
文章目录[隐藏]

科技业这几年几乎每年都涌现出一两个热词,比如NFT、元宇宙、Web3.0等,但你要问近期最热门的是什么?那绝对是AI,代表的就是AI绘画与ChatGPT,各种AIGC(指利用人工智能技术来生成内容)作品已经出现在各大网络平台,尤其是生成的美女图已经快要危险到网络Coser了,这些美女图其实很多都是利用MidJourney、Stable Diffusion 等AI绘图工具生成,其实只要学习一下使用技巧,你也可以轻松生成各种美女照,今天小编就教大家如何免本地安装来使用Stable Diffusion,一起来看看怎么做吧!

Stable Diffusion是什么?
Stable Diffusion是个深度学习以文字生成图片的AI模型,可用于根据文字描述生成详细图像,有别于DALL-E 和 Midjourney 只能透过云端运算服务存取,Stable Diffusion 可以在配备有独立显卡的电脑上执行,并提供源码以及预训练的权重,对使用者而言拥有其生成图像的权利,并可自由的将其用于商业用途。

在Google Colab上建立Stable Diffusion 的 WebUI 环境
如果你想尝试Stable Diffusion,但电脑配置不行怎么办呢?或许可以尝试使用谷歌云端开发环境Google Colab来免费体验。(PS:Google Colab提供了一个免费的GPU/TPU加速器,使用户可以在云端高效地运行大规模计算任务,例如深度学习模型的训练和推理等。此外,用户可以与其他人协作,并轻松地分享他们的笔记本。)
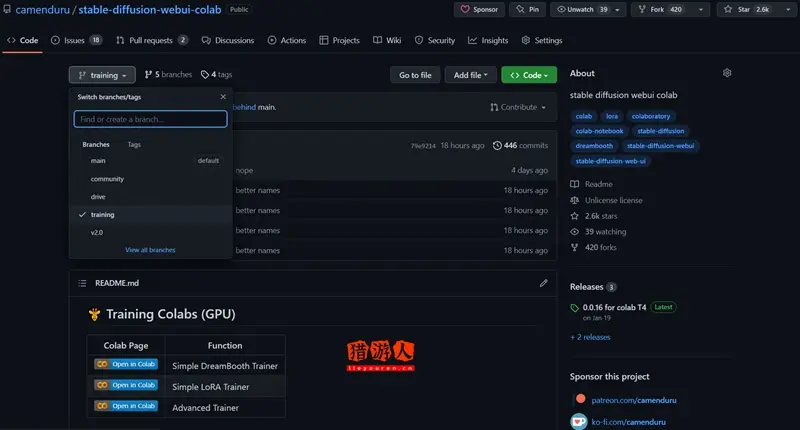
在Github平台上有非常多大神分享了自己的笔记本,大家可以直接套用,当然前提是你有谷歌账号和能够愉快使用这些服务的手段。
一、选择Colab笔记本
目前使用Github上最热门的就要属camenduru分享的Colab笔记本,每个笔记本里面都会有预设的基本模型。
目前毕竟热门的几个如:
- chillout_mix_webui_colab:模型生成的美女偏向亚洲人喜好
- cool_japan_diffusion_2_1_webui_colab:日本动漫风格
- cinematic_diffusion_webui_colab:电影风格
- food_crit_webui_colab:能够更好的生成食物
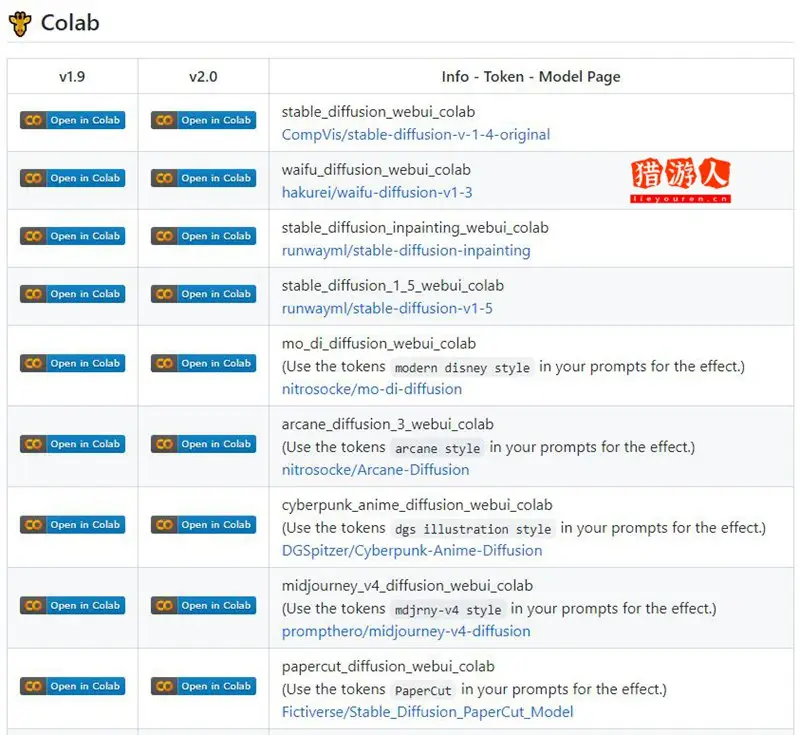
大家可以根据自己的喜好来进行选择,小编就选择「chillout_mix_webui_colab」来给大家做示范。
二、部署Stable Diffusion WebUI
找到「chillout_mix_webui_colab」后,点击左边的「Open In Colab」按钮

