文章目录[隐藏]
目前语音合成(TTS)领域已经算是非常成熟了,之前小编就给大家介绍过《 做视频不想自己出声?试试这些 AI 配音 / 语音合成服务,轻松打造热门视频!》,今天再给大家推荐一款网易有道最新上线的开源语音合成(TTS)引擎“易魔声(EmotiVoice)”,通过官方提供的 web 界面及批量生成结果的脚本接口,实现音色的情感合成与应用。今天小编就教大家如何安装此应用以及分享在安装过程中可能遇到的一些问题。
[t-success icon='']易魔声(EmotiVoice)[/t-success]
EmotiVoice是一款网易有道自研 TTS 引擎,支持中英文双语,包含2000多种不同的音色,以及特色的情感合成功能,支持合成包含快乐、兴奋、悲伤、愤怒等广泛情感的语音。现在通过易魔声,简单通过在文本中加入情感的描述提示,开发者或者内容创作者就可以自由合成符合自己需求的带有情感的语音,比传统 TTS 更加自然逼真。
[t-warning icon='']如何安装易魔声(EmotiVoice)?[/t-warning]
目前官方提供了两种安装方法,一种是Docker,一种是完整安装,Docker安装首先需要你要安装Docker环境,还需要安装英伟达容器工具包,本文着重介绍完整安装的方法。
[t-danger icon='']Docker安装[/t-danger]
