文章目录[隐藏]
- [t-success icon='']AI·快讯[/t-success]
- 1、百川智能发布Baichuan-13B
- 2、GenAI全资子公司获准加入英伟达初创加速计划
- 3、Transformer论文共同作者、谷歌AI研究员Llion Jones将离职创业
- 4、美图秀秀宣布AI 扩图功能上线,可生成更大画幅图片
- 5、腾讯 AI 登顶国际麻将平台并刷新全球最好成绩
- 6、Google DeepMind 学者研发Focused Transformer ,扩展大模型输出长度限制
- 7、英伟达将占AI芯片市场至少九成份额
- 8、GPT-4被破解,训练成本,模型架构的秘密都被挖出来了?
- 9、微软推出人工智能模型CoDi,可互动和生成多模态内容
- 10、微软 Edge 浏览器内 Bing Chat 将支持聊天记录功能
- 11、消息称谷歌已与多家医院合作开展测试,共同探索 AI 医疗可能性
- 12、1000 万张照片训练 AI 模型,科学家找到水下定位新方法
- 13、微软在 Build 大会上宣布的新 Microsoft Store AI Hub 现已开始推出
[t-success icon='']AI·快讯[/t-success]
1、百川智能发布Baichuan-13B
7月11日,百川智能正式发布参数量130亿的通用大语言模型Baichuan-13B-Base、对话模型Baichuan-13B-Chat及其INT4/INT8两个量化版本。据介绍,Baichuan-13B中英文大模型集高性能、完全开源、免费可商用等于一身。Baichuan-13B 是由百川智能继 Baichuan-7B 之后开发的包含 130 亿参数的开源可商用的大规模语言模型,在中英文 Benchmark 上均取得同尺寸模型中最好的效果。本次发布包含有预训练 (Baichuan-13B-Base) 和对齐 (Baichuan-13B-Chat) 两个版本。(来源:36氪)
Baichuan-13B 有如下几个特点:
- 更大尺寸、更多数据:Baichuan-13B 在 Baichuan-7B 的基础上进一步扩大参数量到 130 亿,并且在高质量的语料上训练了 1.4 万亿 tokens,超过 LLaMA-13B 40%,是当前开源 13B 尺寸下训练数据量最多的模型。支持中英双语,使用 ALiBi 位置编码,上下文窗口长度为 4096。
- 同时开源预训练和对齐模型:预训练模型是适用开发者的『 基座 』,而广大普通用户对有对话功能的对齐模型具有更强的需求。因此本次开源我们同时发布了对齐模型(Baichuan-13B-Chat),具有很强的对话能力,开箱即用,几行代码即可简单的部署。
- 更高效的推理:为了支持更广大用户的使用,我们本次同时开源了 int8 和 int4 的量化版本,相对非量化版本在几乎没有效果损失的情况下大大降低了部署的机器资源门槛,可以部署在如 Nvidia 3090 这样的消费级显卡上。
- 开源免费可商用:Baichuan-13B 不仅对学术研究完全开放,开发者也仅需邮件申请并获得官方商用许可后,即可以免费商用。
GitHub:https://github.com/Baichuan-inc/Baichuan-13B
HuggingFace:https://huggingface.co/baichuan-inc/Baichuan-13B-Chat
Model Scope:https://modelscope.cn/models/Baichuan-inc/Baichuan-13B-Chat

