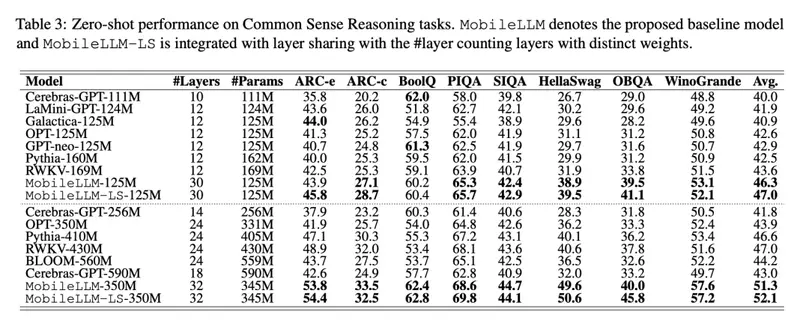
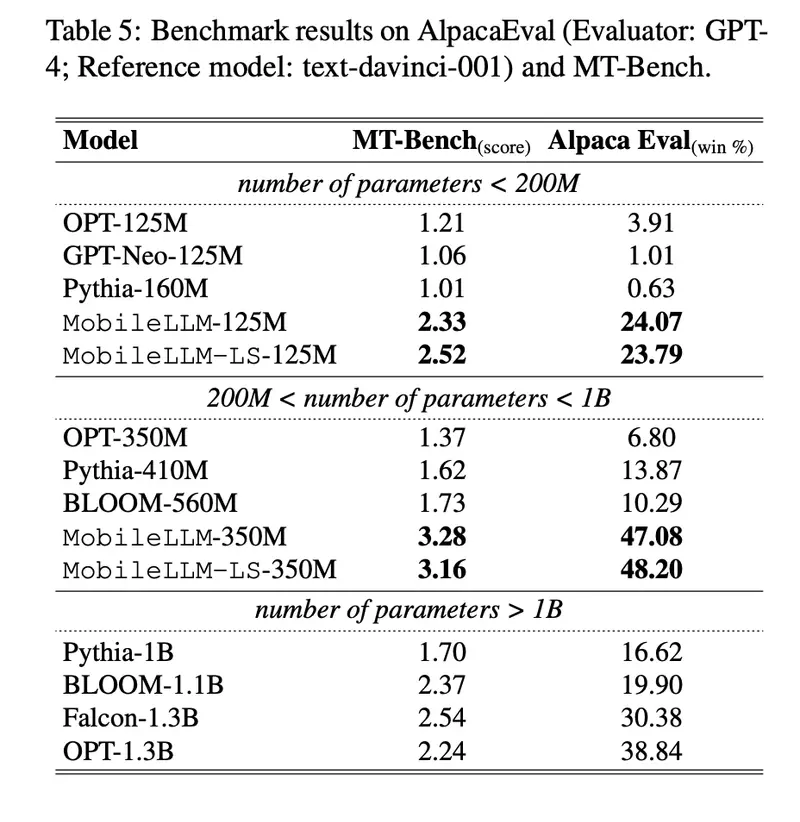
- 零样本任务:MobileLLM 在 125M 模型上比之前的最先进(SOTA)模型高出 2.7%,在 350M 模型上高出 4.3%。这展示了模型在设备应用如聊天和 API 调用中的潜力。
- API 调用任务:MobileLLM-350M 模型实现了与更大的 LLaMA-v2 7B 模型相当的精确匹配分数,尽管其尺寸较小,但展示了其竞争性能。
工作原理:
MobileLLM通过以下几个步骤工作:
- 模型架构设计:选择深度和薄型的结构,以及嵌入共享和分组查询注意力机制,以优化模型性能。
- 权重共享策略:实施块级权重共享,使得模型可以在不增加额外存储成本的情况下增加隐藏层的数量。
- 训练和微调:使用大量的数据训练模型,并在特定的下游任务上进行微调,以提高模型在实际应用中的性能。
重要性
MobileLLM 的重要性在于它能够在不牺牲性能的情况下将复杂的语言建模带到移动设备上。这些模型的高效性和资源优化特性使其成为减少移动用例的延迟和能源消耗的理想选择。通过将 LLMs 的能力带入移动设备,MobileLLM 提升了各种应用的用户体验,从聊天到 API 集成。
结论
Meta 的 MobileLLM 为大规模 LLMs 的计算和环境成本日益增长的担忧提供了创新解决方案。通过侧重于深度而非宽度、嵌入共享、分组查询注意力和即时块状权重共享,MobileLLM 在不需广泛资源的情况下实现了高性能。这一发布代表了将 LLMs 能力带到移动设备上的重要一步,增强了其在一系列应用中的能力,从聊天到 API 集成,同时保持效率并降低运营成本。随着移动技术的不断进步,像 MobileLLM 这样的模型将在推动设备上可实现的目标边界方面发挥关键作用。