进入Google Colab平台后,点击箭头所指的播放按钮,这时候就开始在Google Colab 上架构 Stable Diffusion 的 WebUI 环境,每个笔记本的内容都不同,所以执行的时间不一定,但多在 6~8 分钟左右
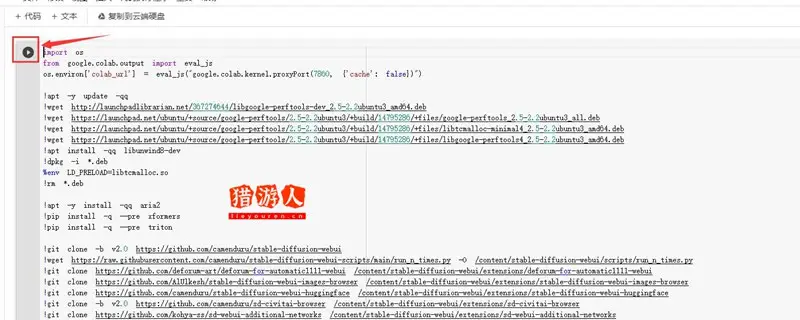
等到 Stable Diffusion WebUI 的架构完成,你会在最下面看到三个网址,点击其中的第二个

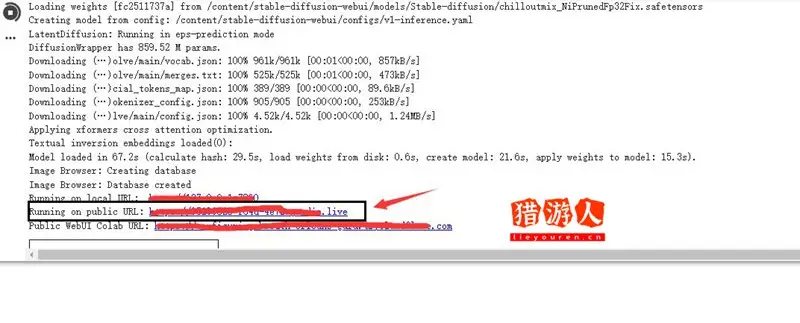
在新打开的页面就可以看到Stable Diffusion 的 WebUI 界面,接着就可以调整参数来生成AI美女图了
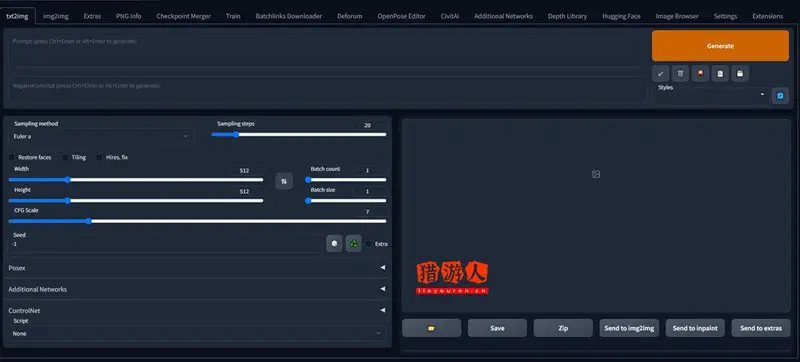
三、Stable Diffusion WebUI 界面說明
Stable Diffusion WebUI 界面是英文的,大家只需要知道几个设置项目,就可以轻松掌握。
1、Prompt 与 Negative Prompt
界面上半部最大的两个框框,上面是 Prompt,下面是 Negative Prompt。
- Prompt:想要看到的内容
- Negative Prompt:不想看到的内容。

