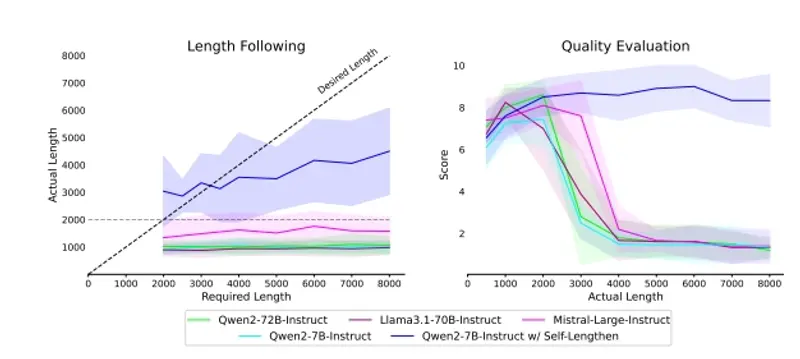
大语言模型(LLMs)的最新进展显著增强了它们处理长上下文的能力,但在生成对齐的长输出方面仍然存在显著差距。这一限制主要源于训练差距,即预训练阶段缺乏长文本生成的有效指令,而后训练数据主要由短查询-响应对组成。当前的方法,如指令回译和行为模仿,面临数据质量、版权问题以及对专有模型使用的限制等挑战。
Self-Lengthen框架
为了解决这些问题,阿里巴巴千问团队提出了一种创新的迭代训练框架,称为Self-Lengthen,旨在提高大语言模型(LLMs)生成长文本的能力。Self-Lengthen通过仅利用LLMs的内在知识和技能,无需辅助数据或专有模型,来培养和提升模型生成长文本对齐输出的能力。
我们有一个大型语言模型,它在处理长文本输入时表现出色,但在生成长文本输出时却力不从心。例如,当给定一个指令生成一个关于“如何种植玫瑰花”的详细指南时,模型可能只能产生一个简短的回答,而不是一个全面的、长篇的指导。Self-Lengthen框架通过迭代训练,可以逐步提高模型生成长文本的能力,使其能够产生更详细、更长的输出。
Self-Lengthen框架包括两个主要角色:生成器和扩展器。
- 生成器:
- 生成初始响应:生成器负责生成初始的短文本响应。
- 扩展器:
- 分割和扩展:扩展器将生成器生成的初始响应分割成多个部分,并对每个部分进行扩展,生成更长的文本段落。
- 迭代训练:
- 生成新的响应:通过扩展器的处理,生成一个新的、更长的响应。
- 反馈循环:新的、更长的响应被用于迭代训练生成器和扩展器,使模型逐步训练以处理越来越长的响应。
主要功能:
- 迭代训练:通过交替训练Generator(生成器)和Extender(扩展器),逐步增加模型输出的长度。
- 自我对齐:无需外部数据或模型,利用LLM自身的能力来提升长文本生成能力。
- 生成长文本:能够生成符合特定长度要求的长文本输出。
主要特点:
- 无需额外数据:不依赖于外部的长文本数据或专有模型。
- 自我扩展:通过自我扩展机制,模型能够逐步增加输出长度。
- 保持质量:在增加输出长度的同时,保持或提升生成内容的质量。
工作原理:
- 初始化:Generator和Extender都初始化为现有的指令模型。
- 生成初始响应:Generator根据给定的查询生成初始响应。
- 分割和扩展:Extender将初始响应分割,并扩展每部分以产生更长的响应。
- 迭代训练:使用新生成的长响应来训练Generator和Extender,使其能够处理更长的输出。
- 微调:在每一轮迭代中,通过微调来改进Generator和Extender,使其能够生成和扩展更长的文本。
实验结果
- 基准测试:
- Qwen2和LLaMA3:Self-Lengthen框架在Qwen2和LLaMA3等顶级开源LLMs上进行了实验。
- 性能提升:实验结果表明,Self-Lengthen在长文本生成方面显著优于现有方法。
- 人类评估:
- 对齐质量:人类评估显示,Self-Lengthen生成的长文本在对齐质量上明显优于现有方法。
- 连贯性和一致性:生成的长文本在连贯性和一致性方面也有显著提升。
关键优势
- 无需辅助数据:
- 自足性:Self-Lengthen框架仅利用LLMs的内在知识和技能,无需额外的辅助数据或专有模型。
- 数据质量控制:
- 高质量生成:通过迭代训练,Self-Lengthen确保生成的长文本具有高质量,避免了数据质量问题。
- 版权和专有模型问题:
- 无版权风险:由于不依赖外部数据或专有模型,Self-Lengthen避免了版权和专有模型使用的问题。
- 灵活性和可扩展性:
- 适应性强:Self-Lengthen框架可以应用于不同大小和类型的LLMs,具有高度的灵活性和可扩展性。
Self-Lengthen框架通过创新的迭代训练方法,显著提升了大语言模型在长文本生成方面的能力。该框架仅利用LLMs的内在知识和技能,无需辅助数据或专有模型,从而避免了数据质量、版权和专有模型使用的问题。实验结果表明,Self-Lengthen在基准测试和人类评估中均表现出色,为长文本生成任务提供了新的解决方案。这一创新为大语言模型在长文本生成领域的应用开辟了新的可能性,特别是在需要高质量、长对齐文本的场景中。