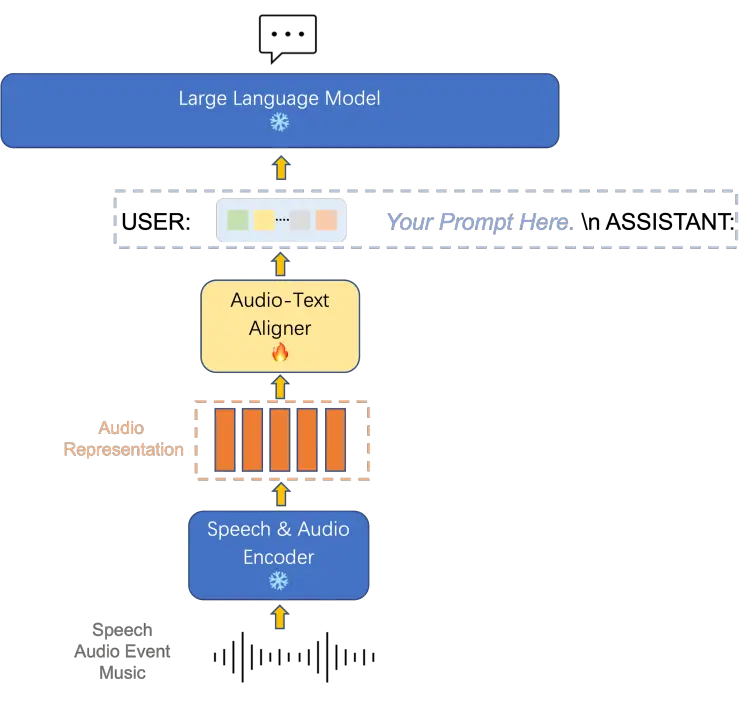
由清华大学电子工程系与字节跳动旗下火山语音团队合作开发的开源听觉大语言模型SALMONN,目前已经上架GitHub并释出试玩Demo,不过代码、模型并未放出,官方也表示很快会释出。SALMONN是一个支持语音、音频以及音乐输入,它可以感知和理解不同类型的音频内容输入,并具备多语言语音识别和翻译以及语音推理等功能。
GitHub地址:https://github.com/bytedance/SALMONN
官方表示,目前 SALMONN 能够胜任英语语音识别、英语到中文的语音翻译、情感识别、音频字幕生成、音乐描述等重要的语音和音频任务,同时又涌现出多种在模型训练中没有专门学习过的多语言和跨模态能力,涵盖非英语语音识别、英语到(中文以外)其他语言的语音翻译、对语音内容的摘要和关键词提取、基于音频的故事生成、音频问答、语音和音频联合推理等任务。
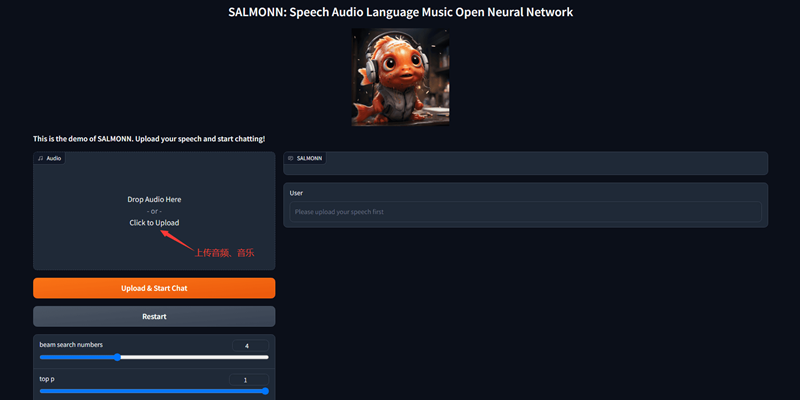
如何使用SALMONN?
