2024年6月,月之暗面 Kimi 和清华大学 MADSys 实验室联合发布了 Kimi 底层的 Mooncake 推理系统设计方案。该系统基于以 KVCache 为中心的 PD 分离和以存换算架构,显著提升了大语言模型(LLM)的推理吞吐量。为了进一步加速该技术框架的应用与推广,月之暗面 Kimi 和清华大学 MADSys 实验室联合多家企业和机构共同发布了开源项目 Mooncake,旨在共建以 KVCache 为中心的大模型推理架构。
Mooncake 系统概述
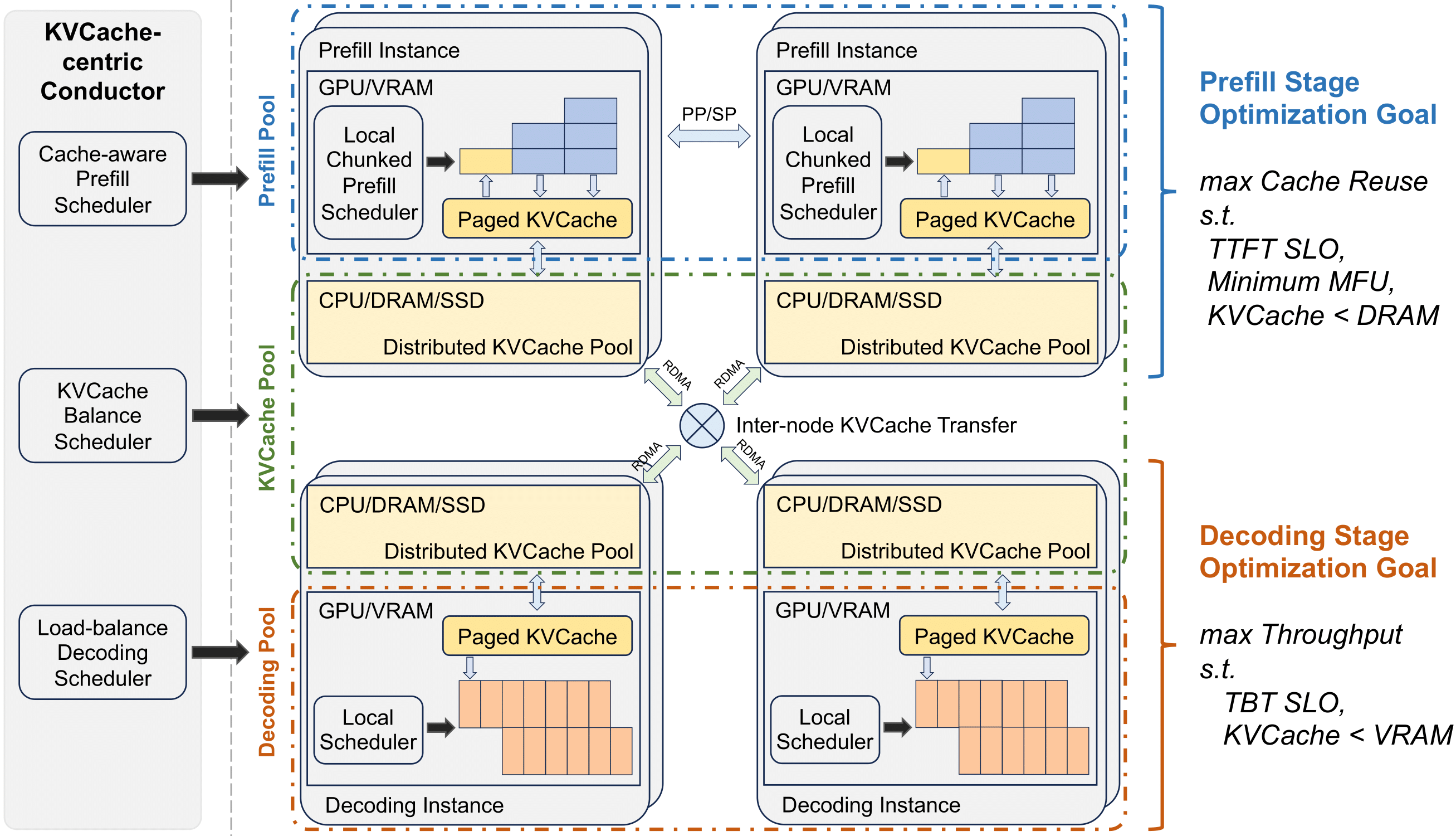
Mooncake 是一个专门为大语言模型(LLM)服务设计的KVCache中心化分离架构。其核心目标是高效地处理大语言模型的请求,特别是在处理长上下文和高负载场景时。Mooncake通过以下关键技术实现了这一目标:
- KVCache中心调度:Mooncake的核心是一个KVCache中心化的调度器,它平衡了最大化整体有效吞吐量和满足延迟相关的服务水平目标(SLOs)。
- 预填充和解码分离:系统将预填充和解码阶段分离,以优化资源利用。
- 预测性早期拒绝策略:在高负载场景下,系统可以预测未来负载并提前拒绝某些请求,以节省计算资源。
主要功能
- 提高吞吐量:在某些模拟场景中,Mooncake能够实现高达525%的吞吐量提升。
- 处理长上下文:Mooncake擅长处理需要长上下文理解的任务。
- 资源优化:通过分离资源池,Mooncake能够更有效地利用GPU集群中的资源。
工作原理
Mooncake的工作原理涉及以下几个关键步骤:
- 全局调度:一个名为Conductor的全局调度器负责根据KVCache的分布和工作负载调度请求。
- KVCache重用:系统尽可能重用KVCache以减少所需计算资源。
- 增量预填充:预填充阶段被分成多个块(chunks)或层(layers),以流水线方式执行,以减少长上下文输入的首次响应时间(TTFT)。
- KVCache传输:使用名为Messenger的服务在不同的节点间高速传输KVCache。
- 解码:在解码节点,请求以连续批处理的方式加入到下一个批次中,以提高效率。
开源项目
Mooncake 开源项目旨在为大模型时代打造一种新型高性能内存语义存储的标准接口,并提供参考实现方案。该项目将采用分阶段的方式,逐步开源高性能 KVCache 多级缓存 Mooncake Store 的实现,同时针对各类推理引擎和底层存储 / 传输资源进行兼容。目前,传输引擎 Transfer Engine 部分已经在 GitHub 上全球开源。
示例应用
当用户向一个基于大语言模型的聊天服务发送一条消息时,模型需要处理这条消息并生成回复。Mooncake通过其架构可以快速地从缓存中检索相关信息(KVCache),加速响应时间,同时确保系统能够在高请求量下稳定运行。
参与机构
Mooncake 开源项目得到了多家知名企业和机构的支持,包括:
- 9#AISoft
- 阿里云
- 华为存储
- 面壁智能
- 趋境科技
结语
Mooncake 的推出标志着大语言模型推理技术的一大进步。通过高效的KVCache管理和资源优化,Mooncake不仅提升了推理吞吐量,还在处理长上下文和高负载场景中表现出色。随着更多企业和开发者的加入,Mooncake有望成为大模型时代的重要基础设施之一。