官方给出的安装介绍,目前仅支持英伟达显卡电脑,按照网上的教程(Linux和Windows WSL2)来安装英伟达容器工具包,安装好后就看可以安装易魔声镜像:
docker run -dp 127.0.0.1:8501:8501 syq163/emoti-voice:latest
安装好后,在浏览器打开http://localhost:8501就可以体验EmotiVoice了
[t-warning icon='']完整安装[/t-warning]
1、首先需要安装 Anaconda,小编是在 Windows11 系统上安装的(PS:Anaconda 是一个包管理器、一个环境管理器、一个 Python/R 数据科学发行版以及超过 7,500 个开源包的集合)
Anaconda 下载地址:https://www.anaconda.com/download
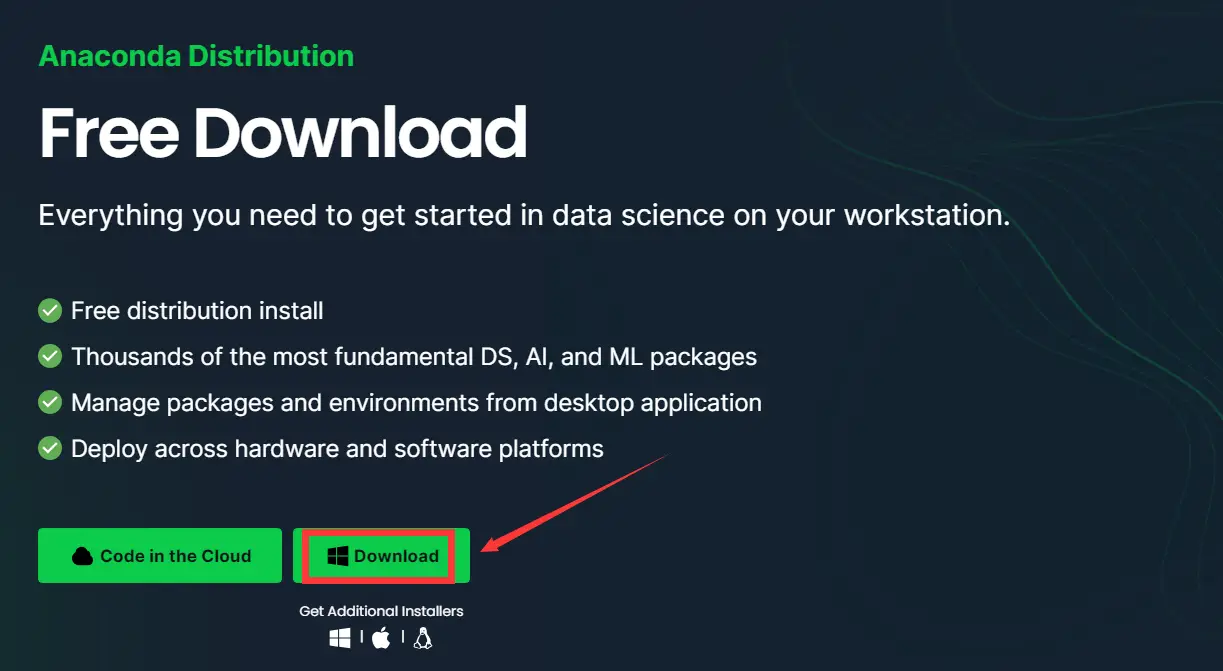
2、下载 Anaconda 软件,点击软件进行安装,小编不建议大家将软件安装在 C 盘,大家可自行选择安装位置,之后就一路点击 Next 安装,无需任何更改

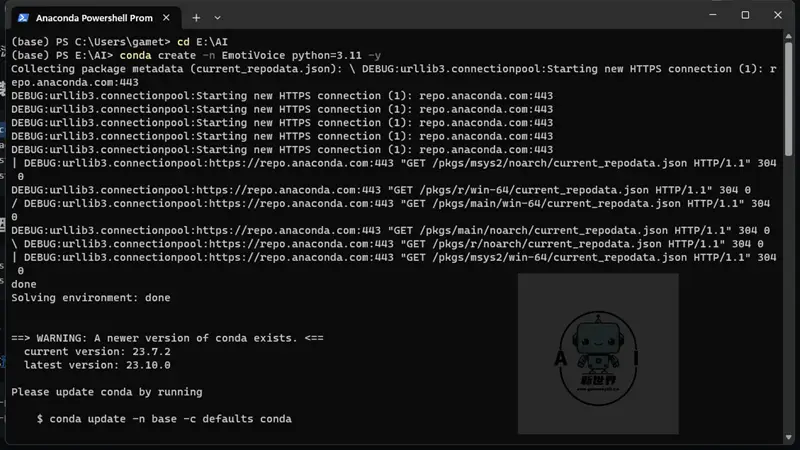
