文章目录[隐藏]
在 OpenAI 发布其首个“推理”AI 模型 o1 后不久,用户们发现了一个有趣的现象:该模型有时会用中文、波斯语或其他语言“思考”,即使问题是用英语提出的。这一现象引发了广泛的好奇和讨论。
o1 模型的“思考”过程
当被要求解决一个问题时,例如“‘strawberry’ 这个词中有多少个字母 R?”o1 会开始其“思考”过程,通过一系列推理步骤得出答案。如果问题是用英语提出的,o1 的最终回答也会是英语。但在得出结论之前,模型会用另一种语言执行某些步骤。一位 Reddit 用户指出:“o1 在思考过程中随机开始用中文思考。”
用户的困惑
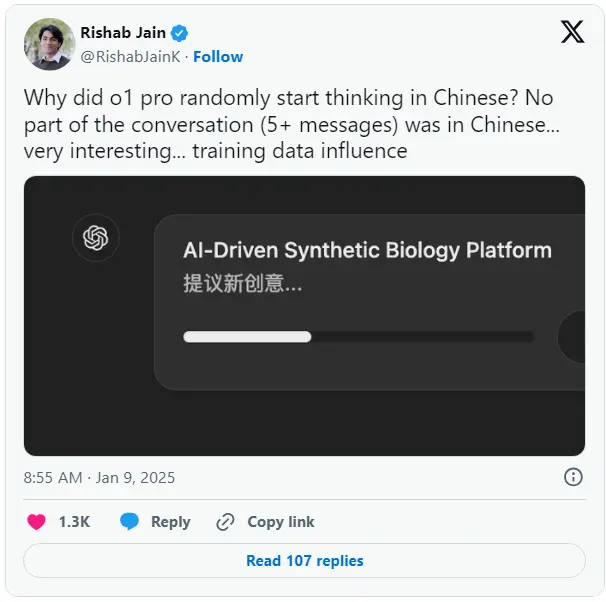
这种现象让许多用户感到困惑。另一位用户在 X 上发帖问道:“为什么 o1 会随机开始用中文思考?整个对话(超过 5 条消息)没有任何部分是用中文的。” OpenAI 尚未对 o1 的这种行为提供官方解释,甚至没有承认这一现象的存在。
AI 专家的理论
AI 专家们对这一现象提出了多种理论。Hugging Face CEO Clément Delangue 和其他几位 X 用户提到,像 o1 这样的推理模型是在包含大量中文字符的数据集上训练的。Google DeepMind 的研究员 Ted Xiao 声称,包括 OpenAI 在内的公司使用第三方中文数据标注服务,而 o1 切换到中文是“中文对推理的语言影响”的一个例子。
Xiao 在 X 上发帖写道:“OpenAI 和 Anthropic 等实验室利用第三方数据标注服务来处理科学、数学和编程领域的博士级推理数据,由于专家劳动力的可用性和成本原因,许多这些数据提供商都位于中国。”
标签和标记的影响
标签(也称为注释或标注)帮助模型在训练过程中理解和解释数据。例如,训练图像识别模型的标签可能以图像中对象周围的标记或描述图像中每个人、地点或对象的标题形式出现。研究表明,带有偏见的标签可能会导致模型产生偏见。例如,普通标注者更有可能将非洲裔美国人白话英语(AAVE)中的短语标记为“有毒”,这导致基于这些标签训练的 AI 毒性检测器将 AAVE 视为不成比例的“有毒”语言。
语言切换的其他解释
然而,其他专家并不认同 o1 中文数据标注的假设。他们指出,o1 在解决问题时同样可能切换到印地语、泰语或其他非中文语言。这些专家认为,o1 和其他推理模型可能只是在使用它们认为最高效的语言来实现目标(或者产生幻觉)。
阿尔伯塔大学 AI 研究员兼助理教授 Matthew Guzdial 告诉 TechCrunch:“模型并不知道什么是语言,也不知道语言之间有何不同,对它来说,所有内容都只是文本。” 事实上,模型并不直接处理单词,而是使用标记(token)。标记可以是单词,例如“fantastic”;也可以是音节,如“fan”、“tas”和“tic”;甚至可以是单词中的单个字符,例如“f”、“a”、“n”、“t”、“a”、“s”、“t”、“i”、“c”。
语言不一致性的可能原因
AI 初创公司 Hugging Face 的软件工程师 Tiezhen Wang 同意 Guzdial 的观点,认为推理模型的语言不一致性可能是由于模型在训练过程中建立的关联。Wang 在 X 上发帖写道:“通过接受每一种语言的细微差别,我们扩展了模型的世界观,使其能够从人类知识的全谱中学习。例如,我更喜欢用中文做数学,因为每个数字只有一个音节,这使得计算清晰高效。但在讨论无意识偏见等话题时,我会自动切换到英语,主要是因为我最初是用英语学习和吸收这些概念的。”
透明度的重要性
但非营利组织 Allen Institute for AI 的研究科学家 Luca Soldaini 提醒说,我们无法确定。“由于这些模型的不透明性,这种对已部署 AI 系统的观察无法得到验证,”他告诉 TechCrunch,“这是为什么 AI 系统构建的透明度至关重要的众多案例之一。”