
视觉语言模型(VLMs)在处理复杂的视觉问答任务时面临挑战。尽管像OpenAI的GPT-o1这样的大语言模型在推理能力方面取得了显著进展,但VLMs在系统性和结构化推理方面仍然存在困难。当前的模型往往缺乏组织信息和进行逻辑、顺序推理的能力,限制了它们在需要深度认知处理的任务中的有效性,特别是在处理图像与文本等多模态输入时。传统的VLMs倾向于立即生成响应,而没有逐步推理的方法,导致错误和不一致。
LLaVA-o1简介
为了解决这些挑战,来自北京大学、清华大学、鹏城实验室、阿里巴巴达摩院和里海大学的研究人员团队推出了LLaVA-o1:一个能够进行系统推理的视觉语言模型,类似于GPT-o1。LLaVA-o1是一个110亿参数的模型,设计用于自主的多阶段推理。它基于Llama-3.2-Vision-Instruct模型,并引入了一个结构化推理过程,以更系统的方法解决了先前VLMs的局限性。LLaVA-o1的关键创新在于实施了四个不同的推理阶段:总结、标题、推理和结论。
例如,考虑一个视觉问题回答任务,模型需要识别图像中的物体,并根据问题(如“图像中有多少个紫色物体?”)给出答案。LLaVA-o1会通过以下步骤来解决这个问题:
- 摘要阶段:模型总结任务,确定需要识别图像中的紫色物体。
- 描述阶段:模型描述图像中与问题相关的部分,例如识别出紫色物体。
- 推理阶段:模型进行逻辑推理,计算紫色物体的数量。
- 结论阶段:模型给出最终答案,例如“图像中有2个紫色物体”。
主要功能:
- 多阶段推理:LLaVA-o1能够将问题解决过程分解为摘要、描述、推理和结论四个结构化阶段。
- 自主推理:模型能够在没有外部提示的情况下,独立进行系统推理。
- 结构化输出:模型在每个推理阶段使用专门的标签,以增强推理过程的清晰度。
主要特点:
- 系统推理:模型能够按照结构化的步骤进行推理,提高了复杂任务的推理能力。
- 结构化标签:通过使用专门的标签来标记每个推理阶段,模型能够更清晰地组织其思考过程。
- 推理时扩展:模型采用阶段级束搜索方法,在推理时扩展其能力,提高了性能的可靠性。
数据集与微调
LLaVA-o1使用了一个名为LLaVA-o1-100k的数据集进行微调,该数据集源自视觉问答(VQA)来源和由GPT-4o生成的结构化推理注释。这使得LLaVA-o1能够进行多阶段推理,将类似GPT-o1的能力扩展到视觉语言任务中,这些任务在历史上一直落后于基于文本的模型。
技术细节和优势
- 阶段级束搜索:LLaVA-o1采用了一种称为阶段级束搜索的新颖推理时缩放技术。与之前的最佳N或句子级束搜索等方法不同,LLaVA-o1为结构化推理过程的每个阶段生成多个响应,并在每一步选择最佳候选,确保更高品质的结果。这种结构化方法在整个推理过程中保持逻辑连贯性,从而得出更准确的结论。
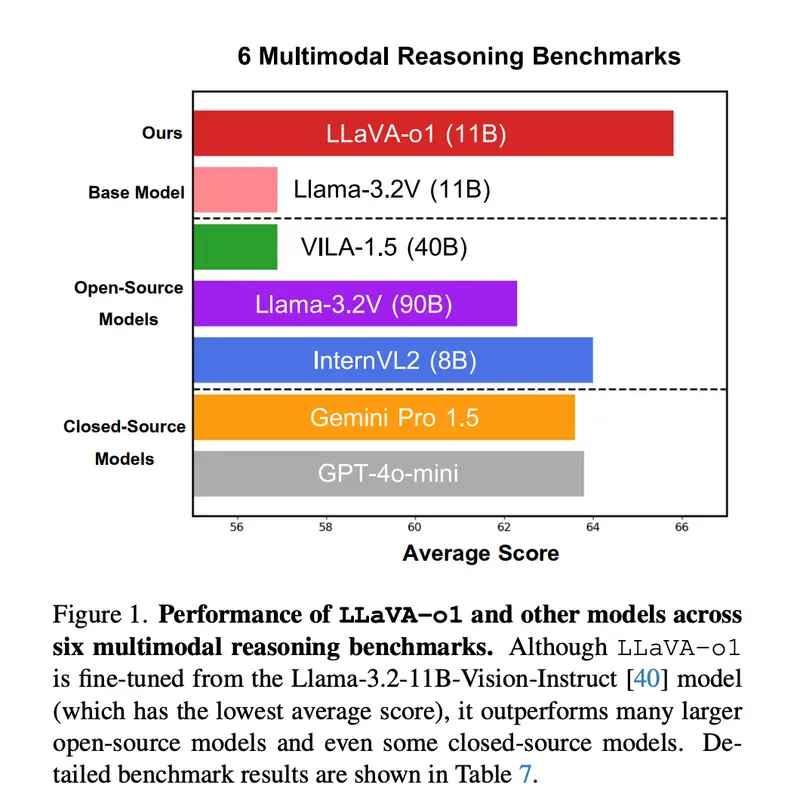
- 模型架构: LLaVA-o1从Llama-3.2-11B-Vision-Instruct模型微调而来,继承了其强大的多模态处理能力。通过引入结构化推理过程,LLaVA-o1在多模态推理基准上比其基础模型提高了8.9%,甚至超过了Gemini-1.5-pro、GPT-4o-mini和Llama-3.2-90B-Vision-Instruct等更大或闭源的竞争对手。
- 高效训练: LLaVA-o1仅使用10万个训练样本就实现了显著的性能提升,使得它在性能和可扩展性方面都是一个高效的解决方案。通过不同阶段进行结构化思考,LLaVA-o1系统地解决问题,减少了其他VLMs中常见的推理错误。
重要性和结果
- 性能提升:实验结果显示,LLaVA-o1在MMStar、MMBench、MMVet、MathVista、AI2D和HallusionBench等基准上提高了性能。它在多模态基准上始终超过其基础模型6.9%以上,特别是在数学和科学视觉问题等推理密集型领域。
- 可靠性增强: 阶段级束搜索通过为每个阶段生成和验证多个候选响应,选择最合适的响应,增强了模型的可靠性。这使得LLaVA-o1在复杂的视觉任务中表现出色,相比传统的推理缩放方法更为高效。
- 结构化响应:LLaVA-o1表明,结构化响应对于实现高质量、一致的推理至关重要,为类似规模的模型设定了新标准。
结论
LLaVA-o1是一个能够进行系统推理的视觉语言模型,类似于GPT-o1。其四阶段推理结构与阶段级束搜索相结合,为多模态AI设定了新基准。通过在一个相对较小但策略性构建的数据集上进行训练,LLaVA-o1表明,无需大型闭源模型所需的庞大资源,高效且可扩展的多模态推理是可实现的。LLaVA-o1为未来视觉语言模型中的结构化推理研究铺平了道路,有望在视觉和文本领域推动更先进的AI驱动认知处理能力。