3、之后在直接搜索或者在所有应用里打开 Anconda Powershell Promet 或者 Anconda Promet,接着就是更改应用的安装位置

👇直接使用 CD 命令更改安装位置,如:
cd E:\AI

4、接着就是创建一个 Conda 环境,使用以下命令行进行创建:
conda create -n EmotiVoice python=3.11 -y
👇官方提供的教程是安装python3.8,但小编在安装的过程中会出现各种错误,因此将python改成了3.11版
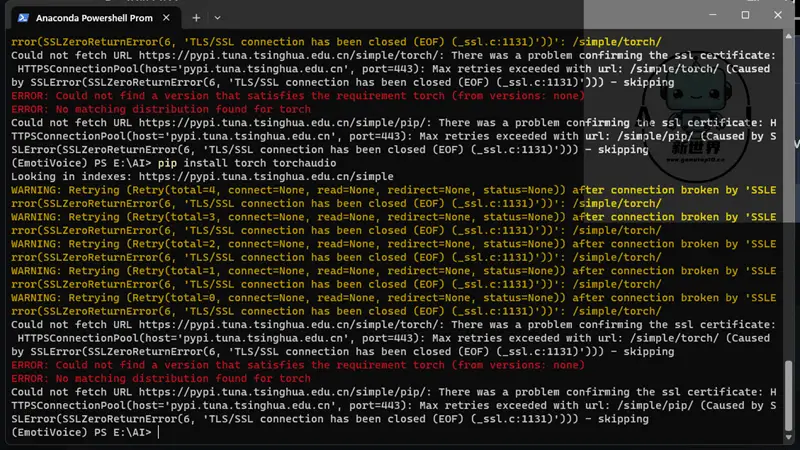
5、复制以下命令激活环境
conda activate EmotiVoice
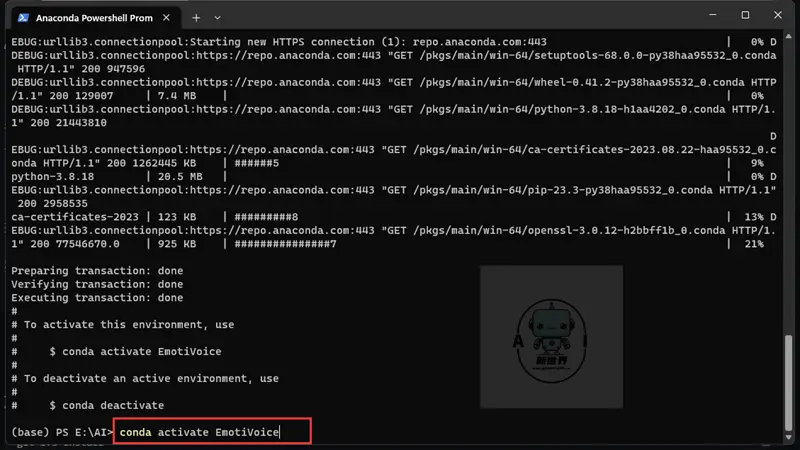
然后使用以下命令安装 pip
python -m ensurepip
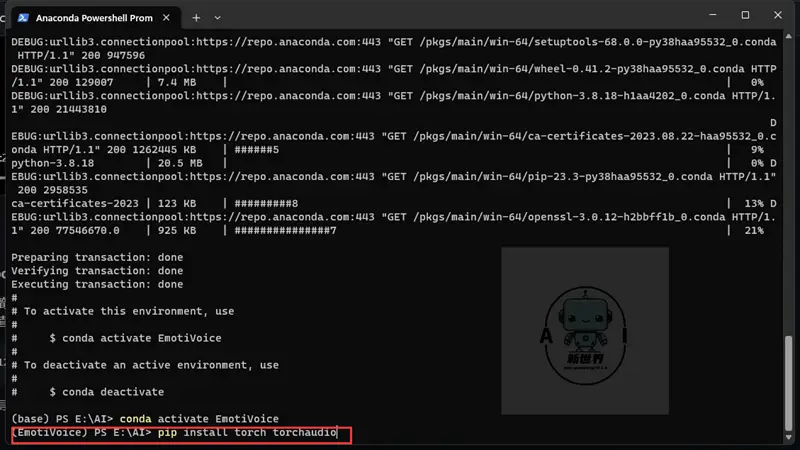
6、接着就是安装组件,在安装组件时会从国内的源(清华大学)来安装
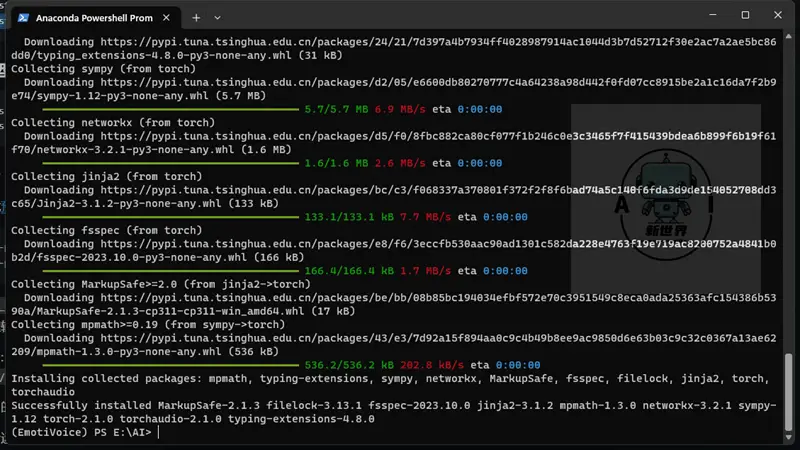
pip install torch torchaudio
安装完毕后,再执行以下命令
pip install numpy numba scipy transformers==4.26.1 soundfile yacs g2p_en jieba pypinyin
