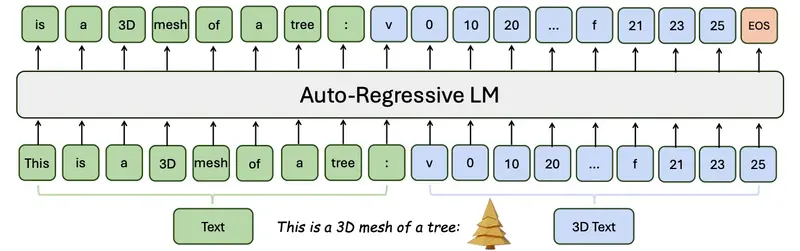
清华大学和英伟达的研究人员推出一个名为LLaMA-Mesh的系统,它能够将3D网格生成与大语言模型(LLMs)结合起来。LLaMA-Mesh通过将3D网格的顶点坐标和面定义表示为纯文本,使得大型语言模型能够直接生成和解释3D网格,而无需扩展词汇表或引入新的分词器。这种方法通过对话界面实现,用户可以提供文本提示,模型则以文本和3D网格的形式响应,促进了交互式3D内容的创建。
- 项目主页:https://research.nvidia.com/labs/toronto-ai/LLaMA-Mesh
- GitHub:https://github.com/nv-tlabs/LLaMa-Mesh
例如,用户想要创建一个古代剑的3D模型,他们可以通过LLaMA-Mesh系统提供简单的文本描述,如“创建一个简单的古代剑的3D模型”。系统将理解这个请求,并生成相应的3D网格数据,用户可以直接用于3D打印或在虚拟环境中使用。
主要功能和特点
主要功能:
- 从文本提示生成3D网格: 用户可以提供描述性的文本,系统将生成相应的3D网格。
- 文本和3D网格的交错输出: 在对话设置中,系统能够产生文本和3D网格的交错输出。
- 理解和解释3D网格: 系统能够以自然语言描述3D网格,帮助用户理解网格的内容。
主要特点:
- 统一模型: 将3D和文本模态统一在一个单一的模型中,无需额外的分词器或词汇扩展。
- 空间知识的利用: 利用LLMs已经内嵌的空间知识,这些知识来源于文本资料,如3D教程。
- 对话式3D生成: 允许用户通过对话与模型交互,进行3D内容的创建和编辑。
工作原理
LLaMA-Mesh的工作原理基于以下几个关键步骤:
- 3D表示: 将3D网格的顶点坐标和面定义转换为纯文本格式,使其能够被LLMs处理。
- 预训练模型: 使用预训练的LLaMA模型作为基础,该模型已经对指令进行了优化,能够生成连贯的响应。
- 3D任务微调: 通过构建包含文本-3D配对和交错文本-3D对话的监督式微调(SFT)数据集,对预训练的LLaMA模型进行微调,使其能够理解和生成3D网格。
具体应用场景
LLaMA-Mesh可以应用于多种场景,包括但不限于:
- 计算机图形学: 在电影和游戏制作中创建3D模型和动画。
- 工程和机器人学: 设计和模拟机械零件或机器人部件。
- 虚拟现实和增强现实: 创建虚拟环境和增强现实应用中的3D对象。
- 教育和培训: 通过交互式学习工具教授3D建模和设计概念。