文章目录[隐藏]
随着大语言模型(LLMs)在消费级和企业级应用中的普及,加速令牌生成速度成为了提升用户体验和应用性能的关键挑战。特别是当涉及到长时间推理、多代理协作以及流水线式LLM系统时,生成速度的瓶颈尤为突出。为了解决这一问题,研究人员一直在寻找更高效的方法来加速LLM的推理过程。
当前挑战
现有的基于模型的推测解码技术虽然在一定程度上加快了LLM的推理速度,但依然存在显著局限:
- 依赖性:这些方法高度依赖于草稿模型的质量和规模,而高质量的草稿模型往往难以获得,且需要大量的训练或微调。
- 集成复杂性:草稿模型与LLM在GPU上的集成可能导致内存使用冲突等问题,增加系统复杂性和运行成本。
- 微调需求:即使是在LLM内部集成额外的解码头,也需要针对每个模型进行特定的微调,增加了开发和维护的难度。
SuffixDecoding:无需模型的推测解码方法
为了解决上述问题,Snowflake AI Research 和 卡内基梅隆大学的研究团队提出了一种全新的方法——SuffixDecoding。该方法的核心在于利用高效的后缀树索引来加速LLM的推理过程,而无需依赖额外的草稿模型或解码头。
工作原理
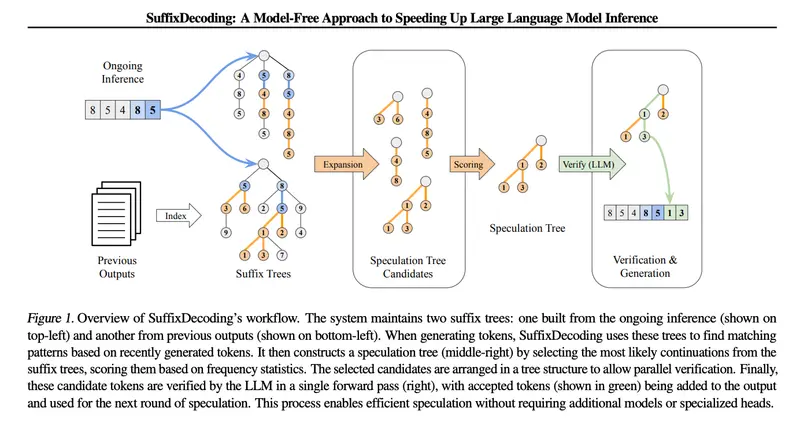
- 后缀树构建:SuffixDecoding 首先将每个提示-响应对进行标记化,并从中提取所有可能的后缀,构建一个后缀树结构。每个节点代表一个令牌,从根节点到任意节点的路径表示一个在训练数据中出现过的子序列。
- 推理过程:对于每一个新的推理请求,SuffixDecoding 根据当前的提示令牌构建一个专门的后缀树。这个设计特别适用于那些需要引用或重用输入提示内容的任务,如文档摘要、问答、多轮对话和代码编辑。
- 模式匹配与推测:在每个推理步骤中,SuffixDecoding 会根据当前生成的令牌序列,快速遍历后缀树,找到所有可能的延续。通过频率统计和经验概率,选择最佳的延续令牌子树,并将这些推测的令牌传递给LLM进行验证。
- 高效验证:得益于拓扑感知因果掩码的树注意力操作符,推测的令牌可以通过单次前向传递完成验证,大大提高了推理效率。
优势
- 无需额外模型:SuffixDecoding 完全不依赖于额外的草稿模型或解码头,避免了与之相关的复杂性和GPU开销。
- 大规模语料库支持:该方法可以利用更大规模的参考语料库,包括数百甚至数千个先前生成的输出,从而更准确地推测后续令牌。
- 高效模式匹配:通过后缀树结构,SuffixDecoding 能够高效地进行模式匹配,选择最佳的延续令牌,提高推测解码的准确性。
实验结果
实验结果表明,SuffixDecoding 在多个基准测试中展现了显著的优势:
- AgenticSQL 数据集:在复杂多阶段的LLM管道中,SuffixDecoding 的输出吞吐量比 SpecInfer 基线高2.9倍,每令牌时间(TPOT)延迟降低3倍。
- 开放任务:在聊天和代码生成等开放性任务中,SuffixDecoding 的吞吐量比 SpecInfer 高1.4倍,TPOT 延迟降低1.1倍。
- 推测解码能力:与基于草稿模型的 SpecInfer 方法相比,SuffixDecoding 在每次验证步骤中能够实现更高的平均接受推测令牌数,证明了其推测解码的高效性和准确性。