近年来,视觉-语言模型通过扩展视觉标记的长度来增强其性能,超越了传统的文本标记方法。然而,这一策略也带来了显著的计算成本增加。研究发现,尽管视觉编码器(例如CLIP和SigLIP)生成的视觉标记在数量上有所增加,但其中存在大量的冗余信息,这不仅增加了处理时间,还并未有效提升模型的表现。
VisionZip:精选视觉标记,提高模型效率
为了解决上述问题,香港中文大学、香港科技大学的研究团队共同开发了一种名为VisionZip的新方法。该方法旨在通过筛选出一组最具信息量的视觉标记,输入给语言模型,从而减少不必要的冗余,同时保持甚至提高模型的性能。VisionZip的核心思想是“精简而高效”,它能够有效地应用于图像和视频理解任务,并特别适合于需要多轮对话的真实应用场景,这些场景中以往的方法往往难以达到理想的效果。
例如,在处理一张图片时,传统的视觉语言模型可能会将图片分割成数百个视觉令牌,每个令牌对应图片中的一个区域。这些令牌随后被输入到语言模型中进行处理。但是,这种方法可能会导致大量计算资源的浪费,因为许多令牌可能只包含背景或其他不重要的信息。VisionZip通过识别并保留那些包含关键信息的令牌,减少了需要处理的令牌数量,从而提高了模型的效率。
主要功能和主要特点
- 主要功能:VisionZip的主要功能是减少视觉语言模型中视觉令牌的冗余,提高模型的计算效率,同时保持或提升模型性能。
- 主要特点:
- 效率提升:通过减少视觉令牌的数量,VisionZip显著提高了模型的推理速度,并减少了预填充时间。
- 性能保持:即使在减少令牌数量的情况下,VisionZip也能保持或提升模型在多种设置下的性能。
- 通用性:VisionZip适用于多种视觉语言模型和任务,包括图像和视频理解任务,以及实际场景中的多轮对话。
工作原理
VisionZip的工作原理包括以下几个步骤:
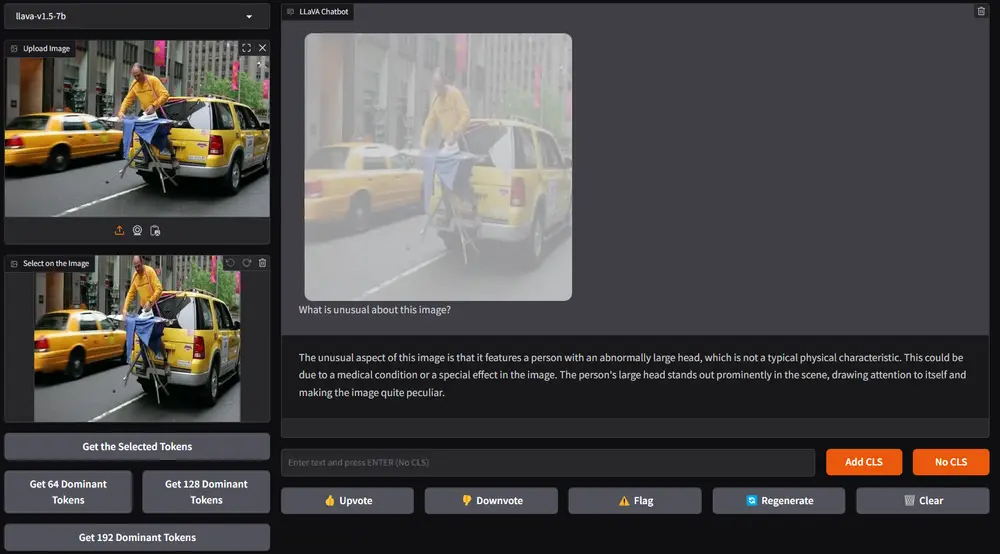
- 主导令牌选择(Dominant Token Selection):通过分析视觉编码器的注意力分数,选择那些接收到最多注意力的令牌,这些令牌通常包含最关键的视觉信息。
- 上下文令牌合并(Contextual Tokens Merging):对于未被选为主导令牌的视觉令牌,基于它们的相似性将它们合并,以保留可能重要的细节信息。
- 高效调优(Efficient Tuning):在减少视觉令牌数量后,对模型进行微调,以适应减少的令牌数量,并增强视觉和语言空间之间的对齐。
实验验证:性能与速度的双重突破
实验结果显示,VisionZip在多种设置下均展现了优越性,相较于之前的最先进方法,性能提升了至少5%。此外,VisionZip极大地提高了模型的推理速度,预填充时间更是提高了8倍之多。这意味着,使用VisionZip优化后的LLaVA-Next 13B模型不仅在推理速度上超过了更小的7B版本,而且还能提供更为精准的结果。
深入分析:从冗余到精华
研究人员进一步探讨了视觉标记冗余的原因,并指出,未来的研究应该更加注重于如何提取更具代表性的视觉特征,而不是简单地增加标记的数量。这一观点鼓励社区内的开发者和研究人员关注质量而非数量,以推动视觉-语言模型向更高效、更智能的方向发展。