
文章目录[隐藏]
- [t-primary icon='']AI·快讯[/t-primary]
- 1、因“运行效率不及预期”,消息称 OpenAI 停止开发 AI 模型 Arrakis
- 2、ChatGPT 上线 DALL・E 3 测试版,可根据文字生成高质量图片
- 3、ChatGPT 联网功能正式上线,Plus 会员可用
- 4、用户在 Edge 浏览器上使用谷歌 Bard 时,微软会弹窗宣传必应聊天
- 5、OpenAI 正和 Jony Ive 开发“AI 硬件”,但不会是手机和人形机器人
- 6、消息称 OpenAI 正洽谈以 860 亿美元估值出售股份
- 7、北大推出“最强编程助手”:代码大模型 CodeShell-7B 开源,性能霸榜
- 8、消息称苹果最早在 iOS18 中推出生成式 AI 功能,包含云端及设备端
- 9、Llama 2第一、GPT-4第三!斯坦福大模型最新测评出炉
- 10、Meta新研究:AI实时解读大脑信号并还原图像
- 11、上海AI实验室开源首个城市级NeRF实景3D大模型
- 12、华人团队发布大模型事实性综述
- 13、Midjourney发布动漫风格图像生成App
- 14、Transformer一作开源多模态大模型Fuyu-8B
- 15、英伟达推出Tensor RT-LLM开源库 运行提速4倍
- 16、华为诺亚方舟发布低成本文生图模型PixArt-α
- 17、面壁智能联合清华推出AI智能体Xagent
[t-primary icon='']AI·快讯[/t-primary]
1、因“运行效率不及预期”,消息称 OpenAI 停止开发 AI 模型 Arrakis
据外媒 The Information 报道,OpenAI 放弃了一个名为 Arrakis 的新 AI 模型,该模型以《沙丘》中的沙漠星球 Arrakis 命名。据称,Arrakis 模型专为 ChatGPT 打造,OpenAI 希望这一模型在效率方面能够比 GPT 系列更高,从而以更低廉的价格驱动 ChatGPT,不过也正因为 Arrakis 在测试中“未能达到预期”,导致该项目已经被正式取消。(来源:IT之家)
2、ChatGPT 上线 DALL・E 3 测试版,可根据文字生成高质量图片
OpenAI 曾经推出名为 DALL-E 的模型,可以根据用户输入的文字描述生成相应的图片。上个月,OpenAI 宣布了一个更先进的 DALL・E 版本,叫做 DALL・E 3,现在其已上线 ChatGPT。要使用 DALL・E 3,用户需要在 ChatGPT 中选择 GPT-4 选项下的 DALL・E 3。选择好之后,用户就可以输入任意长度的文字描述,从一句话到一段话都可以,来描述他们想要的艺术作品,然后 DALL・E 3 就会在几秒钟内生成图片。OpenAI 在公布 DALL・E 3 时表示,这个模型可以超越之前的 DALL・E 2 的能力,生成更准确和更细致的图片,并且更好地捕捉文字描述中的细微差别。

3、ChatGPT 联网功能正式上线,Plus 会员可用
周二,OpenAI 通过其发布说明宣布,网页浏览功能已经从测试阶段转为正式版,让订阅用户更方便地使用,不再需要切换测试开关。根据说明,现在订阅用户只需要从 GPT-4 模型选择器中选择“使用 Bing 浏览网页”即可。对于其他渴望使用这个功能的用户,OpenAI 曾在原始公告中表示该功能将很快向所有用户推出。在此之前,Bing Chat 是一个不错的替代方案,因为它也是由 GPT-4 支持的,并且可以访问互联网,并且是免费的。(来源:IT之家)
4、用户在 Edge 浏览器上使用谷歌 Bard 时,微软会弹窗宣传必应聊天
微软再次向竞争对手发起挑战。这一次,当用户在 Edge 浏览器上尝试使用竞争对手谷歌的 Bard 聊天机器人时,微软会大力推广 Bing Chat。这个变化出现在 Edge 最新的 Canary(v. 120.0.2168.0)版本中,如果用户在最新版本上搜索“google bard”,就会弹出一个推荐 Bing Chat 的广告。打开 Bard 后,地址栏里还会出现一个 Bing 图标,建议用户在分屏模式下打开 Bing Chat,并比较它们的回答。(来源:IT之家)
5、OpenAI 正和 Jony Ive 开发“AI 硬件”,但不会是手机和人形机器人
今年 9 月报道,有消息称 OpenAI 首席执行官萨姆・奥尔特曼(Sam Altman)正和乔尼・艾夫(Jony Ive)合作,讨论新的“AI 硬件”项目。奥尔特曼近日在接受《华尔街日报》乔安娜・斯特恩采访时,否认了外界关于 AI 手机的猜测,表示在这个计算机可以独立思考的人工智能新时代,什么样的硬件是可能的。斯特恩询问这款 AI 硬件是否可以是智能手机时,奥尔特曼否认了这个观点,他表示:“我认为我们正参与到了一些伟大的事情中,但现阶段我无法知道未来的模样,但我们没有兴趣和智能手机竞争”。奥尔特曼还否认了以人形机器人的形式出现的想法,表示现在有很多潜在的想法,但所有这些想法都处于讨论的早期阶段。
6、消息称 OpenAI 正洽谈以 860 亿美元估值出售股份
据彭博社周三报道,微软支持的人工智能公司 OpenAI 正在与潜在投资者商谈,以 860 亿美元的估值出售现有员工的股份。消息人士透露,该公司还没有敲定分配方案,条款可能还会发生变化。上个月华尔街日报曾报道,OpenAI 正在寻求以高达 900 亿美元的估值出售股份。
7、北大推出“最强编程助手”:代码大模型 CodeShell-7B 开源,性能霸榜
北京大学软件工程国家工程研究中心知识计算实验室联合四川天府银行 AI 实验室,今天正式开源旗下 70 亿参数的代码大模型 CodeShell,号称“同等规模最强代码基座”。官方已经在 GitHub 开源了模型、相关配套方案及 IDE 插件,支持商用。CodeShell-7B 基于 5000 亿 Tokens 进行了冷启动训练,上下文窗口长度为 8192,架构设计上融合了 StarCoder 和 Llama 两者的核心特性。

