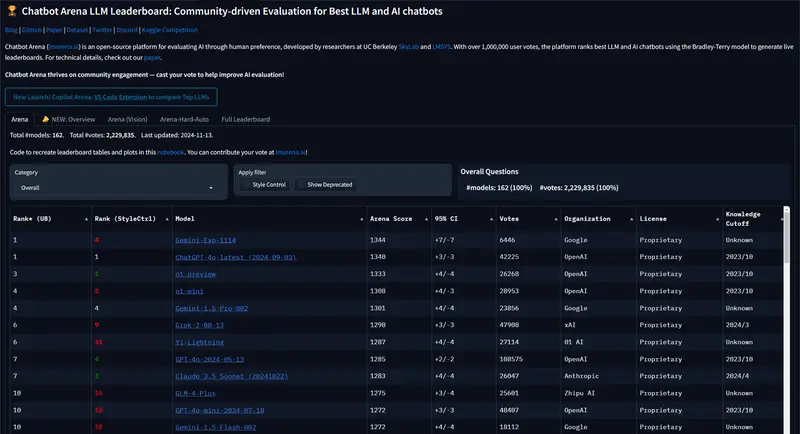
Chatbot Arena 是一个致力于AI基准测试的开放平台。在过去两年间,OpenAI 的模型在多数AI基准测试中占据领先地位。尽管在某些特定领域,Google 的 Gemini 模型和 Anthropic 的 Claude 模型表现优于 OpenAI,但整体来看,OpenAI 仍保持领先。
新模型登场
今日,Chatbot Arena 宣布了一款来自 Google 的新实验模型——Gemini-Exp-1114。这款模型在过去一周内经历了超过6,000次社区投票测试,其表现与 OpenAI 的 ChatGPT-4o-latest(版本日期:2024年9月3日)相当,两者并列第一。与之前的 Gemini 版本相比,Gemini-Exp-1114 的整体评分从1301跃升至1344,甚至超越了 OpenAI 的 o1-preview 模型。
性能亮点
根据 Chatbot Arena 提供的数据,Gemini-Exp-1114 目前在多个评测指标上表现出色:
- 视觉能力:在 Vision 排行榜上位居首位。
- 数学能力:在 Math 类别中排名第一。
- 创意写作:在 Creative Writing 类别中领先。
- 长查询处理:在 Long Queries 类别中表现最佳。
- 指令执行:在 Instruction Following 类别中名列前茅。
- 多轮对话:在 Multi-turn Conversation 类别中排名第一。
- 困难提示处理:在 Hard Prompts 类别中位列第一。
此外,Gemini-Exp-1114 在 Coding 和 Style-controlled Hard Prompts 中排名第三,这两个类别的冠军分别是 OpenAI 的 o1-preview 模型。
比较与优势
与市场上其他知名模型对比,Gemini-Exp-1114 展现了显著的优势。例如,它在与 GPT-4o-latest 的对比中胜率为50%,与 o1-preview 的对比中胜率为56%,而在与 Claude-3.5-Sonnet 的对决中更是达到了62%的胜率。
近期更新
今年9月,Google 对 Gemini 系列进行了升级,推出了 Gemini 1.5 版本。此次更新带来了多项性能提升,包括但不限于 MMLU-Pro 基准测试提升了约7%,MATH 和 HiddenMath 测试提高了约20%,以及视觉和编程应用案例改善了约2%-7%。同时,模型响应的整体实用性也有所增强。据 Google 表述,新版本的回应方式更为精炼,且默认输出长度较之前版本缩短了大约5%-20%。
探索与尝试
对于希望深入了解或试用 Gemini-Exp-1114 模型的开发者,现在可以通过 Google AI Studio 访问该模型。未来,它还将通过 API 向公众开放。感兴趣的读者可以访问 Chatbot Arena 查看 Gemini-Exp-1114 的详细评测结果。