文章目录[隐藏]
随着基础模型(Foundation Models, FMs)泛化能力的增强,构建广泛能力且目标导向的智能体成为了可能。这些智能体能够在数字世界中执行互联网浏览任务或在物理世界中作为家用人形机器人辅助日常生活。然而,传统上每项新技能都需要通过人工标注指令手动指定,这极大地限制了智能体技能库的规模和多样性。
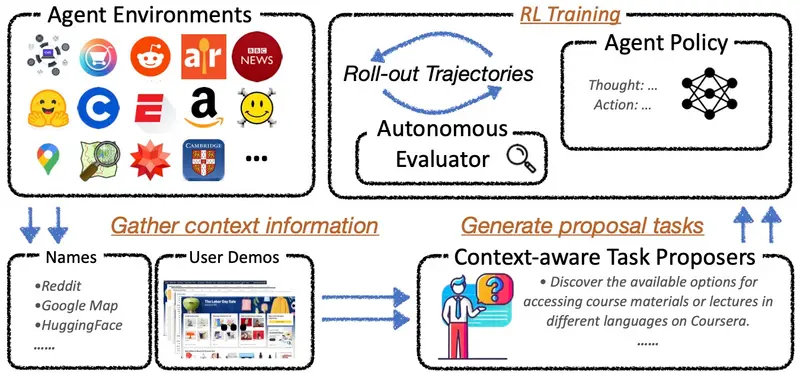
为了解决这一瓶颈,加州大学伯克利分校、伊利诺伊大学厄巴纳-香槟分校和亚马逊的研究人员共同提出了Proposer-Agent-Evaluator(PAE)系统。PAE使智能体能够自主发现并练习新技能,无需依赖大量的人工标注数据。该系统特别适用于需要处理多样化和复杂环境的任务,如基于视觉的网络导航。
PAE系统的工作原理
1. 上下文感知的任务提议器
PAE的核心是一个上下文感知的任务提议器,它能够根据环境信息(例如用户演示或网站名称)自动建议适合当前情境的任务。这个提议过程是基于条件自回归生成模型完成的,确保了所提议任务的多样性和可行性。提议的任务随后由智能体尝试执行。
2. 基于图像的结果评估器
为了评估智能体执行任务的成功与否,PAE使用了一个基于图像的结果评估器。评估器会检查智能体操作后的最后三个截图及其最终答案,提供一个二进制的成功/失败评价。这种评估方式充分利用了VLMs在图像理解和语言处理上的优势,同时简化了评估流程,提高了鲁棒性。
3. 思维链智能体策略
为了增强智能体对未见过任务的泛化能力,PAE引入了一个额外的推理步骤——思维链。在实际网页操作之前,智能体会先进行推理,输出其思考过程。这一过程同样受到强化学习算法的优化,从而提升了智能体在面对新任务时的表现。
4. 强化学习循环
PAE采用了一种在线强化学习机制,智能体在尝试提议的任务后,根据评估器提供的奖励信号调整自己的行为策略。这种闭环学习使得智能体能够不断改进,逐步掌握更多复杂的技能。
实验验证与性能提升
研究团队在两个具有挑战性的基于视觉的网络导航任务中验证了PAE的有效性:
- WebVoyager:这是一个实时商业网站的导航基准。实验结果显示,PAE显著提高了7B和34B参数模型的性能,相对提升超过50%。特别是,LLaVa-34B PAE版本超越了之前最先进的Qwen2VL-72B模型,在成功率上取得了超过10%的绝对提升(从22.6%提升到33.0%)。
- WebArena Easy:这是一个现实沙盒环境中的简化任务集。尽管模型规模较小,PAE依然表现出色,相对于SFT(监督微调)检查点实现了类似的性能提升,并超越了Qwen2VL-72B。
定性分析与失败模式
除了定量结果,研究人员还进行了定性比较,展示了PAE训练前后智能体行为的变化。PAE不仅教会了智能体更多样化的技能,还减少了视觉幻觉和低级网页导航技能缺失等错误类型。这表明PAE有效地丰富了智能体的技能库,使其更能应对未知任务。