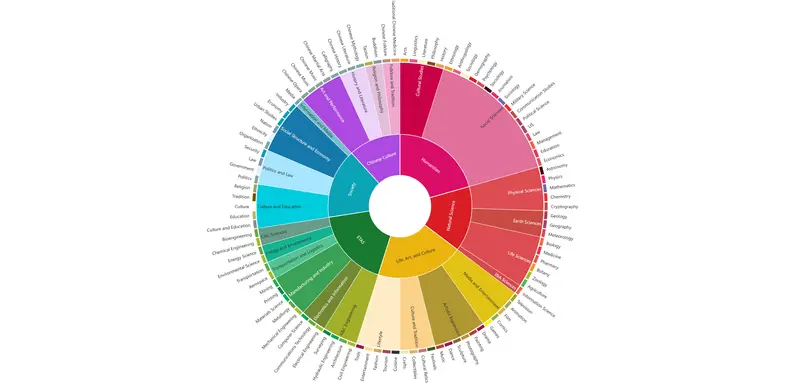
阿里巴巴的研究团队介绍了Chinese SimpleQA,这是一个针对大语言模型(LLMs)进行事实性评估的基准测试,专门针对中文语言。该基准测试旨在评估语言模型在回答简短问题时的事实准确性,特别关注中文领域的知识。
项目主页:https://openstellarteam.github.io/ChineseSimpleQA
Chinese SimpleQA具有五个主要特性,旨在帮助开发者更好地理解其模型在中文真实性方面的能力,并支持基础模型的进步。例如,用户可以问“2024年诺贝尔和平奖的获得者是谁?”如果模型能够准确回答“2024年诺贝尔和平奖的获得者是XXX”,并且该答案在时间上是恒定的(即不会随时间变化),那么这个问题和答案就符合Chinese SimpleQA的评估标准。这种方式确保了对模型的事实性能力进行有效的评估。
主要功能
- 事实性评估: Chinese SimpleQA提供了一种方法来评估LLMs在回答中文问题时的准确性和可靠性。
- 多样化的问题集: 该基准测试涵盖六个主要主题,包括中国文化、人文学科、工程技术、生活艺术、社会和自然科学,确保问题的多样性和广泛性。
- 易于评估: 由于问题和答案都很简短,使用现有的LLMs(如OpenAI API)进行评估非常方便。
主要特点
- 中文专注: 这是第一个专注于中文的事实性评估基准,填补了现有评估工具在中文领域的空白。
- 高质量问题: 通过严格的质量控制流程,确保问题和答案的高质量和准确性。
- 静态参考答案: 所有参考答案都是静态的,不会随着时间的推移而改变,从而保持基准的长期有效性。
- 挑战性问题: 设计的问题具有一定的难度,能够有效评估模型的知识边界。
工作原理
Chinese SimpleQA的构建过程包括自动生成问题和答案对,并经过严格的人工验证。首先,从各种知识领域(如维基百科)提取相关内容,然后使用大语言模型生成问题和答案。接着,通过检索增强生成(RAG)策略验证答案的准确性,确保问题和答案的质量符合预定标准。
评估结果
通过使用Chinese SimpleQA,阿里巴巴的研究团队对当前大型语言模型的真实性能力进行了全面评估。评估结果显示,尽管现有的大型语言模型在某些领域表现良好,但在其他领域仍存在显著的改进空间。具体来说:
- 科学和历史:模型在科学和历史问题上的表现较好,但仍有改进的空间,特别是在处理复杂和多步推理的问题时。
- 文化和生活常识:模型在文化和生活常识问题上的表现参差不齐,需要进一步优化以提高准确性和一致性。
- 技术和地理:模型在技术和地理问题上的表现较为一般,特别是在处理具体和详细的信息时。
应用前景
Chinese SimpleQA不仅为开发者提供了一个标准化的评估工具,还为中文语言模型的研究和应用提供了新的方向。具体应用包括:
- 模型优化:开发者可以使用Chinese SimpleQA评估和优化其模型,提高模型在中文真实性方面的表现。
- 教育和培训:教育机构可以利用Chinese SimpleQA评估学生的知识水平和语言能力,提供个性化的教学建议。
- 内容生成:内容生成平台可以使用Chinese SimpleQA评估生成内容的质量,确保内容的真实性和准确性。