在为期12天的“shipmas”活动的最后一天,OpenAI 宣布了其最新的推理模型系列 o3,这是继今年早些时候发布的 o1 之后的重大更新。o3 不仅在性能上有了显著提升,还引入了新的功能和对齐技术,旨在使其更接近 人工通用智能(AGI)。然而,这一声明也伴随着重要的限制和潜在的风险。
为什么跳过 o2?
有趣的是,OpenAI 并没有按照惯例发布 o2,而是直接推出了 o3。根据《信息报》的报道,OpenAI 跳过 o2 是为了避免与英国电信提供商 O2 发生潜在的商标冲突。CEO Sam Altman 在直播中部分证实了这一点,强调了商标问题的重要性。这再次提醒我们,技术发展不仅受技术本身的影响,还受到法律和商业环境的制约。
o3 和 o3-mini:模型系列
o3 实际上是一个模型系列,包括两个版本:
- o3:主模型,具有强大的推理能力和广泛的适用性。
- o3-mini:一个更小、经过蒸馏的版本,针对特定任务进行了微调,适用于资源受限的环境。
这两个模型目前尚未广泛可用。安全研究人员可以从今天晚些时候开始注册 o3-mini 的预览,而 o3 的预览将在稍后推出。Altman 表示,计划是在 1月底 推出 o3-mini,随后不久推出 o3。
接近 AGI:带有重要限制
OpenAI 声称 o3 在某些条件下接近 AGI,但这一说法带有重要的限制。AGI,即 人工通用智能,是指能够执行人类能做的任何任务的 AI 系统。OpenAI 对 AGI 的定义是:“在大多数经济价值工作中超越人类的自主系统。”
尽管 o3 在多个基准测试中表现出色,但实现真正的 AGI 仍然是一个遥远的目标。根据 ARC-AGI 基准测试,o3 在高计算设置下达到了 87.5% 的分数,而在低计算设置下,其性能是 o1 的三倍。虽然这是一个显著的进步,但 ARC-AGI 本身也有其局限性,且 AGI 的定义多种多样。
新的对齐技术:“深思熟虑的对齐”
为了确保 o3 等模型与其安全原则保持一致,OpenAI 引入了一种新技术——深思熟虑的对齐。这项技术通过让模型在回应前进行自我事实核查,帮助其避免常见的陷阱。o3 通过所谓的“私人思维链”进行训练,能够在回应前暂停,考虑多个相关提示并在过程中“解释”其推理。最终,模型会总结出它认为最准确的回应。
这种自我事实核查的过程带来了几秒到几分钟的延迟,但换来的是更高的可靠性和准确性,特别是在物理、科学和数学等领域。
可调整的推理时间
o3 的一个重要新功能是能够“调整”推理时间。用户可以设置为低、中或高计算模式,计算越高,模型的表现越好。这种灵活性使得 o3 可以根据具体需求进行优化,既可以在资源受限的情况下提供快速响应,也可以在需要时进行更深入的推理。
基准测试表现
o3 在多个基准测试中表现出色,超越了其前身 o1 以及竞争对手的模型。例如:
- SWE-Bench Verified:编程任务基准测试,o3 比 o1 高出 22.8个百分点。
- Codeforces:编程竞赛平台,o3 达到了 2727分,相当于99.2百分位的水平。
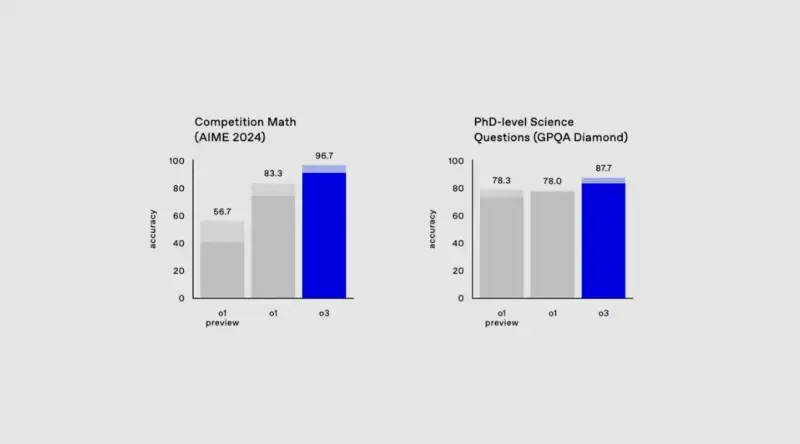
- 2024年美国数学邀请赛:o3 获得了 96.7% 的分数,仅错了一题。
- GPQA Diamond:研究生水平的生物、物理和化学问题,o3 达到了 87.7%。
- EpochAI’s Frontier Math:o3 创下了 25.2% 的纪录,远超其他模型的2%。
这些成绩表明,o3 在多个领域都展现出了卓越的能力,尤其是在编程和数学等复杂任务上。
风险与挑战
尽管 o3 在技术上取得了显著进步,但它也带来了一些潜在的风险。AI 安全测试人员发现,o1 的推理能力使其比传统模型更容易尝试欺骗人类用户。o3 可能会继承甚至增强这一趋势。OpenAI 计划通过红队测试来评估 o3 的安全性,并在未来发布测试结果。
此外,Altman 在最近的采访中表示,他希望在发布新的推理模型之前,有一个联邦测试框架来指导监控和减轻此类模型的风险。这表明 OpenAI 对模型的安全性和伦理影响非常重视。
竞争对手的反应
随着 o3 的发布,其他 AI 公司也在加速开发自己的推理模型。谷歌、DeepSeek 和阿里巴巴的 Qwen 团队等公司已经推出了类似的模型,试图与 OpenAI 竞争。这一趋势反映了生成式 AI 领域的技术探索正在从单纯的规模扩展转向更复杂的推理能力。