腾讯微信人工智能模式识别中心发布DRT-o1系列模型,,这是一个旨在将长链思考(long chain-of-thought,简称CoT)推理能力应用于神经机器翻译(Neural Machine Translation,简称NMT)的模型。DRT-o1特别关注于文学作品中的翻译,尤其是那些包含比喻和隐喻的句子,因为这些句子在不同文化背景下的直译往往无法有效传达原文的意图和情感。
- GitHub:https://github.com/krystalan/DRT-o1
- 模型:🤗 DRT-o1-7B | 🤗 DRT-o1-14B
例如,开发者提到了一个例子,原文是:“The mother, with her feet propped up on a stool, seemed to be trying to get to the bottom of that answer, whose feminine profundity had struck her all of a heap.” 这句话中的“struck her all of a heap”是一个成语,表示某事对她产生了强烈的影响。DRT-o1模型通过长链思考过程,最终将其翻译为“母亲将双脚搭在凳子上,似乎在努力探究那个答案,那答案中女性特有的深刻性令她猛然心生震撼。”,这个翻译不仅传达了原文的意思,还保留了原文的情感色彩。

主要功能:
- 长链思考推理:DRT-o1通过模拟人类的长链思考过程来提高机器翻译的质量,尤其是在处理复杂和隐喻性文本时。
- 多智能体框架:模型使用了一个包含翻译者、顾问和评估者的多智能体框架来迭代改进翻译。
主要特点:
- 针对性的数据收集:DRT-o1专门从文学作品中挖掘包含比喻或隐喻的句子作为翻译的源文本。
- 迭代翻译过程:通过翻译者、顾问和评估者的协作,模型能够迭代地改进翻译,直到达到满意的结果。
- 数据重构:使用GPT-4o对收集到的长链思考翻译数据进行重构,以提高数据的可读性和流畅性。
工作原理:
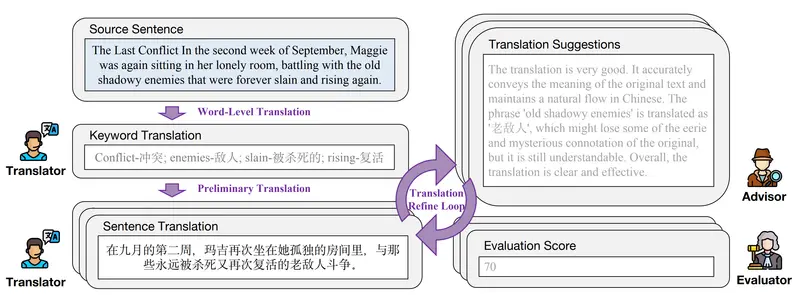
DRT-o1的工作流程包括三个主要步骤:
- 关键词翻译:翻译者首先识别句子中的关键词,并提供它们的翻译。
- 初步翻译:然后,翻译者根据源句子和关键词的双语对应关系提供一个初步的翻译。
- 翻译精炼循环:在精炼循环中,顾问评估前一步的翻译并提供反馈,评估者根据预定义的评分标准给出整体评分。翻译者根据反馈和评分提供新的翻译。当评分达到预定义的阈值或迭代次数达到最大值时,循环停止。
具体应用场景:
- 文学作品翻译:DRT-o1特别适合于翻译那些包含丰富文化元素和隐喻的文学作品,如小说、诗歌和戏剧等。
- 跨文化交流:在需要精确传达原文情感和意图的跨文化交流场合,DRT-o1能够提供更自然、更准确的翻译结果。