文章目录[隐藏]
微软正在加大对小型语言模型(SLMs)的投入,推出了名为rStar-Math的新推理技术。这项技术专门设计用于提升小型模型在解决复杂数学问题上的表现,其性能可与OpenAI的o1-preview模型相媲美,甚至在某些情况下超越后者。
- 论文地址:https://arxiv.org/abs/2501.04519
- GitHub:https://github.com/microsoft/rStar
技术背景与应用实例
尽管rStar-Math目前仍处于研究阶段,但其已成功应用于多个开源的小型模型,包括微软自家的Phi-3 mini、阿里巴巴的Qwen-1.5B和Qwen-7B等。这些模型在涵盖几何、代数等多个分支及不同难度级别的MATH基准测试中表现出色,部分模型的表现甚至超过了OpenAI最先进的模型。
开源计划与社区反馈
研究人员计划将rStar-Math的代码和数据开源,并已在Hugging Face上发布了相关帖子。不过,根据论文作者之一李丽娜的说法,团队仍在进行开源发布的内部审查流程,因此代码库暂时保持私有状态。尽管如此,这一创新已经获得了社区成员的高度评价,尤其是对其结合蒙特卡洛树搜索(MCTS)与逐步推理的方法表示赞赏。
rStar-Math的工作原理
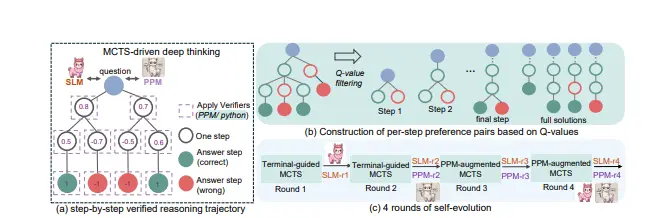
rStar-Math的核心在于利用MCTS来模拟人类“深度思考”的过程,通过迭代优化数学问题的逐步解决方案。研究人员并未直接应用MCTS,而是要求训练后的模型以自然语言描述和Python代码的形式输出其推理步骤。此外,他们还训练了一个策略模型来生成数学推理步骤,并通过一个过程偏好模型(PPM)选择最有希望解决问题的步骤。经过四轮自我进化,这两个模型相互促进,实现了显著的性能提升。
突破性成果
在经过四轮自我进化后,rStar-Math取得了令人瞩目的成绩:
- 在MATH基准测试中,Qwen2.5-Math-7B模型的准确率从58.8%提高到了90.0%,超越了OpenAI o1-preview。
- 在美国数学邀请赛(AIME)中,它解决了53.3%的问题,达到了高中竞赛者前20%的水平。
小型模型的优势与未来展望
近年来,AI的发展主要依赖于大型语言模型的扩展,增加参数被视为提升性能的关键途径。然而,这些庞大模型的高成本(包括计算资源和能源消耗)引发了关于可扩展性的讨论。微软通过rStar-Math展示了小型模型如何能够在特定领域(如数学推理)中实现顶级性能,为行业提供了一种更加高效且经济的选择。
微软同时发布Phi-4和rStar-Math论文,表明紧凑、专门化的模型可以作为大规模系统强有力的替代方案。这不仅挑战了“越大越好”的传统观念,也为中型组织和学术研究人员提供了无需承担庞大模型财务或环境负担即可获得尖端能力的机会。随着rStar-Math等技术的进一步发展,我们有望见证更多高效能小型模型的出现,推动整个行业的进步。