文章目录[隐藏]
字节跳动的研究团队最近推出了Tarsier2,一款拥有70亿参数的大型视觉语言模型(LVLM),专门针对视频理解中的核心挑战。视频理解一直是人工智能领域的一个复杂问题,因为它不仅需要处理图像信息,还需要理解和分析时间动态和时空关系。
视频理解的核心挑战
与静态图像不同,视频包含了大量的时间和空间信息,这对模型提出了更高的要求。不仅要准确地描述视频内容,还要能够回答关于视频的具体问题,并且避免“幻觉”——即模型虚构细节的问题。尽管已有像GPT-4o和Gemini-1.5-Pro这样的先进模型,但实现真正的人类级别的视频理解仍然面临诸多障碍。
Tarsier2的技术创新与优势
Tarsier2通过一系列技术创新解决了上述挑战:
- 架构设计:Tarsier2由视觉编码器、视觉适配器和一个大型语言模型组成,这三个组件共同工作以提高视频理解能力。
- 三阶段训练过程:
- 预训练:使用了一个包含4000万个视频-文本对的数据集进行预训练,这些数据覆盖了从低级动作到高级情节的各种细节。
- 监督微调(SFT):在这一阶段,Tarsier2进行了细粒度的时间对齐,确保事件与相应的视频帧精确匹配,从而减少幻觉并提高准确性。
- 直接偏好优化(DPO):利用自动生成的偏好数据来优化模型决策,进一步减少幻觉现象。
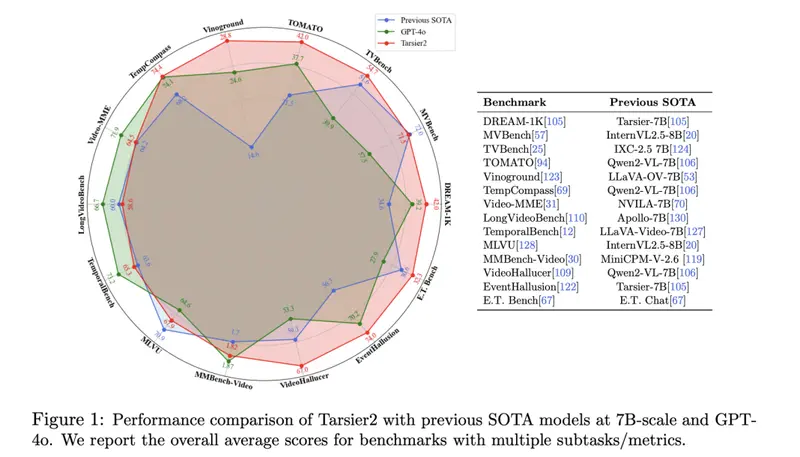
结果与洞察
Tarsier2在多个基准测试中展现了卓越的表现。例如,在DREAM-1K数据集上,它的F1分数比GPT-4o高出了2.8%,比Gemini-1.5-Pro高出5.8%。此外,人类评估显示其性能比GPT-4o高出8.6%,比Gemini-1.5-Pro高出24.9%。它还在E.T. Bench-Grounding测试中以35.5%的平均F1分数领先,展示了其在时间理解方面的强大能力。