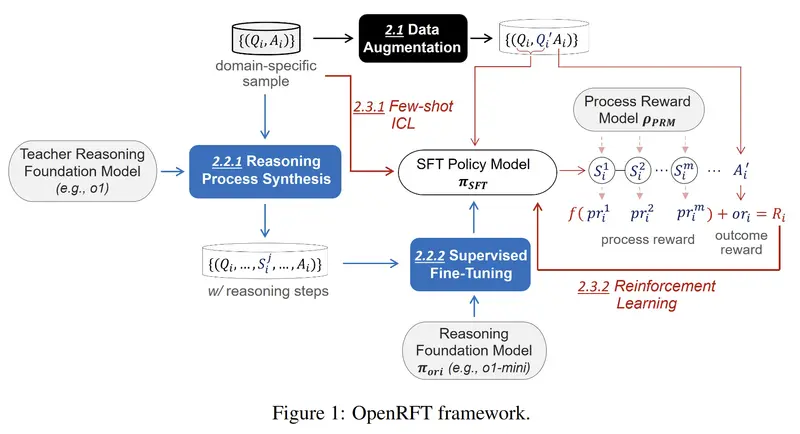
北京交通大学计算机科学与技术学院推出OpenRFT,这是一个旨在将通用推理模型通过强化微调(Reinforcement Fine-Tuning,简称RFT)适应于特定领域任务的框架。OpenRFT通过利用特定领域的样本,解决了缺乏推理步骤数据和训练样本数量有限的挑战,以此来提高模型在特定任务上的表现。
主要功能:
- 数据增强(Data Augmentation):通过改写问题和重新排列选项来生成更多的特定领域数据。
- 基于SFT的模仿学习(SFT-based Imitation):利用更强的推理基础模型合成推理过程数据,然后通过监督式微调(Supervised Fine-Tuning,简称SFT)来预适应学生策略模型。
- 基于RL的探索和自我改进(RL-based Exploration and Self-improvement):将特定领域的样本以少量上下文学习(In-Context Learning,简称ICL)的方式整合到策略模型中,通过过程奖励模型(Process Reward Model,简称PRM)进行过程监督,探索并持续优化策略模型。

主要特点:
- 适应性:能够适应特定领域的任务,通过强化学习减少对初始样本数量的依赖。
- 推理过程合成:合成推理过程数据,以弥补领域特定样本中缺乏推理步骤的不足。
- 过程奖励模型:监督推理过程的合理性,增强正确推理过程的概率,稳定RL训练。
工作原理:
OpenRFT的工作原理基于三个主要模块:
- 数据增强:通过问题重写技术生成更多的领域特定数据。
- 基于SFT的模仿学习:使用教师模型合成推理过程数据,然后使用这些数据通过SFT预适应学生模型。
- 基于RL的探索和自我改进:在RL环境中,策略模型在PRM的过程监督下进行探索和优化。
具体应用场景:
- 科学知识评估:在SciKnowEval这样的科学基准测试中,OpenRFT被用来评估大型语言模型在不同科学领域的多级科学知识。
- 特定领域的任务:如生物学、化学、物理学和材料科学等领域的问题解决和知识推理任务。