文章目录[隐藏]
随着顶级AI公司在开发更新、更强大的大语言模型(LLMs)方面遇到困难,焦点正逐渐转向寻找“Transformer”架构的替代方案。Transformer是支撑当前生成式AI繁荣的核心技术,由谷歌研究人员在2017年的开创性论文《Attention Is All You Need》中引入。如今,麻省理工学院孵化的初创公司Liquid AI推出了一个名为STAR(Synthesis of Tailored Architectures)的创新框架,旨在自动化生成和优化AI模型架构。
官方介绍:https://www.liquid.ai/research/automated-architecture-synthesis-via-targeted-evolution
Transformer的局限性
尽管Transformer在处理序列数据(如文本或时间序列信息)方面取得了巨大成功,但它也面临一些挑战:
- 计算资源需求高:Transformer模型通常需要大量的计算资源,尤其是在处理大规模数据集时。
- 缓存效率低:Transformer模型的缓存使用效率较低,导致推理速度较慢。
- 手动调整复杂:传统架构设计依赖于手动调整和预定义模板,这限制了模型的灵活性和优化空间。
STAR框架的创新之处
1. 自动化架构生成与优化
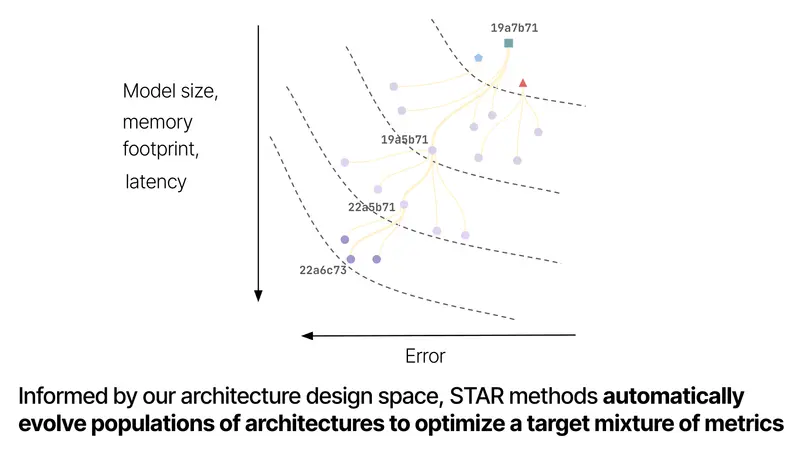
STAR框架利用进化算法和数值编码系统来解决深度学习模型中平衡质量和效率的复杂挑战。与传统方法不同,STAR不依赖手动调整或预定义模板,而是使用一种称为“STAR基因组”的分层编码技术,来探索潜在架构的广阔设计空间。
- STAR基因组:这些基因组支持重组和突变等迭代优化过程,使STAR能够合成和优化符合特定指标和硬件要求的架构。
- 模块化设计:STAR的模块化特性允许框架在多个层次上编码和优化架构,提供了对重复设计主题的洞察,并使研究人员能够识别有效的架构组件组合。
2. 显著的性能提升与效率改进
Liquid AI的研究团队通过一系列实验展示了STAR生成架构的能力,这些架构在质量和缓存大小优化方面始终优于高度优化的Transformer++和混合模型。
- 缓存大小减少:在优化质量和缓存大小时,STAR进化的架构相比混合模型实现了高达37%的缓存大小减少,相比Transformer实现了90%的减少。尽管这些效率改进,STAR生成的模型在预测性能上保持或超过了其对应模型。
- 参数数量减少:同样,在优化模型质量和大小方面,STAR在标准基准测试中仍提高了性能,同时减少了高达13%的参数数量。
- 扩展能力:一个从1.25亿参数扩展到10亿参数的STAR进化模型在减少推理缓存需求的同时,提供了与现有Transformer++和混合模型相当或更优的结果。
3. 理论基础与多功能搜索空间
STAR根植于一种结合了动力系统、信号处理和数值线性代数的原则的设计理论。这种基础方法使团队能够开发一个涵盖注意力机制、递归和卷积等组件的计算单元的多功能搜索空间。STAR的模块化设计不仅提高了架构的灵活性,还为未来的创新提供了坚实的基础。
应用前景
STAR合成高效、高性能架构的能力不仅限于语言建模,还可以应用于各个领域,特别是在质量和计算效率之间权衡的关键挑战中。以下是STAR的一些潜在应用领域:
- 计算机视觉:优化图像分类、目标检测和语义分割等任务的模型架构。
- 语音识别:提高语音识别系统的准确性和实时处理能力。
- 自然语言处理:改进机器翻译、文本生成和问答系统等任务的性能。
- 推荐系统:优化个性化推荐系统的架构,提高推荐的准确性和效率。
商业与研究影响
尽管Liquid AI尚未披露具体的商业部署或定价计划,但STAR框架的研究结果标志着自动化架构设计领域的重要进展。对于寻求优化AI系统的研究人员和开发者来说,STAR可能代表了一个强大的工具,用于推动模型性能和效率的边界。
通过其开放研究的方法,Liquid AI在同行评审的论文中公布了STAR的全部细节,鼓励合作和进一步创新。随着AI领域的继续发展,像STAR这样的框架有望在塑造下一代智能系统中发挥关键作用。
未来展望
STAR甚至可能预示着新的后Transformer架构繁荣的诞生,这对机器学习和AI研究社区来说是一个受欢迎的冬季假期礼物。随着更多研究机构和企业开始探索STAR的潜力,我们可能会见证AI架构设计的一场革命,带来更加高效、灵活和强大的模型。