8、消息称苹果最早在 iOS18 中推出生成式 AI 功能,包含云端及设备端
海通国际证券公司分析师 Jeff Pu 今日声称,苹果计划最早在 2024 年底,在 iPhone 和 iPad 中加入生成式 AI 技术。Jeff Pu 援引自己的供应链调查声称,苹果可能会在今明两年设立几百台 AI 服务器,以实现相关功能。该分析师认为,苹果届时将提供云端和设备端两种 AI 组合形式,从而保证用户隐私性。不过 Jeff Pu 同时补充称,外界需要“一点耐心”等待苹果推出自家生成式 AI 服务,因为苹果公司还在考虑“如何以符合客户隐私承诺的方式使用和处理个人数据”。(来源:IT之家)
9、Llama 2第一、GPT-4第三!斯坦福大模型最新测评出炉
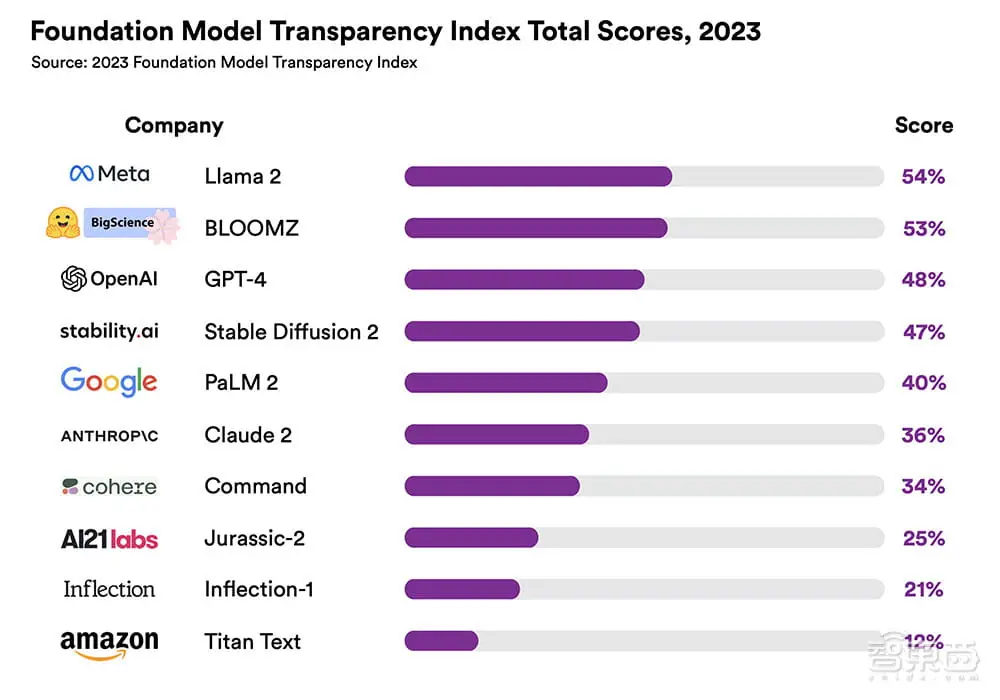
今天,斯坦福大学基础模型研究中心(CRFM)联合斯坦福以人为本AI研究所(HAI)、麻省理工学院媒体实验室、普林斯顿大学信息技术中心共同发布了2023基础模型透明度指数(Foundation Model Transparency Index,FMTI),并对10个主流基础模型进行了透明度评级。评级结果表明,即使是得分最高的Meta Llama2也仅在满分100分中获得54分,OpenAI的GPT-4获得48分,排名第三。10个基础模型的平均得分仅为37分。(来源:智东西)
10、Meta新研究:AI实时解读大脑信号并还原图像
当地时间10月18日,Meta于官网发布一项新研究,利用MEG(脑磁图)实现大脑活动图像的实时解码,开发了一个由图像编码器、大脑编码器和图像解码器组成的三部分系统。据介绍,该系统可以实时部署,根据大脑活动重建人脑在每个瞬间感知和处理的图像,并用AI再现。Meta称,该研究的主要贡献在于速度,研究结果表明,MEG可用于以毫秒级的精度破译大脑中产生的复杂表征。不过在准确性上,目前通过MEG解码生成的图像仍然不如通过fMRI(功能性磁共振成像)获得的解码精确。

