
有别于OpenAI与谷歌的AI研究日益走向封闭,Meta AI依旧保持开放的态度,近短时间已经开源了不少AI模型,像是「Segment Anything」「Animated Drawings」,而在昨天Meta又宣布开源了一种可以将可以横跨6种不同模态的全新AI模型ImageBind,包括视觉(图像和视频形式)、温度(红外图像)、文本、音频、深度信息、运动读数(由惯性测量单元或IMU产生)。目前已公开论文,相关源代码也已托管至GitHub,官方还贴心了提供了演示站点。
论文地址:https://ai.facebook.com/blog/imagebind-six-modalities-binding-ai

[t-info icon='']ImageBind[/t-info]
ImageBind目前只是一个研究项目,展示了未来的人工智能模型如何能够生成多感官内容,尚未有实际应用,但其最终或许有能力让使用者只需输入文字、图像或声音提示,即可生成完整且复杂的场景。ImageBind 可被视为将机器学习更推向人类学习模式的一步进展。举例来说,当人类站在繁忙的街道上,大脑会吸收视觉、听觉等各种感官体验,来推断有关行驶的汽车、行人、高楼大厦、天气的信息。当AI愈来愈擅长模仿动物多种感官间的连结时,即有办法仅凭有限的数据来生成完整的场景。