打开试玩地址后,上传音频或者音乐,然后点击【Upload & Start Chat】进行上传
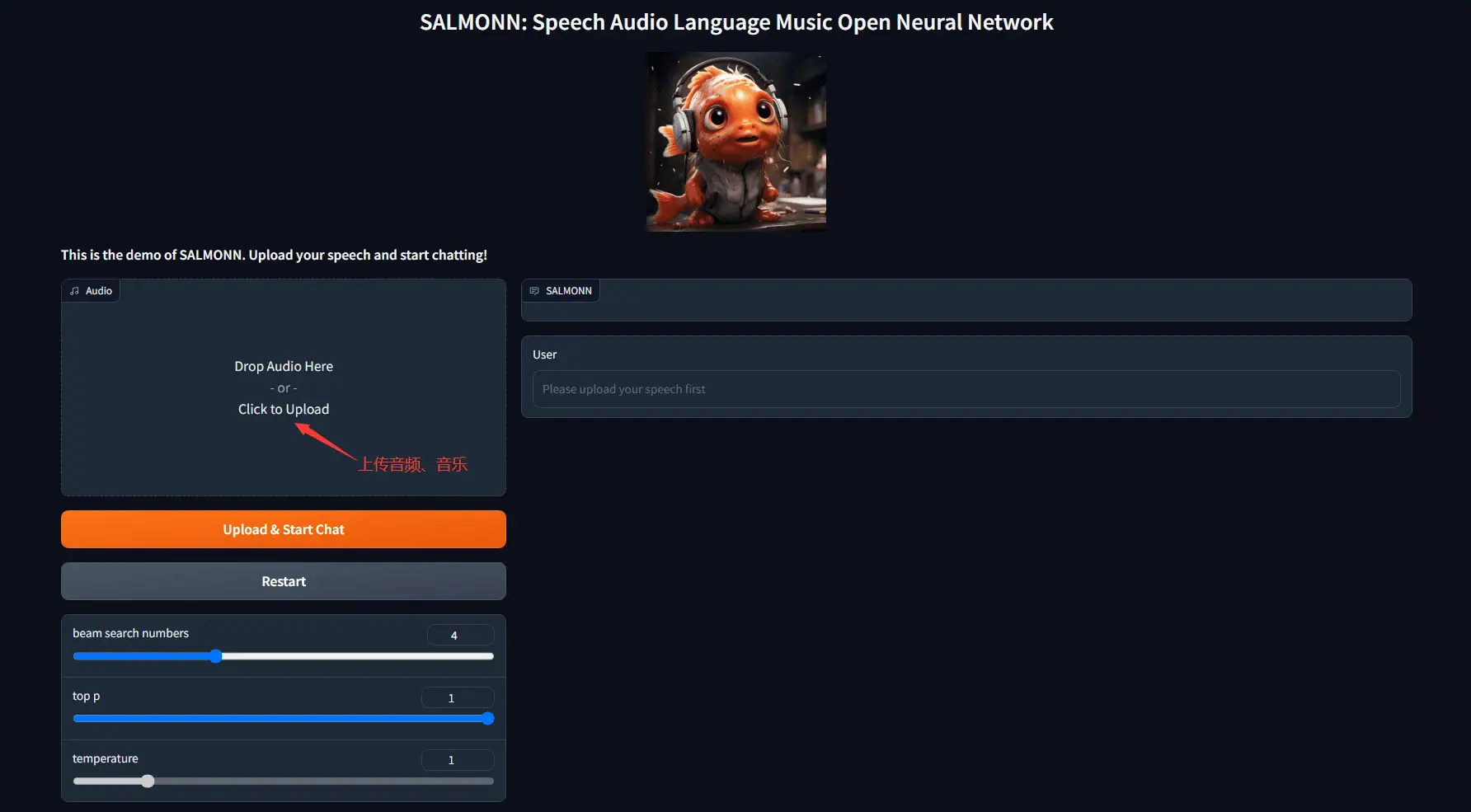
然后就可以输入问题进行提问,支持中文进行提问,可惜的是目前好像不支持连续提问功能,上传后仅支持进行一次提问