11、上海AI实验室开源首个城市级NeRF实景3D大模型
据上海AI实验室微信公众号发文,近日,上海AI实验室正式开源了全球首个城市级NeRF实景三维大模型“书生·天际”(LandMark),支持在不同应用场景下的落地部署,并提供免费商用。作为上海AI实验室书生通用大模型体系的重要组成部分,书生·天际将逐步开放更多能力,赋能学术研究和产业发展。今年7月,上海AI实验室联合香港中文大学和上海市测绘院发布了书生·天际,首次在大模型层面提出一种新的实景三维模型表征和训练范式,以4K级图像精度准确呈现大规模三维城市场景。
书生·天际官网:https://landmark.intern-ai.org.cn
12、华人团队发布大模型事实性综述
据机器之心报道,10月18日,西湖大学联合普渡大学、复旦大学、耶鲁大学、微软亚洲研究院等国内外十家科研单位,发表了一篇大模型事实性的综述,该综述调研了三百余篇文献,重点讨论了事实性的定义和影响、大模型事实性的评估、大模型事实性机制和产生错误的原理、大模型事实性的增强等几个方面的内容,对大模型的事实性进行了详细的梳理和总结。这篇综述的目标是为了帮助学界和业界的研究开发人员更好得理解大模型的事实性,增加模型的知识水平和可靠程度。

13、Midjourney发布动漫风格图像生成App
本周,Midjourney创始人David Holz介绍称,Midjourney与日本游戏公司Sizigi Studios的工程师合作发行了一款Android和iOS应用NijiJourney,面向日本市场,主要提供使用Midjourney动漫风格设置的图像。该应用程序需要付费才能使用,全年一次性支付96美元,或者每月支付10美元。现有的Midjourney用户可以使用他们的Discord凭据登录,而无需支付更多费用。
14、Transformer一作开源多模态大模型Fuyu-8B
据量子位报道,当地时间10月17日,Transformer一作Ashish Vaswani所在创业公司Adept开源发布80亿参数多模态大模型Fuyu-8B。该模型具备强大的图像理解能力,能理解照片、图表、PDF、界面UI等,且处理速度很快,研究团队表示100毫秒内可反馈大图像处理结果。同时它还很“轻巧”,模型规模没超百亿,且没有使用图像编码器。目前该模型已开源,Demo可线上试玩,提供了看图问答、图像概述两种功能。据悉,Adept由Transformer一作、前OpenAI工程副总裁等业内大佬共同创立,成立于2022年4月,目前已完成B轮融资,总融资额达4.15亿美元,公司估值超过10亿美元。
15、英伟达推出Tensor RT-LLM开源库 运行提速4倍
当地时间10月17日,英伟达于官网发布适用于Windows的TensorRT-LLM开源库,可加快最新AI大型语言模型(如Llama 2和Code Llama)的推理性能,PC上的AIGC(生成式AI)运行速度可提高4倍。英伟达还发布了帮助开发人员加速LLM的工具,包括使用TensorRT-LLM优化自定义模型的脚本、TensorRT优化的开源模型以及展示LLM响应速度和质量的开发人员参考项目。TensorRT加速现在可用于Stable Diffusion,它将AIGC扩散模型的速度提高了2倍,超过了之前最快的实现速度。
16、华为诺亚方舟发布低成本文生图模型PixArt-α
来自华为诺亚方舟实验室等研究机构的研究者联合提出了开创性的文本到图像(T2I)模型PixArt-α,支持直接生成高达1024×1024的高分辨率图像。PixArt-α只需Stable Diffusion v1.5训练时间的10.8%,训练成本约为2.6万美元,可省下近30万美元;与更大的SOTA模型RAPHAEL相比,PixArt-α的训练成本仅为1%。PixArt-α模型不仅大幅降低了训练成本,还显著减少了二氧化碳排放,同时提供了接近商业应用标准的高质量图像生成。

17、面壁智能联合清华推出AI智能体Xagent
据AI创企面壁智能微信公众号发文,近日,面壁智能联合清华大学NLP实验室共同研发并推出大模型“超级英雄”XAgent。据介绍,XAgent是一个可以实现自主解决复杂任务的全新AI智能体,以LLM(大语言模型)为核心,能够理解人类指令、制定复杂计划并自主采取行动。通过任务测试,XAgent在真实复杂任务的处理能力已全面超越由GPT-4驱动的AutoGPT。
GitHub开源地址:https://github.com/OpenBMB/XAgent
案例展示地址:https://x-agent.net