
无限光年推出开源代码语言模型OpenCoder,它旨在为代码生成、推理任务和代理系统等领域提供支持。OpenCoder不仅在性能上与领先的模型相当,而且作为一个“开源菜谱”,为研究社区提供了一个可复现的研究基础。这个模型特别强调了数据预处理流程的透明度和训练协议的清晰性,以促进科学调查和复现性。
- 项目主页:https://opencoder-llm.github.io
- GitHub:https://github.com/OpenCoder-llm/OpenCoder-llm
- 模型:https://huggingface.co/collections/infly/opencoder-672cec44bbb86c39910fb55e
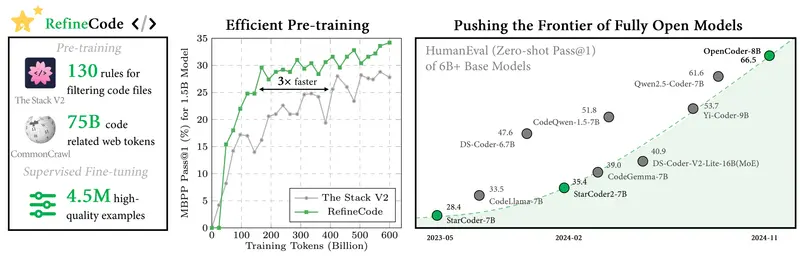
例如,OpenCoder在6B+参数规模的模型中超越了所有之前完全开放的模型(即开放模型权重和可复现数据集的模型),以及其他只有开放模型权重的开放访问模型,将完全开放模型的前沿推向了新的高度。
主要功能
- 代码生成:OpenCoder能够根据给定的文本提示生成代码。
- 代码推理:模型能够理解和执行代码相关的逻辑推理任务。
- 代理系统:在软件代理系统中,OpenCoder可以作为决策和代码生成的核心。
主要特点
- 开源:提供了模型权重、推理代码、可复现训练数据、完整的数据处理流程、严格的实验结果和详细的训练协议。
- 高性能:与领先的专有模型性能相当。
- 数据优化:通过代码优化启发式规则和数据去重方法,提高了数据质量和模型性能。
- 可复现性:提供了完整的数据处理流程和训练协议,使得其他研究者可以复现和验证模型。
工作原理
OpenCoder的工作原理涉及以下几个关键步骤:
- 数据预处理:包括原始代码的收集、去重、转换、过滤和采样,以及从网络数据中提取代码相关信息。
- 预训练:使用高质量的代码数据集对模型进行预训练,以学习代码的语义和结构。
- 后训练(Post Training):包括两阶段的指令调整(Instruction-Tuning),第一阶段侧重于理论计算机科学知识的调整,第二阶段侧重于实际编码任务的调整。
- 数据去重:在预训练和指令调整阶段,通过精确的去重策略保持数据多样性,提高模型性能。
具体应用场景
- 软件开发:辅助开发者编写、理解和优化代码。
- 教育和研究:作为教学工具,帮助学生和研究人员学习编程语言和软件开发的最佳实践。
- 自动化编程任务:在自动化测试、代码审查和软件维护等领域应用,提高软件开发的效率和质量。
- 多语言支持:支持多种编程语言,适用于不同语言的开发环境和需求。
OpenCoder作为一个高性能且完全开源的代码LLM,为代码智能领域提供了一个强大的工具和研究平台,推动了代码生成和理解技术的发展。