文章目录[隐藏]
自动化软件工程(ASE)是一个变革性的领域,通过将人工智能与软件开发过程相结合,来解决调试、功能增强和维护挑战。ASE工具越来越多地使用大型语言模型(LLMs)来协助开发者,提高效率并应对软件系统日益增长的复杂性。然而,大多数最先进的工具依赖于专有的闭源模型,这限制了它们的可访问性和灵活性,特别是对于有严格隐私要求或资源限制的组织。
尽管该领域最近取得了突破,但ASE仍然面临着实现可扩展、现实世界解决方案的挑战,这些解决方案能够动态地满足软件工程的细微需求。现有方法的一个重大局限性在于它们过度依赖静态数据进行训练。虽然这些模型在生成功能级解决方案方面有效,但像GPT-4和Claude 3.5这样的模型在需要深入理解项目范围依赖性或现实世界软件开发的迭代性质的任务上表现不佳。这些模型主要在静态代码库上训练,未能捕捉到开发者在与复杂软件系统交互时的动态问题解决工作流程。缺乏过程级洞察力阻碍了它们有效定位故障并提出有意义的解决方案的能力。此外,闭源模型引入了数据隐私问题,特别是对于处理敏感或专有代码库的组织。
Lingma SWE-GPT:开源的解决方案
为了解决这些问题,阿里巴巴集团统一实验室的研究人员开发了Lingma SWE-GPT系列,这是一套针对软件改进优化的大型语言模型。该系列包括两个模型:Lingma SWE-GPT 7B和Lingma SWE-GPT 72B,设计用于模拟现实世界的软件开发过程。与闭源模型不同,这些模型是可访问的、可定制的,并且旨在捕捉软件工程的动态方面。通过整合来自现实世界代码提交活动和迭代问题解决工作流程的洞察,Lingma SWE-GPT旨在缩小开源和闭源模型之间的性能差距,同时保持可访问性。
开发方法论
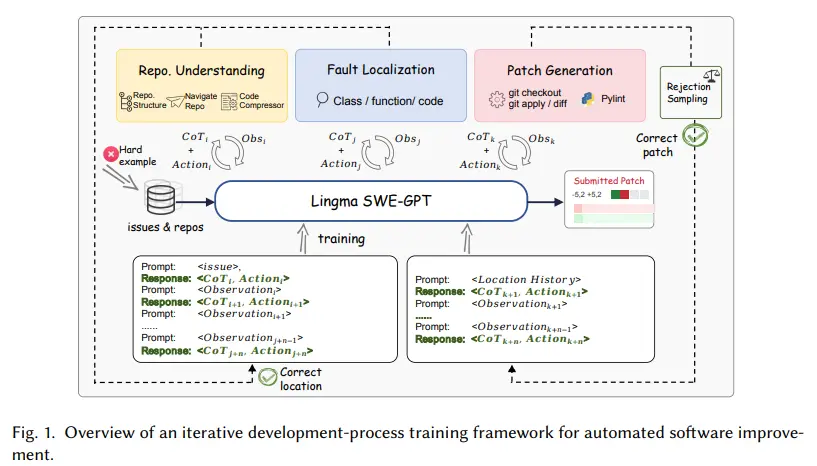
Lingma SWE-GPT的开发遵循了一个结构化的三阶段方法论:
- 仓库理解:模型分析项目的仓库层次结构,从目录、类和函数中提取关键结构信息,以识别相关文件。
- 故障定位:模型使用迭代推理和专用API精确地定位有问题的代码片段。
- 补丁生成:模型创建和验证修复,使用git操作确保代码完整性。
训练过程强调以过程为导向的数据合成,采用拒绝采样和课程学习来迭代地改进模型,逐步处理更复杂的任务。
性能评估
性能评估表明,Lingma SWE-GPT在模拟现实世界GitHub问题的基准测试(如SWE-bench Verified和SWE-bench Lite)上有效。具体而言:
- Lingma SWE-GPT 72B模型在SWE-bench Verified数据集中解决了30.20%的问题,这一性能接近解决了31.80%问题的GPT-4o,并比开源的Llama 3.1 405B模型提高了22.76%。
- Lingma SWE-GPT 7B模型在SWE-bench Verified上实现了18.20%的成功率,超过了Llama 3.1 70B的17.20%。
这些结果突出了开源模型在缩小性能差距的同时保持成本效益的潜力。
关键优势
- 开源可访问性:Lingma SWE-GPT模型使高级ASE功能民主化,使其对各种开发者和组织可访问。
- 性能平价:72B模型在SWE-bench Verified上实现了与最先进的闭源模型相当的性能,解决了30.20%的问题。
- 可扩展性:7B模型在资源受限的情况下表现出强大的性能,为资源有限的组织开展了一个成本效益的解决方案。
- 动态理解:通过融入以过程为导向的训练,Lingma SWE-GPT捕捉了软件开发的迭代和交互性质,弥补了静态数据训练留下的空白。
- 增强的故障定位:模型使用迭代推理和专用API定位具体故障位置的能力确保了高准确性和效率。
经济效益
开源模型的开销优势进一步增强了它们的吸引力,因为它们消除了与闭源替代品相关的高API成本。例如,使用GPT-4o解决SWE-bench Verified数据集中的500个任务大约需要390美元,而Lingma SWE-GPT没有直接的API成本。
Lingma SWE-GPT代表了自动化软件工程(ASE)领域的一个重大进步,解决了静态数据训练和闭源依赖的关键局限性。其创新的方法论和有竞争力的性能使其成为寻求可扩展和开源解决方案的组织的诱人选择。通过将过程导向的洞察与高可访问性相结合,Lingma SWE-GPT为软件开发中AI辅助工具的更广泛采用铺平了道路,使高级功能更加包容和成本效益。