ImageBind以视觉为核心,可做到6个模态之间任意的理解和转换。Meta展示了一些案例,如听到狗叫画出一只狗,同时给出对应的深度图和文字描述;如输入鸟的图像+海浪的声音,得到鸟在海边的图像。
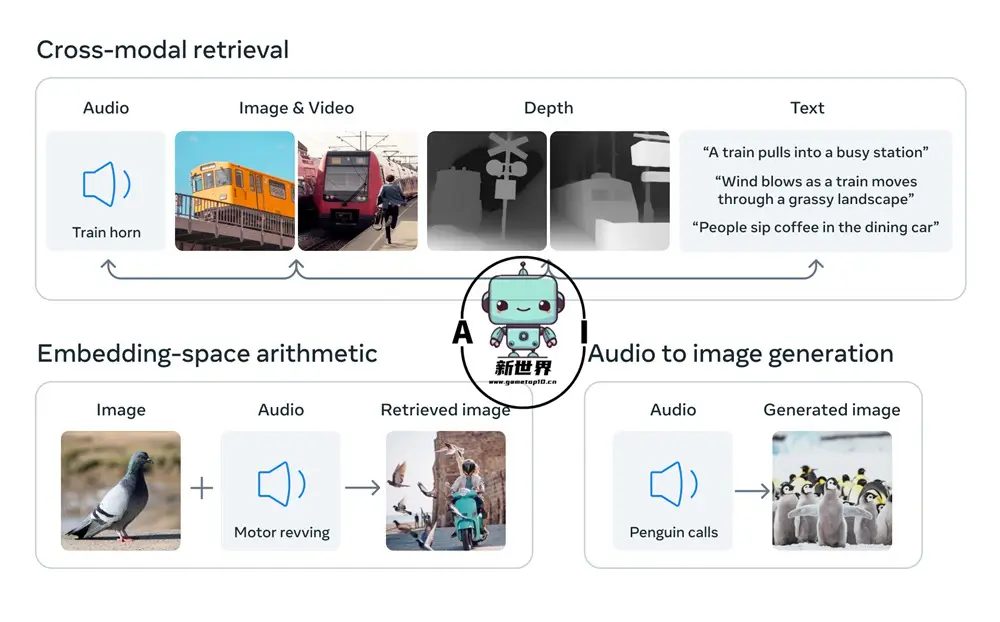
此前的多模态AI模型一般只支持一个或两个模态,且不同模态之间难以进行互动和检索,ImageBind无疑具有突破性意义。Meta称,ImageBind是第一个能够同时处理6种感官数据的AI模型,也是第一个在没有明确监督的情况下学习一个单一嵌入空间的AI模型。
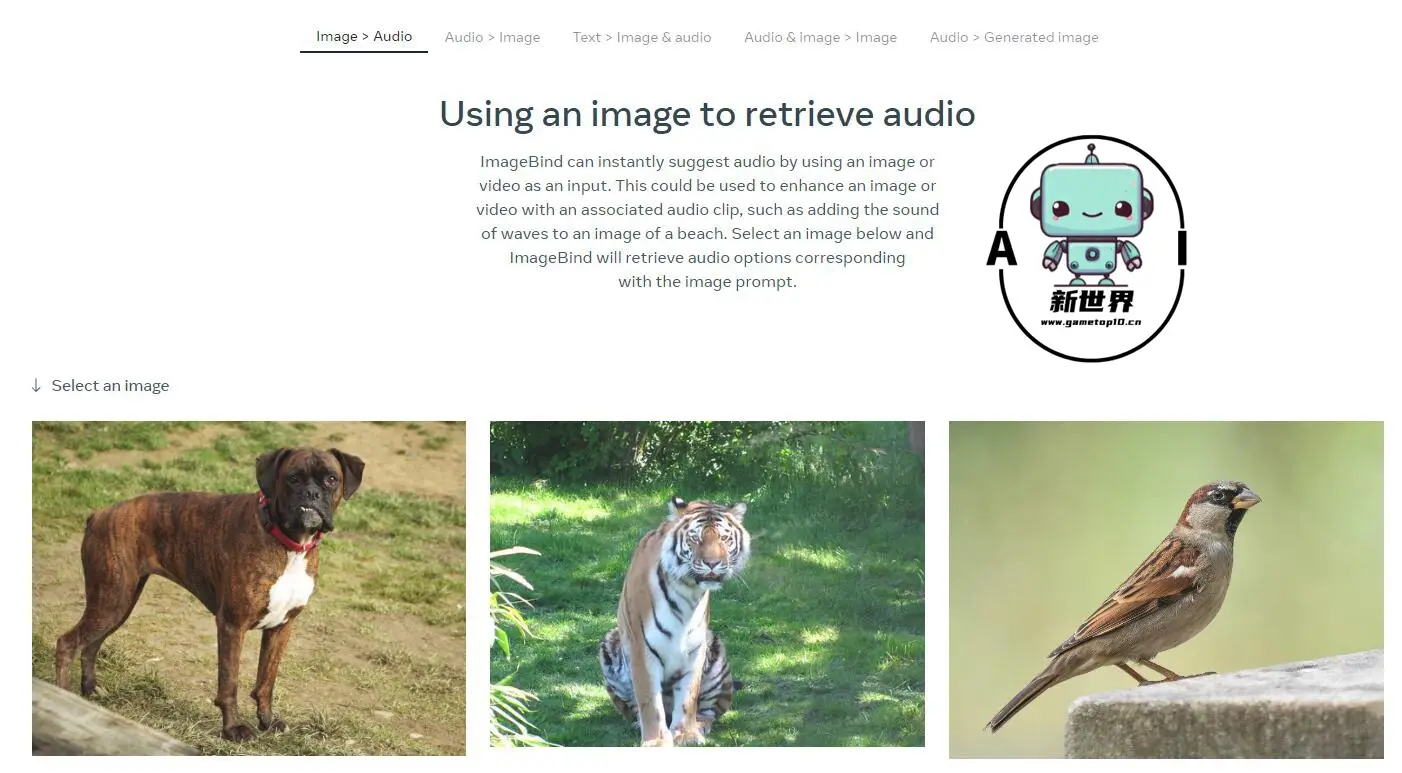
这项 AI 进展也与 Meta 的元宇宙计划息息相关,未来 ImageBind 可应用的场域包括,让 VR 头戴式设备可以快速构建完整的 3D 场景;游戏开发人员可借 AI 减少开发过程中的繁琐设计工作;内容创作者则可以创造逼真的动态背景,同时也有机会帮助患有视觉或听觉障碍的人,以透过各种媒介的描述,助他们感知周围环境。
[t-success icon='']结语[/t-success]
像ImageBind这样的模型使AI更接近人类的水平,它们展示了只要有足够的数据和计算能力,AI就可以开发出类似于人类认知中交织的多感官理解的能力。虽然范围仍然有限,但ImageBind和Meta的相关工作指向了人工通用智能的前景。