比如我想长头发,那就在Prompt的框里输入long hair;不想要胖的,那就在Negative Prompt的框里输入fat
2、参数
下面这个区块就是各种参数的设置,有些可以自行调整,有些则可以保留预设
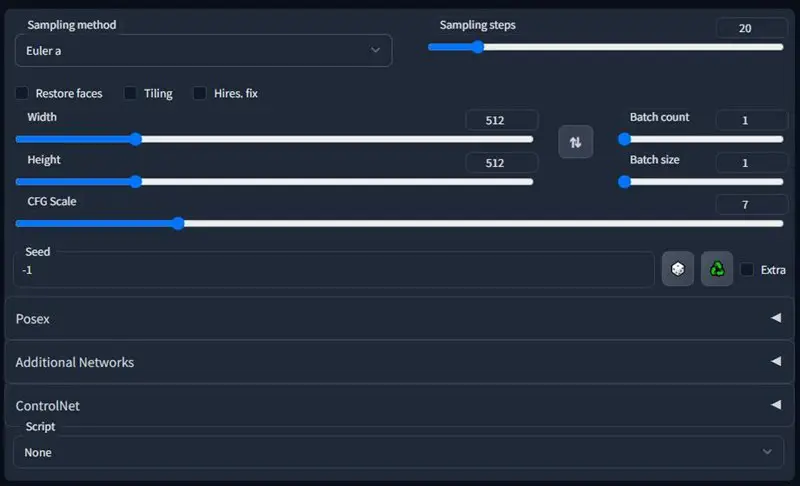
- Sampling Method:取样的方法,会影响照片产生的细节
- Sampling Steps:取样次数,次数越高,花费的时间越久,细节当然也越好
- Restore faces:修正脸部问题
- Hires.fix:修正高取样的情况下,背景变得很奇怪的状况
- Width:图片的宽度
- Height:图片的高度
- Batch count:生成几张图
- Batch size:同时算几张图片
- CFG Scale:要 AI 多么听从你的指令去生成图,这个值越低的话,生成图可能不一定会照你的要求,但可能会有惊喜
- Seed:种子值,可以看作是随意值,在同样的参数下,这个值不同就会产生不同的样子
四、Stable Diffusion WebUI实作教学
接下来就可以按照上面的说明来自己生成美图了
1、输入Prompt 与Negative Prompt
在 Prompt 的地方输入:
a girl is standing in the shower,1girl,unbuttoned shirt,lipstick,hair bun,colored inner hair,shushing,{steam},Looking at Viewer,golden hour lighting,comic,atmospheric perspective,bokeh,detailed,Cinematic light, intricate detail, highres, detailed facial features, high detail, sharp focus, smooth, aesthetic, extremely detailed, stamp, octane render,{{{masterpiece}}}
在 Negative Prompt 的地方输入:
multiple people, lowres, bad anatomy, bad hands, text, error, missing fingers,extra digit, fewer digits, cropped, worstquality, low quality, normal quality,jpegartifacts,signature, watermark, username,blurry,bad feet,cropped,poorly drawn hands,poorly drawn face,mutation,deformed,worst quality,low quality,normal quality,jpeg artifacts,signature,watermark,extra fingers,fewer digits,extra limbs,extra arms,extra legs,malformed limbs,fused fingers,too many fingers,long neck,cross-eyed,mutated hands,polar lowres,bad body,bad proportions,gross proportions,text,error,missing fingers,missing arms,missing legs,extra digit
具体的Prompt可自行研究,也可以参考其他人的设置
2、参数设置
设定生成方法、次数、大小与张数,小编设置参数如下
- Sampling Method:DPM++ SDE Karras
- Sampling Steps:30
- Restore faces:勾选
- Width:512(可自订)
- Height:512(可自订)
- Batch count:2(可自订)
- Batch size:1(可自订)
- CFG Scale:12
- Seed:-1
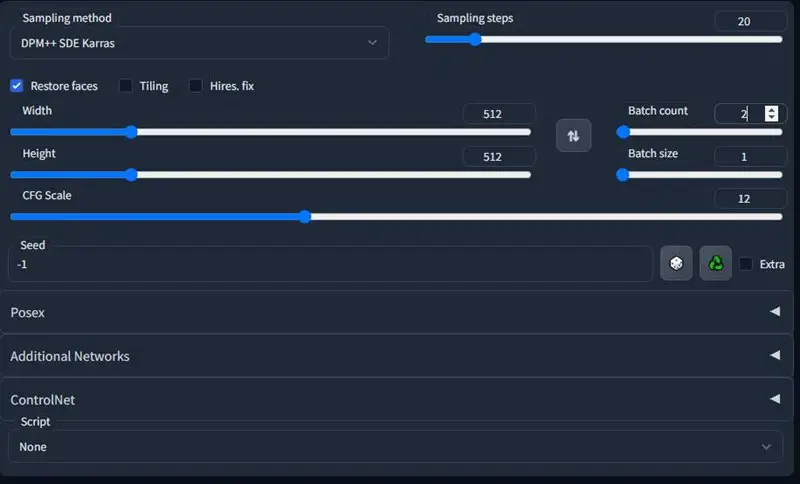
Seed设置为-1 表示随机,如果你用 -1 生成图好看,可以点击右边的绿色按钮,它会把这组图的 Seed 值显示出来。

