文章目录[隐藏]
背景与挑战
近年来,大语言模型(LLMs)在各种应用中展现出了卓越的能力,从解决数学问题到回答医学问题,无不展示了其强大的功能。然而,这些模型的庞大规模和高昂的计算资源需求也带来了诸多问题:
- 财务和环境负担:大型模型的训练和部署需要巨大的计算资源,导致高昂的成本和环境影响。
- 可访问性问题:高昂的成本使得许多研究人员和组织难以接触和使用这些模型。
- 效率和延迟:大型模型在计算资源有限的现实应用中面临效率和延迟的挑战。
TensorOpera AI 的解决方案:Fox-1
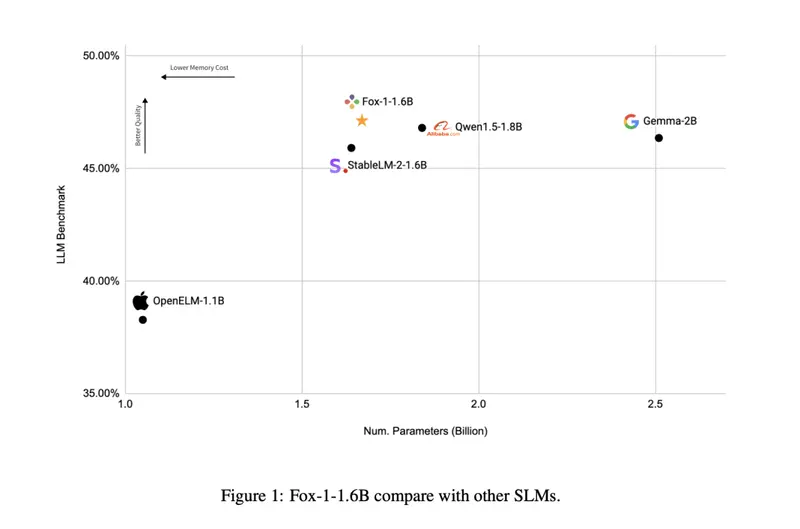
为了解决上述问题,TensorOpera AI 推出了 Fox-1,这是一系列小型语言模型(SLMs),旨在以显著减少的资源需求提供与大型语言模型(LLMs)相当的能力。Fox-1 包括两个主要变体:Fox-1-1.6B 和 Fox-1-1.6B-Instruct-v0.1。这些模型的设计目标是在保持高效和可访问性的同时,提供强大的语言处理能力。
Fox-1-1.6B模型:https://huggingface.co/tensoropera/Fox-1-1.6B
Fox-1-1.6B-Instruct-v0.1模型:https://huggingface.co/tensoropera/Fox-1-1.6B-Instruct-v0.1
技术细节
- 三阶段数据课程:
- 预训练:Fox-1 在3万亿个网络抓取的令牌上进行了预训练,数据被组织成三个不同的阶段,使用2K-8K的序列长度,确保模型能够有效学习文本中的短依赖和长依赖。
- 微调:模型在50亿个令牌上进行了指令遵循任务和多轮对话的微调,进一步提升了其在实际任务中的表现。
- 模型架构:
- 仅解码器Transformer:Fox-1 采用了仅解码器Transformer的更深变体,具有32层,比同类模型更深。
- 分组查询注意力(GQA):优化了内存使用并提高了训练和推理速度。
- 扩展词汇量:256,000个令牌的扩展词汇量增强了模型理解和生成文本的能力,减少了令牌化的歧义。
- 共享输入和输出嵌入:减少了总参数数量,形成了一个更紧凑和高效的模型。
性能结果
Fox-1 的发布具有重要意义,特别是在以下几个方面:
- 可访问性:
- 开源发布:Fox-1 在Apache 2.0许可证下发布,促进了对强大语言模型的开放访问,推动了AI开发的民主化。
- 高效性:模型在NVIDIA H100 GPU上使用vLLM进行了测量,达到了每秒超过200个令牌的速度,与更大模型的吞吐量相当,同时使用更少的GPU内存。
- 基准测试表现:
- GSM8k基准测试:Fox-1 达到了36.39%的准确率,超过了所有比较的模型,包括规模是其两倍的Gemma-2B。
- MMLU基准测试:尽管规模较小,Fox-1 在MMLU基准测试中也展示了优越的性能。
TensorOpera AI 的 Fox-1 系列标志着小型但强大的语言模型开发迈出了重要一步。通过结合高效的架构、先进的注意力机制和周到的训练策略,Fox-1 提供了与更大模型相媲美的性能。
开源发布的举措使得 Fox-1 成为研究人员、开发者和组织在无需承担大型语言模型相关高昂成本的情况下,利用先进语言能力的宝贵工具。Fox-1-1.6B 和 Fox-1-1.6B-Instruct-v0.1 模型展示了通过更高效、简化的方法实现高质量语言理解和生成的可能性,为未来的AI应用提供了新的方向。