安装streamlit环境,执行以下命令
pip install streamlit
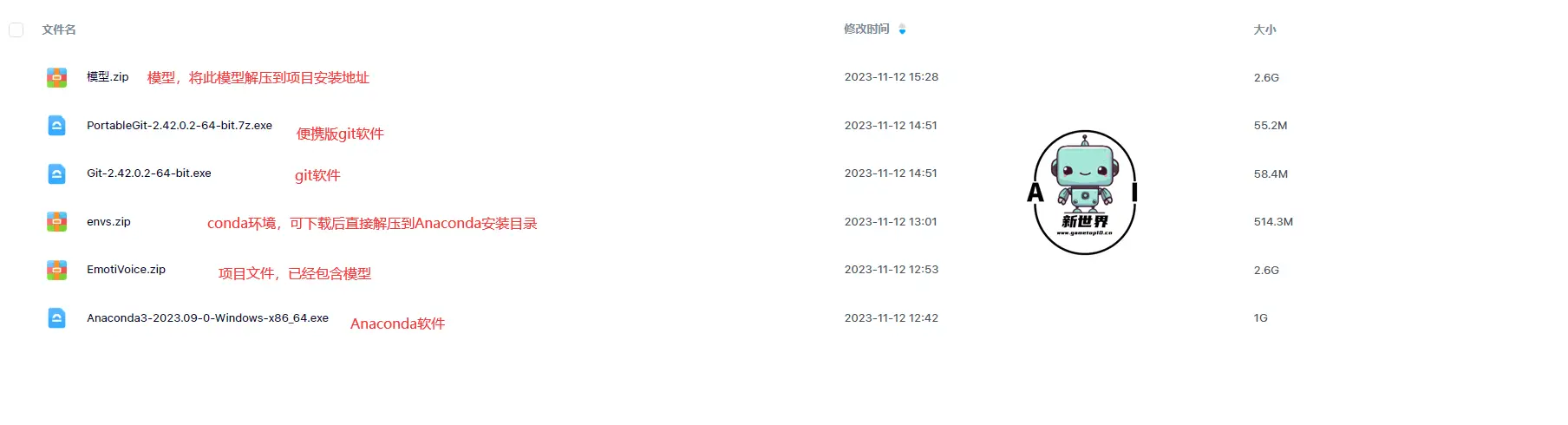
7、经过以上的安装,Conda 环境就已经安装好了,官方的教程接着就是教大家下载模型,但小编使用官方的教程来下载安装模型时出现了各种各样的错误,因此小编将模型下载后放到了国内网盘,大家可自行下载,下载地址在文末
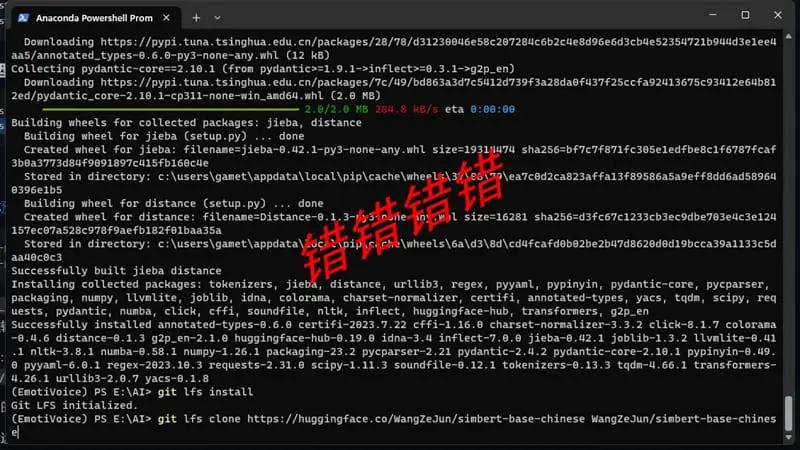
8、下载安装git软件,此软件可帮助大家方便从GitHub下载安装开源项目
地址:https://git-scm.com/download/win
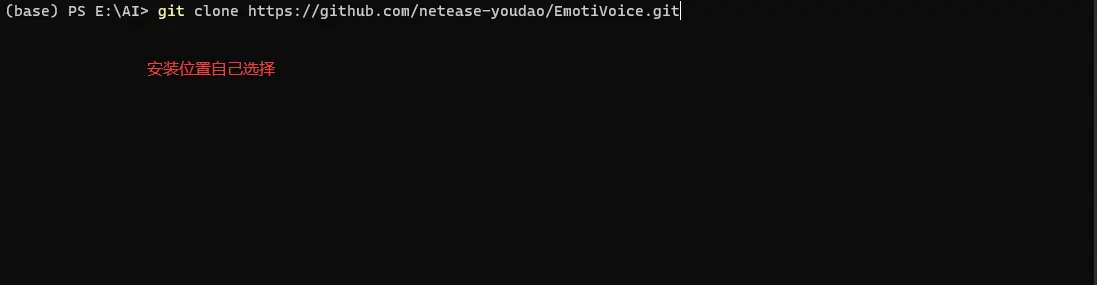
9、使用以下命令下载EmotiVoice项目,如果没有网络环境来下载安装GitHub上的项目,可以参考《Github无法访问?这些方法可以帮你解决问题,快速访问Github》
git clone https://github.com/netease-youdao/EmotiVoice.git
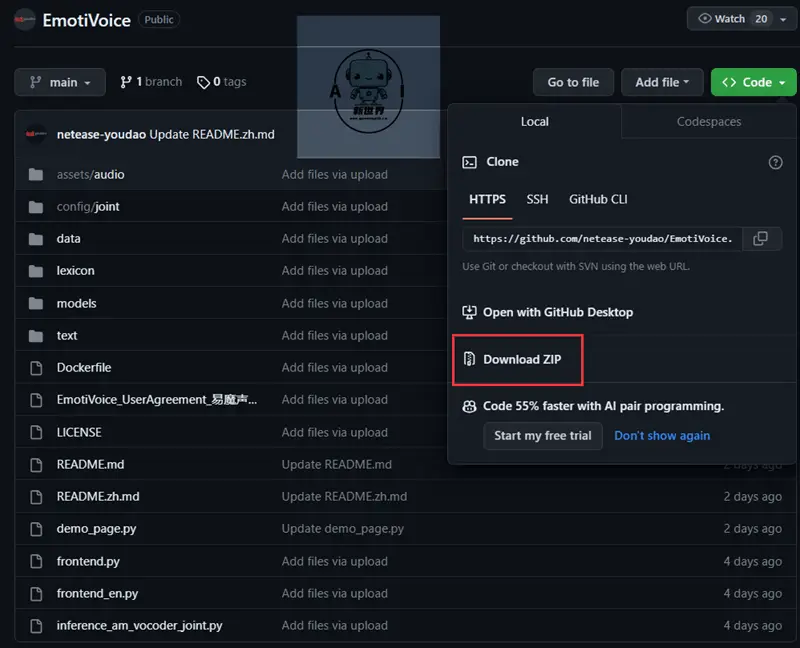