其实还有其他设置项,如果你不熟悉,直接默认即可,想要进一步的话可以多研究。
五、Stable Diffusion生成最终成果
按照上面的教程设置完成后,就可以点击右上角的「Generate」按钮,让Stable Diffusion按照我们的设置生成图片。

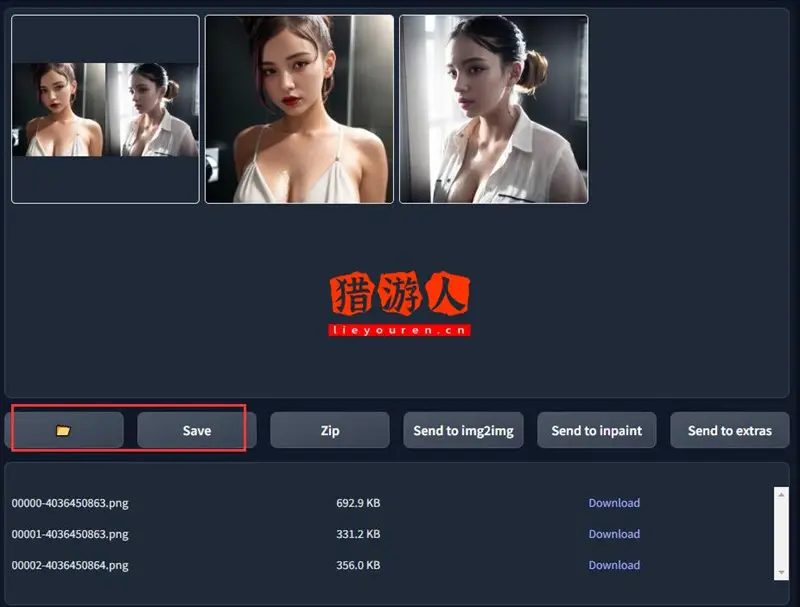
生成图片的时间会依照你设定的图片大小、Steps 数值而有所不同,图片越大、采样次数越多,要生成的图片张数越多需要的时间也就越久。来看看我们生成的图片怎么样:


如果你想保存图片,直接点击图片下方的「Save」就可以看到下方生成的下载链接
六、Prompt参考
如果你英语不好,不知道如何填写Prompt,那么可以透过Civitai网站来找其他人分享的作品,把他们设置的参数作为参考。
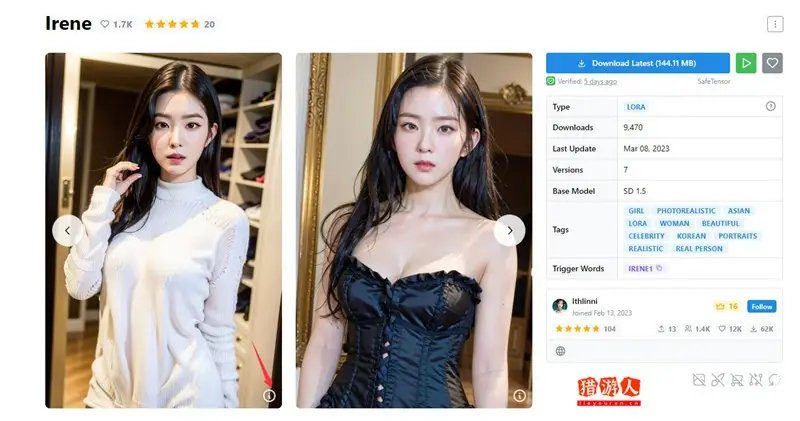
进入网站就可以选择自己喜欢的图片或者搜索喜欢的图片类型,然后点击该图片
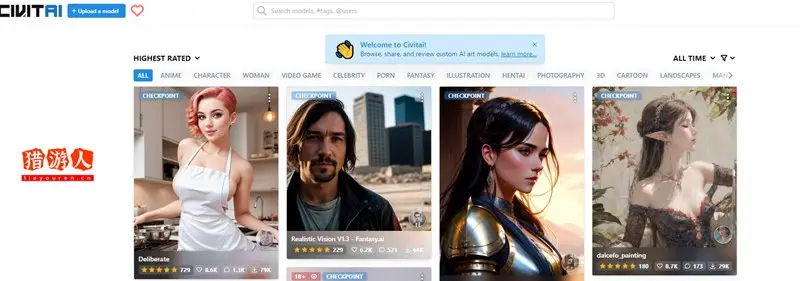
在图片上看到有 i 的小标识,点击就可以看到他设置的参数是哪些
直接复制并且贴到你的 Stable Diffusion WebUI 编辑器就可以了
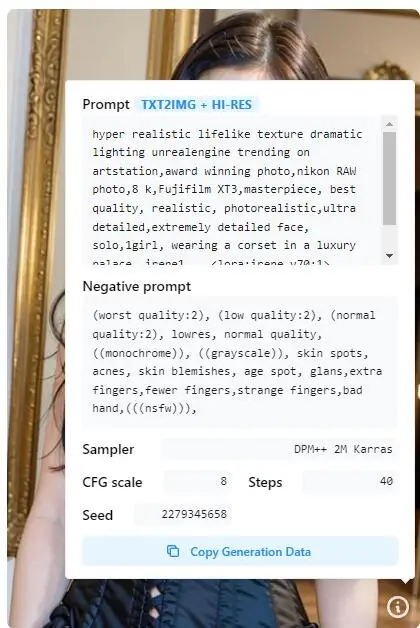
由于基础模型不同,生成的图片可能与Civitai上的完全不同,你也可以使用谷歌翻译或者ChatGPT来把你想要生成的图片的形容词翻译出来,然后让ChatGPT 帮你产生 Stable Diffusion 的 Prompt 指令

总结
这种方法其实比在本地架设Stable Diffusion简单,后续小编还会教大家如何在本地架设Stable Diffusion,Stable Diffusion可以做的事非常多,大家可以根据自己的喜欢来生成各种各样的图片,网上也有非常多的教程可以学习,多操作几次就会发现其实很简单。