2、GenAI全资子公司获准加入英伟达初创加速计划
GenAI公司7月10日宣布,全资子公司Pulse AI已获准加入英伟达初创加速计划,并已发出采购订单,购买价值约180万美元的硬件,每年可提供超过35万小时的人工智能计算时间。
3、Transformer论文共同作者、谷歌AI研究员Llion Jones将离职创业
帮助撰写了开创性人工智能论文《注意力就是你所需要的一切(Attention Is All You Need)》的Llion Jones证实,他将于本月晚些时候离开谷歌日本,并计划在休假后创办一家公司。该论文于2017年发表,介绍了Transformer的概念,该系统可以帮助AI模型在它们正在分析的数据中锁定最重要的信息。Transformer现在是大型语言模型的关键构建模块,这一技术支撑着如OpenAI旗下ChatGPT等广为流行的AI产品。这几年间,该论文的作者们创办了一些知名初创公司,其中包括为企业客户提供大型语言模型的Cohere,以及聊天机器人公司Character.AI。
![]()
4、美图秀秀宣布AI 扩图功能上线,可生成更大画幅图片
美图秀秀官方今天宣布,现已在美图秀秀 App 和 Wink App上线AI 扩图功能。据美图秀秀官方表示,该功能基于 AI 算法智能识别,可根据图像的上下文和纹理,预测、生成缺失的部分,能够为原始图片带来更大画幅、更广视角。(来源:IT之家)

5、腾讯 AI 登顶国际麻将平台并刷新全球最好成绩
腾讯今天宣布,腾讯 AI 登顶国际麻将平台,在日本麻将天凤平台特上房达到稳定段位 10.68 段,刷新了 AI 在麻将领域取得的最好成绩。据悉,腾讯 AI 绝艺 LuckyJ 之所以去日本打比赛,是因为“天凤”是知名的日本麻将竞技平台,拥有较为体系化的竞技规则和专业段位规则,受到“职业麻将界的广泛认可”,全世界的麻将 AI 基本都在这里进行训练和打段。目前排名前三的麻将 AI 分别为绝艺 LuckyJ、Suphx 以及 NAGA。(来源)

6、Google DeepMind 学者研发Focused Transformer ,扩展大模型输出长度限制
据 Arxiv 页面显示,Google DeepMind 研究团队近日联手华沙大学和波兰科学院等机构,研发一项名为 Focused Transformer 的技术。Focused Transformer 技术旨在通过对比训练来扩展上下文长度的方法,可以用于大型语言模型。Focused Transformer 技术通过对比训练来增强 (key, value) 空间的结构,从而扩展了上下文长度。这项技术使得已经预训练的大型语言模型可以被重新训练来延长它们的有效上下文。论文显示,研究团队使用一款名为 LongLLaMA 的大模型进行测试。经过实验,研究团队已经成功使用 LongLLaMA 模型在密码检索任务中实现了256K的上下文长度。
![]()
7、英伟达将占AI芯片市场至少九成份额
花旗研究分析师Christopher Danely在周一的报告中表示,英伟达将占据AI芯片市场“至少90%”的市场份额,AMD位居第二。Danely指出,上一代AI芯片(分别是MI250和A100) 中,AMD的硬件速度大约是英伟达的80%,而英伟达的H100与AMD的MI300相比,也具有类似的优势。此前有消息称,英伟达的A100和H100 GPU由台积电独家供应,三星电子未能抢下任何订单,原因是台积电的先进封装技术CoWoS领先三星电子。(来源:IT之家)
8、GPT-4被破解,训练成本,模型架构的秘密都被挖出来了?
