
文章目录[隐藏]
文本到语音(TTS)可以说是之前最火的AI之一,像微软语音引擎、讯飞听见等都是比较AI语音服务,已经有不少人使用此类服务进行视频制作,但此类服务还是有不少缺点,像是语气生硬、收费昂贵等。近期一个叫「Bark」的AI语音合成模型上架Github,这是一个开源模型,可以生成类似真人的多语言语音,还能生成音乐、背景噪音等简单的音效,以及可以根据文字内容生成笑、叹息和哭泣、喘息声、清嗓子等声音。

[t-primary icon='']Bark[/t-primary]
Bark 是一款由 Suno 团队开发的开源、生成式文字生成语音模型,与其他「照稿读」TTS不同的是它可以根据文字生成笑、叹息和哭泣等这类情绪表达,能够生成像真人语气、混合多语言朗读、真人对话等,更像真人而非机器。目前Bark 支持 13 种语言,包括英语、德语、西班牙语、法语、印地语、意大利语、日语、韩语、波兰语、葡萄牙语、俄语、土耳其语和汉语,将来还会支持阿拉伯语、孟加拉语和泰卢固语。本来 Bark 也有克隆语音的功能,不过由于担心被用作诈骗,所以 Suno 方面对此功能进行了限制。(点击此链接试听不同语言)
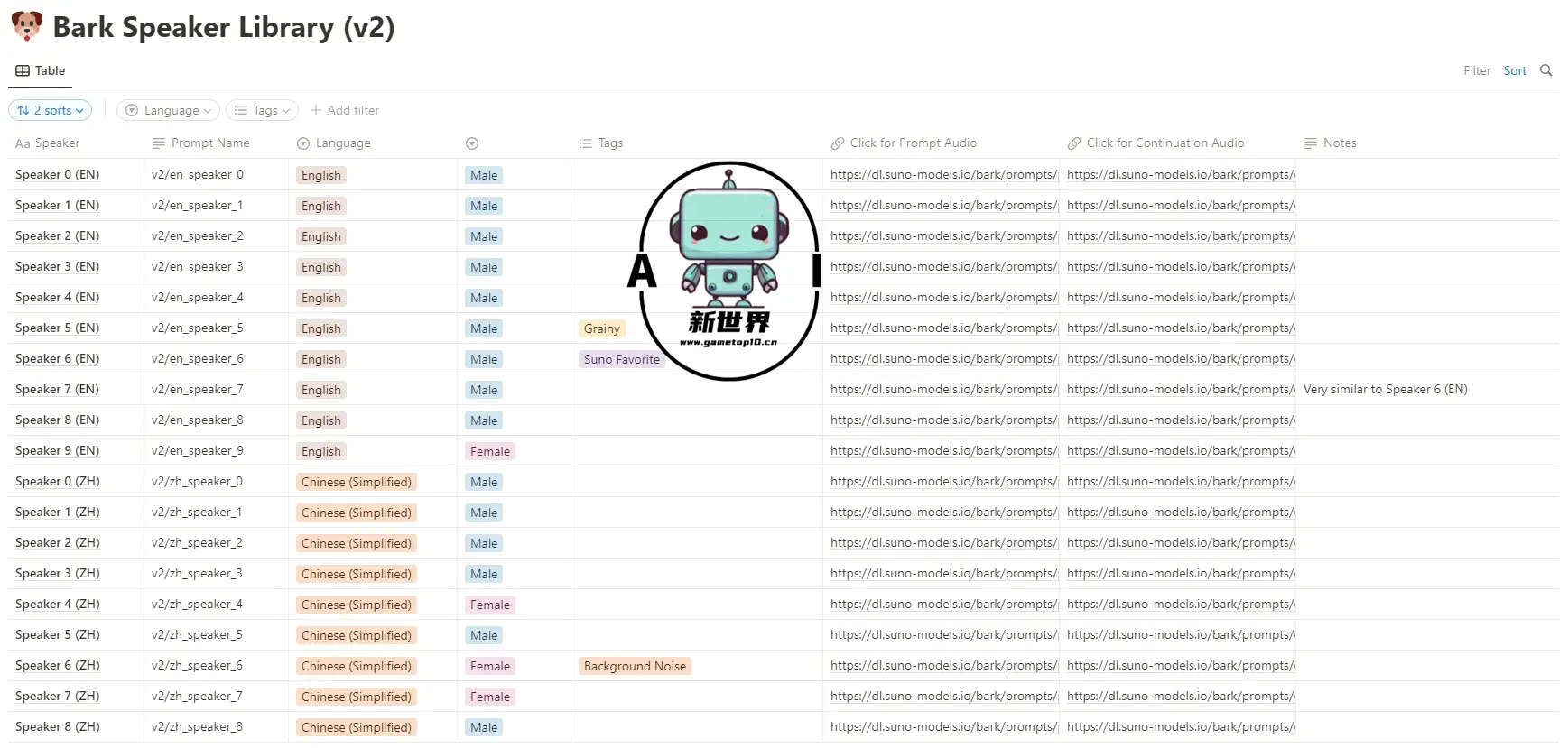
特点:
- 非常真实自然的语音
- 英文效果最佳,其他语言欠佳
- 支持通过文本生成歌曲
- 支持生成背景噪音、简单的音效
- 支持大笑、叹息、哭泣
- 开源模型,自己可以本地架设,也可以去官方排队体验
[t-danger icon='']如何使用Bark?[/t-danger]