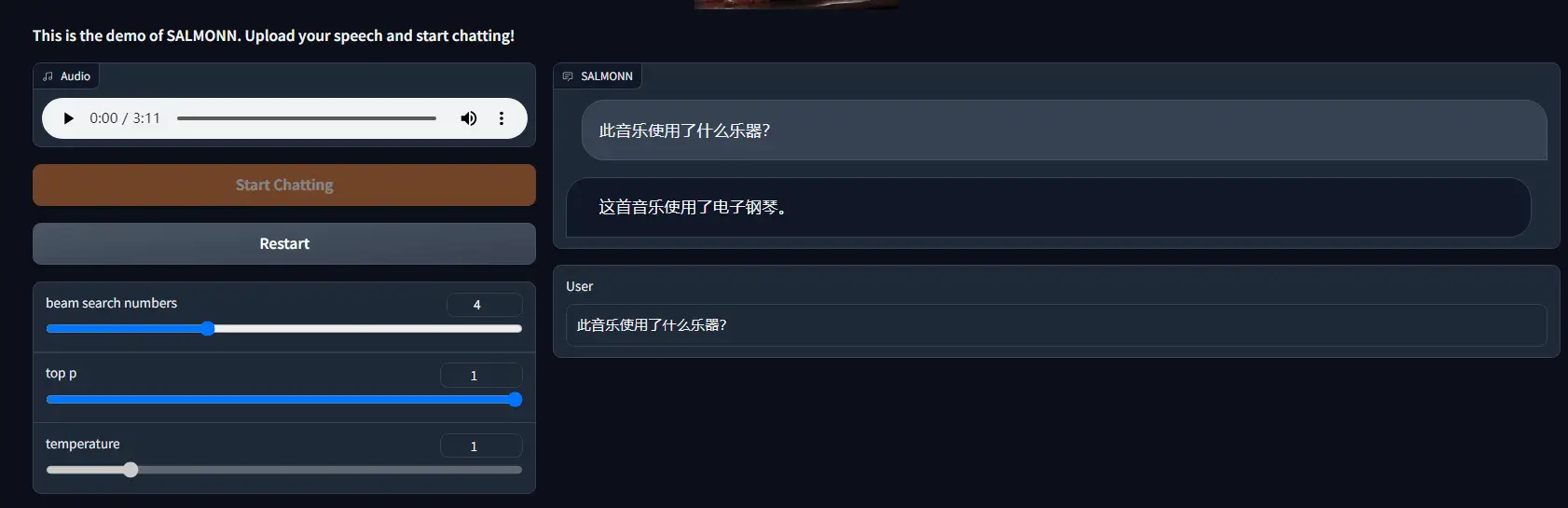
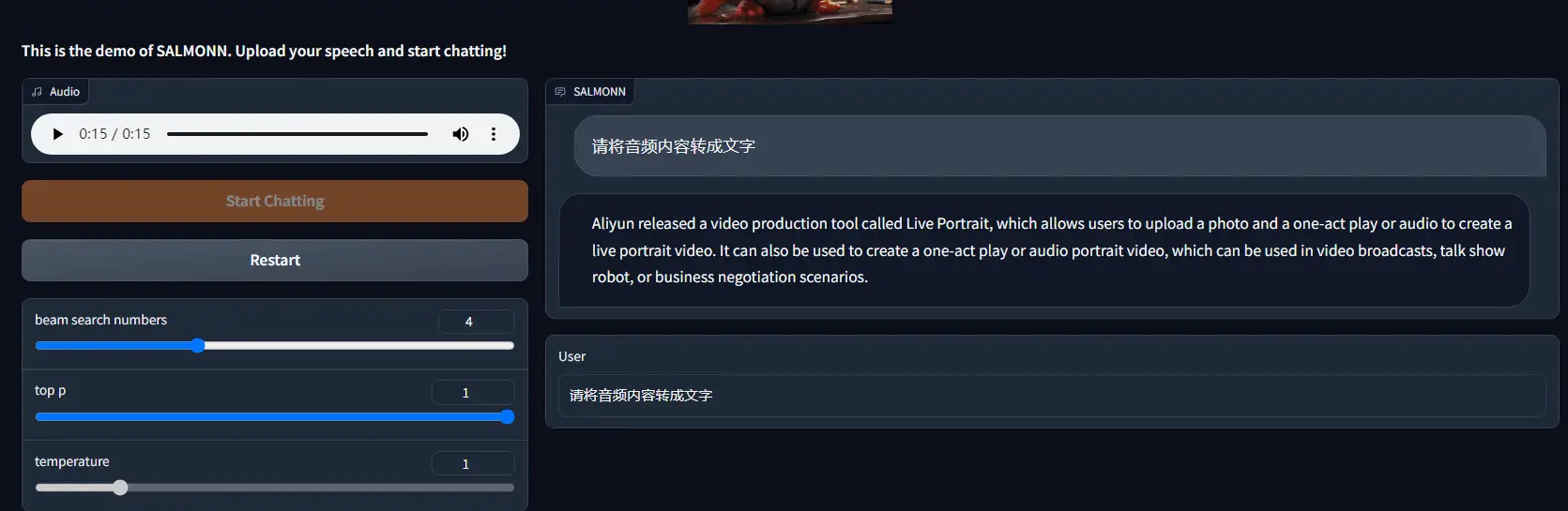
但对中文的支持似乎又不太好,我上传中文语音让它转成文字,它直接给给翻译成了英文
官方给出的示例也全是英文,所以还是建议大家使用英文进行试用