几个小时前SemiAnalysis的DYLAN PATEL和DYLAN PATEL发布了一个关于GPT-4的技术信息,包括GPT-4的架构、参数数量、训练成本、训练数据集等。本篇涉及的GPT-4数据是由他们收集,并未公开数据源。(来源:品玩)
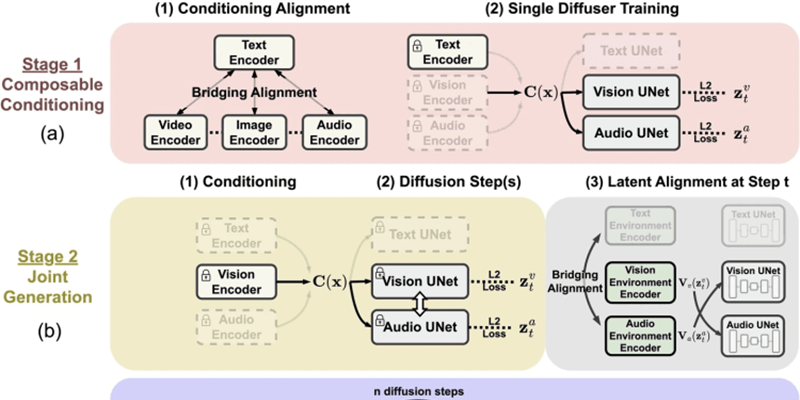
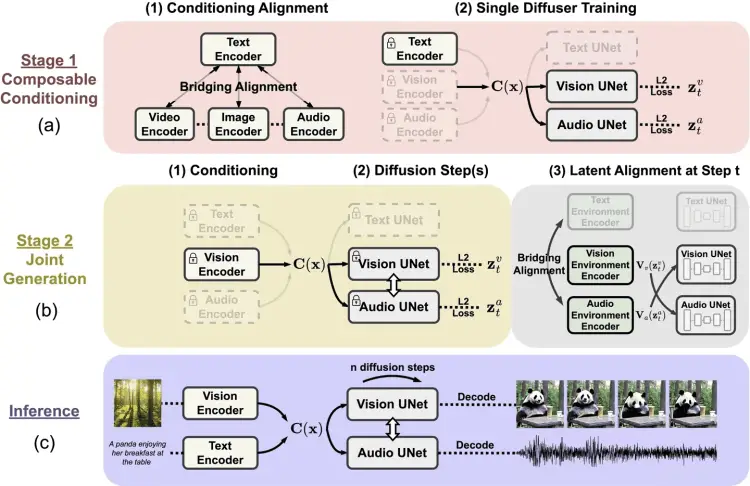
9、微软推出人工智能模型CoDi,可互动和生成多模态内容
微软近日发布新闻稿,推出了名为可组合扩散模型(CoDi),这是一种独特的、基于可组合扩散的人工智能模型,其设计目标是互动和生成多模态内容。微软设计CoDi的目标,旨在解决传统单一模态AI模型的局限性。以同步视频和音频为例,独立生成的信息流拼接在一起时可能存在不一致和对齐的问题。CoDi 采用了独特的可组合生成策略,在扩散过程中对齐多模态,从而生成相互交织的模式,更重要的是,CoDi 能够处理任意输入模式并生成任意模态的内容。(来源:IT之家)
10、微软 Edge 浏览器内 Bing Chat 将支持聊天记录功能
微软广告和网络服务首席执行官 Mikhail Parakhin 近日在回复网友提问时,明确表示必应聊天(Bing Chat)的聊天记录功能将登陆 Edge 浏览器。一位推特网友询问 Parakhin:“如果 Edge 侧边栏上的必应也能‘记忆’对话内容,那真的太好了”,Parakhin:“没错,这项功能即将到来”。

11、消息称谷歌已与多家医院合作开展测试,共同探索 AI 医疗可能性