Bark是开源模型,使用 MIT 许可证,允许商用。经过官方测试可在 CPU 和 GPU(pytorch 2.0+、CUDA 11.7 和 CUDA 12.0)上运行,如果你的显卡比较老,只能使用较小的模型;完整版Bark需要12GB的显存才能运行。
.png~tplv-t19qeym4ov-resize-crop.webp)
在生成语音时可添加语气和唱歌,只要在输入文字的适当地方插入以下tag 即可:
- [laughter]:大笑
- [laughs]:笑
- [sighs]:叹气
- [mu sic]:音乐
- [gasps]:喘气
- [clears throat]:清嗓子
- - 或 … :忧虑
- 以 ♪ 前后夹住歌词就会唱出(要与歌词留一个空格)
- 全大阶字:强调语气
- MAN/WOMAN:在同一提示句中以两种声线对答
一、在线使用Bark
官方为大家提供了三个在线试用地址,分别是Hugging Face、replicate和谷歌Colab,也可以进入官方服务申请体验。(体验地址)
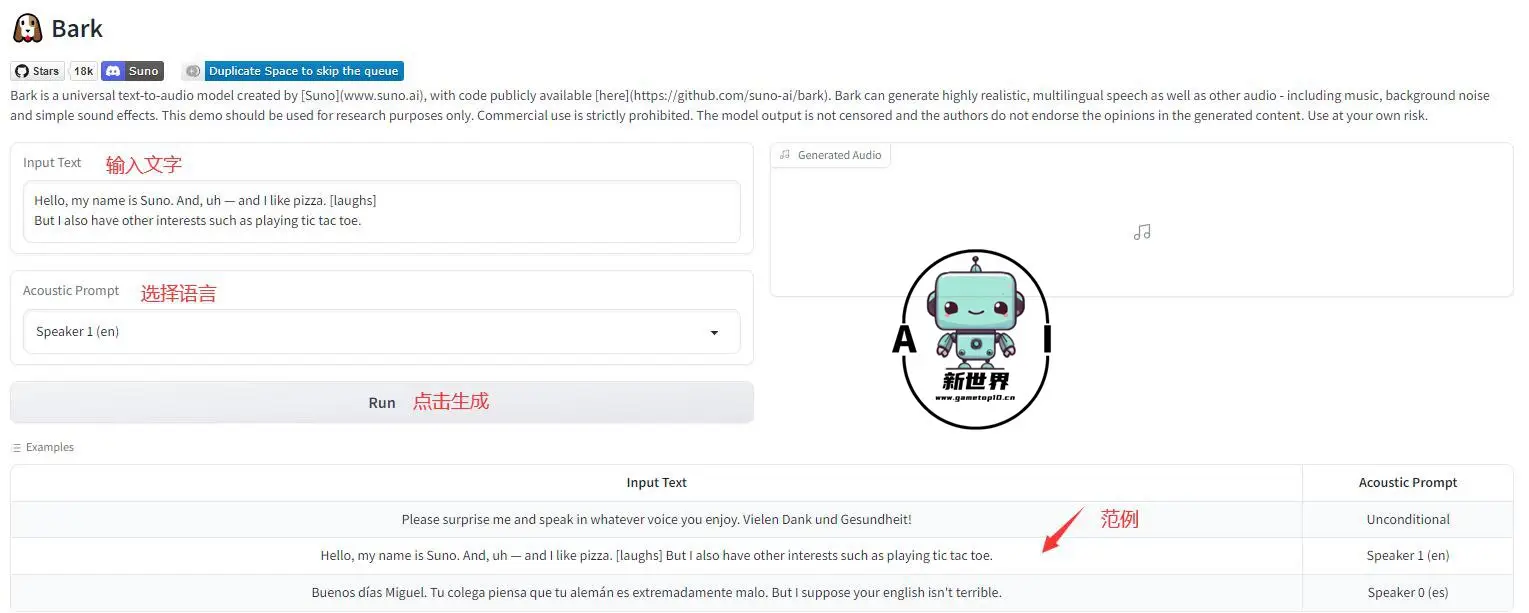
1、Hugging Face
目前提供的Hugging Face试用并不是很快,好的点是可以选择语言和语调,目前每种语言都可以选择10种不同的语调。
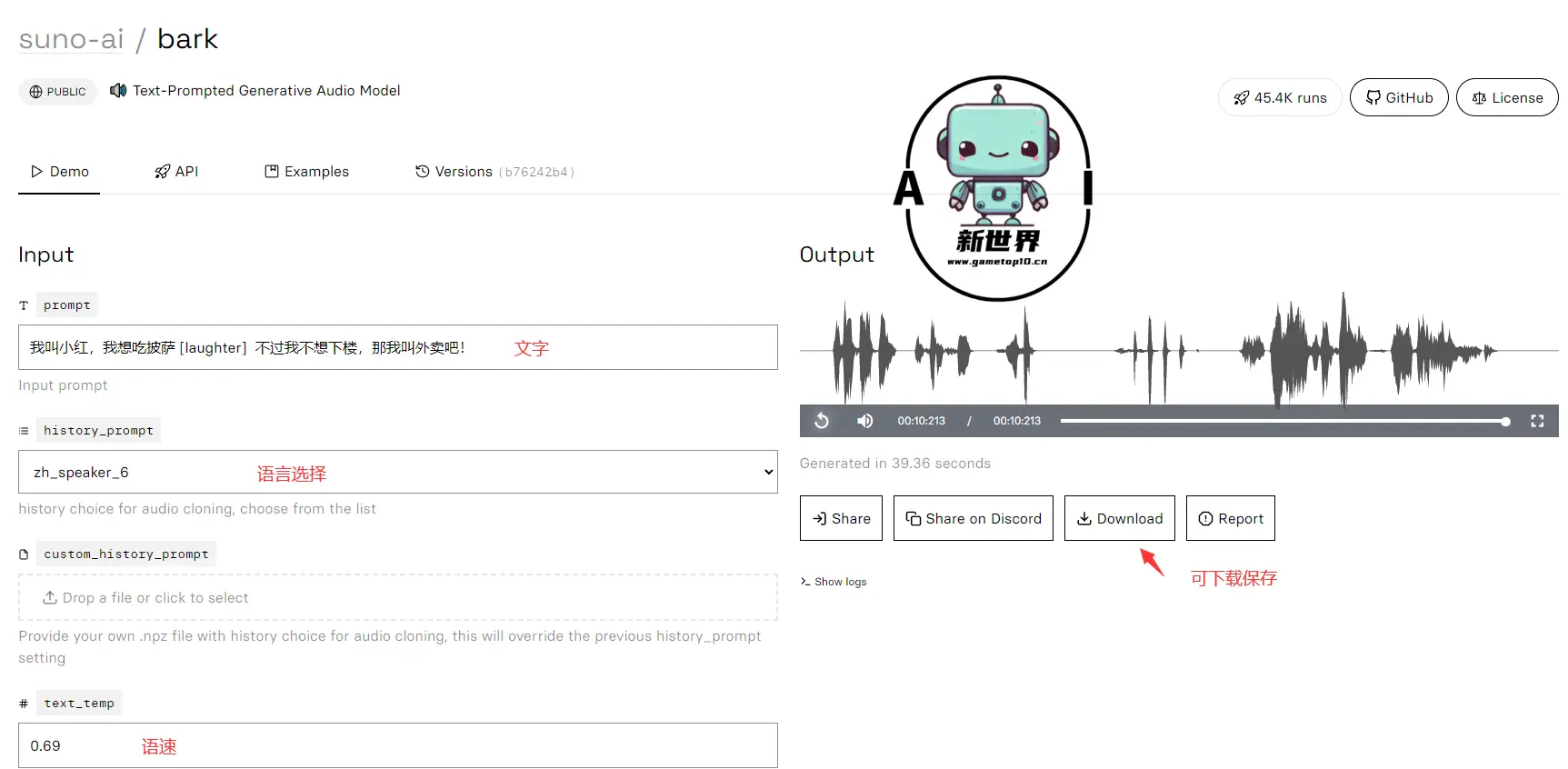
2、replicate
该试用地址提供了更多的选项,比如语速,还可以下载保存生成的语音。
3、谷歌Colab
地址:https://colab.research.google.com/drive/1eJfA2XUa-mXwdMy7DoYKVYHI1iTd9Vkt?usp=sharing
依照要求进行在线安装,Install和Basics这两步,安装大概需要七八分钟,安装完后就可以在案例处进行修改,然后生成语音。
.png~tplv-t19qeym4ov-resize-crop.webp)
二、本地安装
此类开源模型,还是要自己在电脑上安装才能发挥最大功能,后续会有很多高手为它开发插件,如果你的条件允许,还是建议本地安装来体验此模型,不过在进行本地安装前,你还需要先安装以下工具git、Terminal、Python和 CUDA Toolkit,根据自己的电脑配置进行安装。(PS:以下的教程安装可能都行科学上网环境或者代理才可进行下载)
git:https://git-scm.com/downloads
Terminal:https://github.com/microsoft/terminal/releases
1、官方教程
(1)安装
pip install git+https://github.com/suno-ai/bark.git
或
git clone https://github.com/suno-ai/bark
cd bark && pip install . (2)使用Python执行以下代码
from bark import SAMPLE_RATE, generate_audio
from IPython.display import Audio
# 使用文字生成语音
text_prompt = """
Hello, my name is Suno. And, uh — and I like pizza. [laughs]
But I also have other interests such as playing tic tac toe.
