文章目录[隐藏]
大型多模态模型(LMMs)在处理视觉语言任务时表现出色,但在跨文化情境中的有效性仍有待提高。这些模型通常依赖于单一代理架构,如BLIP-2和LLaVA-13b,它们在生成图像描述时往往显得刻板且缺乏文化深度。这主要是因为:
- 训练数据的局限性:现有的训练数据集大多源自西方国家,导致模型在处理非西方文化内容时表现不佳。
- 文化表达的缺失:传统的评估指标(如准确率和F1分数)主要关注总体正确性,而忽略了文化表达的细微差别和深度。
- 单一视角的局限:单代理模型难以捕捉多种文化视角的复杂性和多样性,导致其输出缺乏具体性和丰富性。
MosAIC的创新解决方案
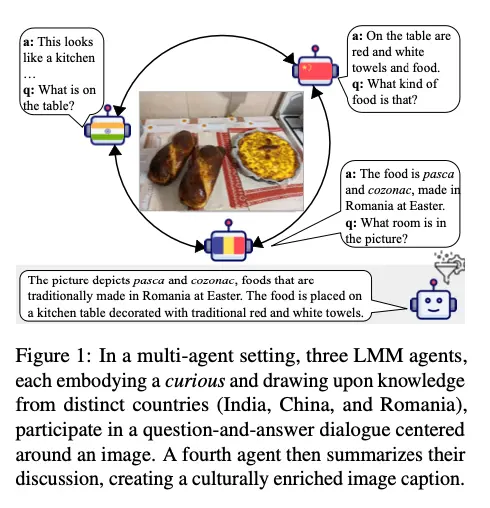
为了解决这些问题,密歇根大学和圣克拉拉大学的研究人员开发了MosAIC(Multicultural Observations and Summaries through AI Collaboration),这是一个通过协作交互增强文化图像描述的创新框架。MosAIC的核心思想是利用一组具有特定文化身份的多个代理,通过有组织的、有主持的讨论来生成更丰富、更具文化深度的图像描述。
关键特点:
- 多代理协作:
- 多样化文化视角:每个代理都代表一个特定的文化背景(例如中国、印度、罗马尼亚等),能够从各自的文化角度分析图像并提出见解。
- 协作讨论:代理之间进行多轮交互,分享各自的观察和解释,最终由一个总结代理将这些观点整合成一个综合性的、文化增强的描述。
- 思维链提示:通过引导代理按照逻辑步骤思考和表达,确保输出结构良好且连贯。
- 文化适应性评估指标:
- 创新评估方法:MosAIC引入了一种专门设计的文化适应性评估指标,用于衡量描述中文化成分的表达质量。这种评估不仅关注描述的准确性,还强调其文化相关性和深度。
- 人类评估:为了验证模型的表现,研究人员还进行了人类评估,邀请来自不同文化背景的参与者对生成的描述进行评分。结果显示,MosAIC生成的描述在文化一致性和细节方面显著优于传统单代理模型。
- 地理多样化的数据集:
- 丰富的训练数据:MosAIC使用了来自GeoDE、GD-VCR和CVQA的2,832个描述的数据集,涵盖中国、印度和罗马尼亚三种不同的文化。这种多样化的数据集确保了模型能够学习到不同文化的独特特征。
- 记忆管理系统:为了在多轮讨论中保持一致性,MosAIC引入了一个记忆管理系统,帮助代理跟踪之前的讨论内容,避免重复或偏见。
- 迭代学习机制:
- 持续改进:通过多轮交互和反馈,代理可以不断学习和调整自己的描述方式,逐渐提高其文化敏感性和表达能力。
实验结果与优势
MosAIC在生成更深入且更具文化完整性的描述方面显著优于单代理模型。具体表现为:
- 捕捉多样化的文化术语:MosAIC能够更好地融入不同文化中的特有词汇和表达方式,使描述更加具体和生动。
- 文化表达的深度:在文化适应性评估指标中,MosAIC生成的描述获得了更高的分数,表明其能够更好地反映文化细微差别。
- 图像内容的一致性:尽管增加了文化元素,MosAIC生成的描述仍然与图像内容保持高度一致,确保了描述的准确性。
- 人类评估的高度认可:参与者普遍认为,MosAIC生成的描述在文化背景、细节和包容性方面远超传统模型。
结论与未来展望
MosAIC通过引入多代理协作框架,成功解决了LMMs中的西方中心偏见问题,为生成上下文准确且文化丰富的描述提供了新的思路。这一创新不仅提升了AI在跨文化情境中的表现,还为创建更具包容性和全球相关的人工智能系统奠定了基础。