据《华尔街日报》报道,谷歌日前已经和多家医院合作,测试其基于 Med-PaLM 2 模型的诊疗机器人。据悉,谷歌用于医用的诊疗机器人是以 Med-PaLM 2 模型为基础,该 Med-PaLM 2 模型是 IT之家此前报道的谷歌 PaLM 2 模型“医用版本”,谷歌使用“医师执照考试问答题”为训练集训练而成,并经过医院相关专家多次内部测试,于当前进入线下临床测试阶段。(来源:IT之家)

12、1000 万张照片训练 AI 模型,科学家找到水下定位新方法
北斗、GPS 等卫星系统可以精准定位地表位置,但在水下就无能为力了。伊利诺伊大学厄巴纳-香槟分校的科学家近日通过分析水下光偏振模式,找到了在没有定位系统的情况下,在水下导航的方法。该大学团队使用具有特殊光学元件的水下相机在多个地点拍摄了大约 1000 万张照片,是在不同的条件下、不同的日期、不同的深度和一天中的不同时间拍摄的。团队开发了人工智能算法,并使用上述照片进行训练,可以在最深 300 米以上进行水下定位,识别精度在 40-50 公里。
论文地址:https://elight.springeropen.com/articles/10.1186/s43593-023-00050-6

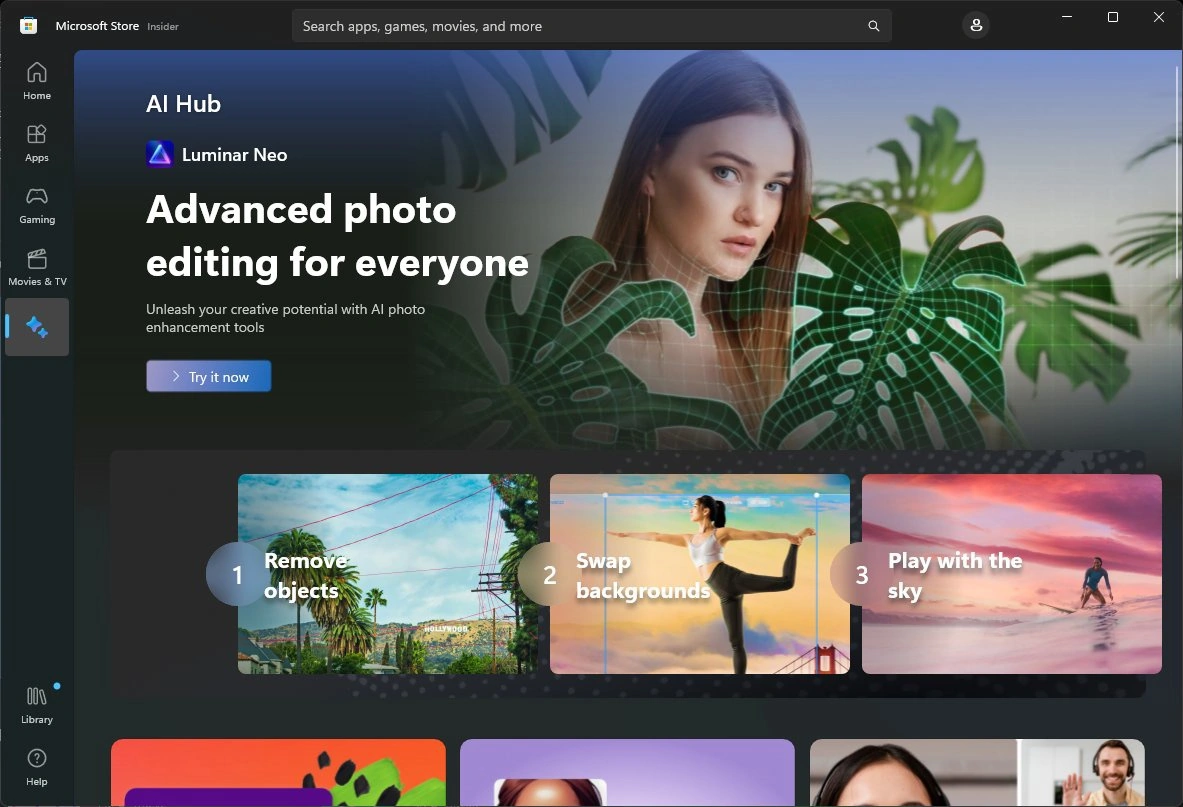
13、微软在 Build 大会上宣布的新 Microsoft Store AI Hub 现已开始推出
现有网友发现,微软之前在 Build 大会上宣布的新 Microsoft Store AI Hub 功能现已开始面向 Canary 用户以及 Dev 用户推出(应用商店版本 22306.1401.1.0)。感兴趣的用户现在可以打开应用商店看一下,如果没有看到 AI Hub 可在重置 Microsoft Store 后再尝试。(来源:IT之家)