"""
audio_array = generate_audio(text_prompt)
Audio(audio_array, rate=SAMPLE_RATE)要保存audio_array为 WAV 文件:
from scipy.io.wavfile import write as write_wav
write_wav("/path/to/audio.wav", SAMPLE_RATE, audio_array)PS:使用Python执行代码时,会识别电脑上有无显卡,如果没有显卡则会下载可用于CPU的训练模型,默认模型文件下载地址为当前用户目录.cache文件夹下,可以通过配置XDG_CACHE_HOME环境变量指定模型下载位置
2、一键整合包
如果嫌官方的版本安装比较麻烦的话,可以使用网友提供的一键整合包[Bark Web UI] ,进入 Bark Web UI 的 Github Release 页面后点击最新版本的「► Assets」打开可供下载的文档,下载当中的「Bark_WebUI.7z」。
.png~tplv-t19qeym4ov-resize-crop.webp)
(1)在一个电脑容量比较大的盘新建文件夹把「Bark_WebUI.7z」放进去,然后解压后进入解压出来的「Bark_WebUI」文件夹,点击其中的 run.bat 即开始安装
.png~tplv-t19qeym4ov-resize-crop.webp)
(2)安装完成 Miniconda 虚拟执行环境之后,就会问你有没有英伟达显卡,回答y,然后就会安装负责AI运算的 Pytorch 和相关软件
.png~tplv-t19qeym4ov-resize-crop.webp)
(3)安装完毕后,关闭此窗口,然后再次点击run.bat进行加载,加载完后就可以在浏览器打开网址(http://127.0.0.1:7860),就可以使用Bark Web UI
.png~tplv-t19qeym4ov-resize-crop.webp)
(4)使用方法
在Prompt里输入文字,根据输入文字所属语言,在Voice处选择对应语言,然后点击 Launch即可生成语音,首次生成会进行模型下载,完成后就会在Result 区域看到生成的语音。由于每次生成时,语音内容都会以 audio.wav 为名存储在 Bark_WebUI 文件夹里,如果想保存语音,需要点击播放器右方的「⋮」进行下载
.png~tplv-t19qeym4ov-resize-crop.webp)
3、增强版
上面两种方式,如果不进行一些设置,那么就只能生成最长15 秒语音,而且很容易爆显存。另一位开发者JonathanFly就为大家提供了Bark Infinity,虽然没有用户界面,但突然了15秒限制可以让大家生成更长的语音。
(1)同样是选择一个容量大的盘,新建文件夹命名为Bark,进入此文件夹后,在文件夹地址栏输入CMD,打开一个命令提示符,然后输入以下代码进行下载
git clone https://github.com/JonathanFly/bark.git
(2)下载完成后,输入cd bark进入下载目录库,输入
pip install -r requirements-pip.txt安装必要组件,输入
pip install encodec rich-argparse安装必要组件,安装完成后即可关闭
.png~tplv-t19qeym4ov-resize-crop.webp)
(3)然后回答Bark文件夹,点击bark_webui文件,然后就可以进入给出的网址
.png~tplv-t19qeym4ov-resize-crop.webp)
(4)进入网址(http://127.0.0.1:7860)后,就可以根据页面进行设置与生成
.png~tplv-t19qeym4ov-resize-crop.webp)
[t-warning icon='']结语[/t-warning]
以上几种方法大家都可在开源页面看到教程,目前Bark对于英文生成的效果很好,但中文效果就很生硬,而且杂音很大,如果生成的语音有杂音,大家可以使用Adobe Podcast Beta 版提供的免费语音增强功能「Speech Enhancement」去除杂音。随着Bark的发展相信之后生成效果会更好,而且作为开源模型,肯定会有高手进行插件的开发,对于不足之处进行改进。
.png~tplv-t19qeym4ov-resize-crop.webp)