👇也可打包下载到本地,再进行解压,小编已经将此项目与模型一起打包上传到国内网盘
10、经过上面的安装其实就已经可以启动此项目了,但还需要模型才能正常工作,目前官方引用了第三方开源模型,此模型在huggingface上,官方的模型则上传到了谷歌网盘,小编将模型下载打包后上传到了国内网盘,将模型下载后解压到EmotiVoice项目目录下
11、使用命令行进行推理生成比较麻烦,好在官方提供了网页界面,虽然比较简陋,但相比命令行还是方便很多,使用以下命令即可启动应用
streamlit run demo_page.py
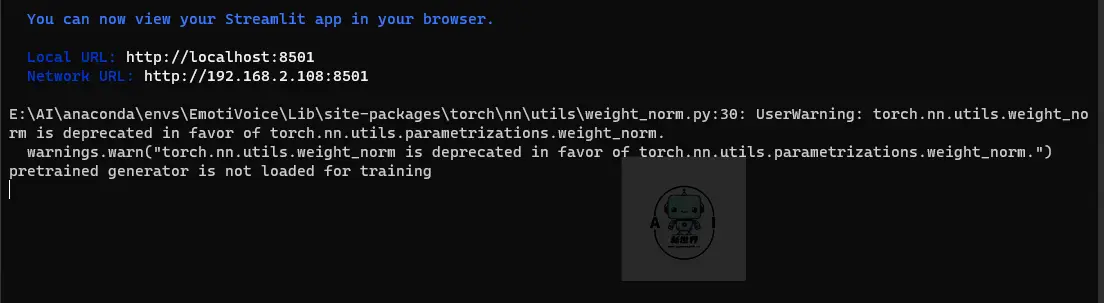
👇启用后可能会出现编码错误,只需更改一下文件读取编码格式就行
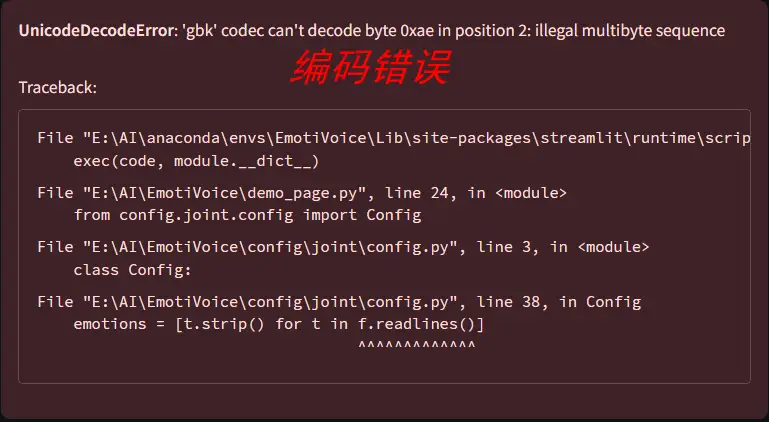
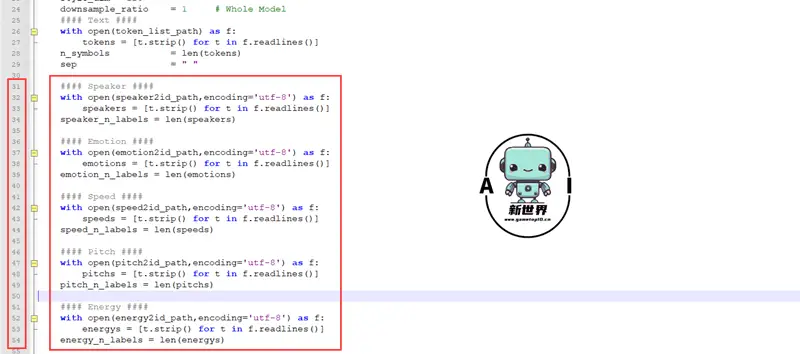
在EmotiVoice\config\joint目录下找到config.py文件,复制以下代码将第31行-54行的代码进行替换
#### Speaker #### with open(speaker2id_path,encoding='utf-8') as f: speakers = [t.strip() for t in f.readlines()] speaker_n_labels = len(speakers) #### Emotion #### with open(emotion2id_path,encoding='utf-8') as f: emotions = [t.strip() for t in f.readlines()] emotion_n_labels = len(emotions) #### Speed #### with open(speed2id_path,encoding='utf-8') as f: speeds = [t.strip() for t in f.readlines()] speed_n_labels = len(speeds) #### Pitch #### with open(pitch2id_path,encoding='utf-8') as f: pitchs = [t.strip() for t in f.readlines()] pitch_n_labels = len(pitchs) #### Energy #### with open(energy2id_path,encoding='utf-8') as f: energys = [t.strip() for t in f.readlines()] energy_n_labels = len(energys)
更改编码后就可以正常启动运行了,如果不想每次启动都如此麻烦,可以在你的 EmotiVoice 文件夹中创建一个新的文本文件,然后将以下命令复制并粘贴到文件中,最后将文件保存为 start_app.bat:
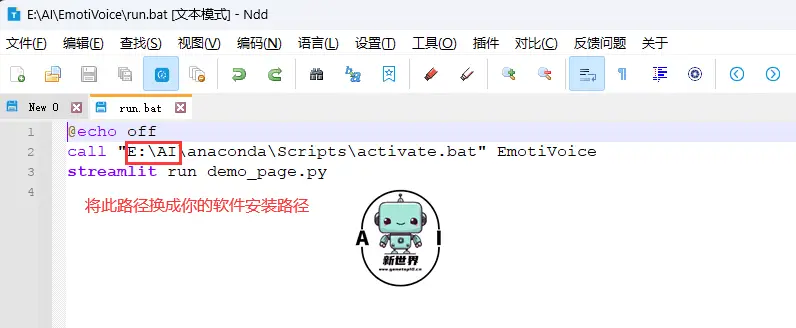
@echo off call "E:\AI\anaconda\Scripts\activate.bat" EmotiVoice streamlit run demo_page.py
请将 activate.bat 的完整路径替换为你的 Conda 安装路径。然后,只需双击运行 start_app.bat 文件,它将自动激活 Conda 环境并启动你的应用。
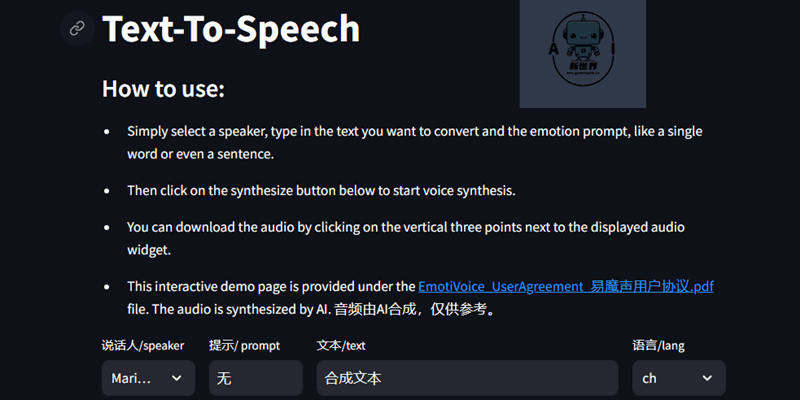
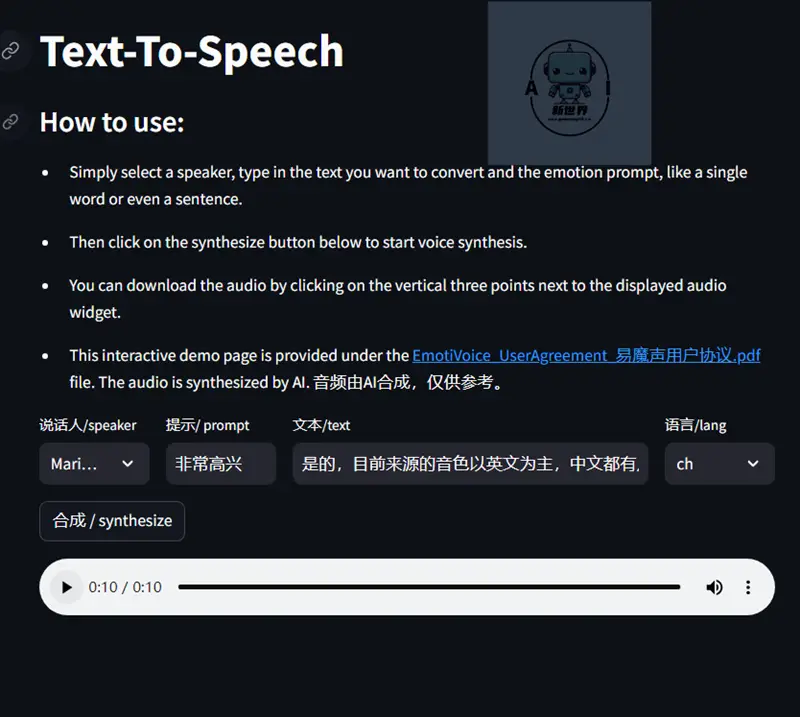
[t-info icon='']如何使用易魔声(EmotiVoice)?[/t-info]
易魔声的网页界面相当简洁,选择说话人,填写语气和文本,再选择语言,即可点击合成来生成语音。从目前生成的效果来看,问题还是比较多的,官方人员已经在微信群程序后续会进行修正与改进。
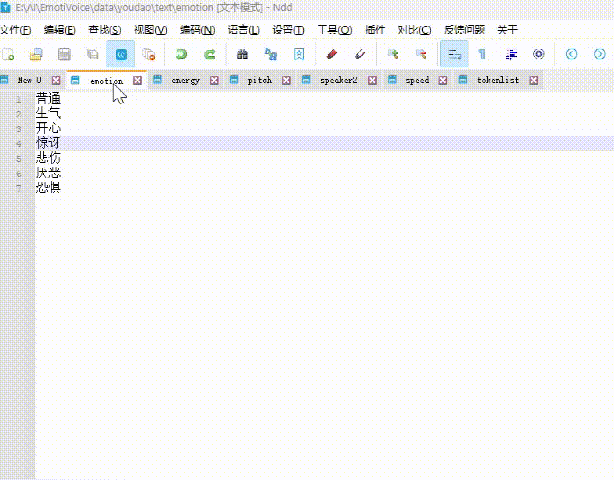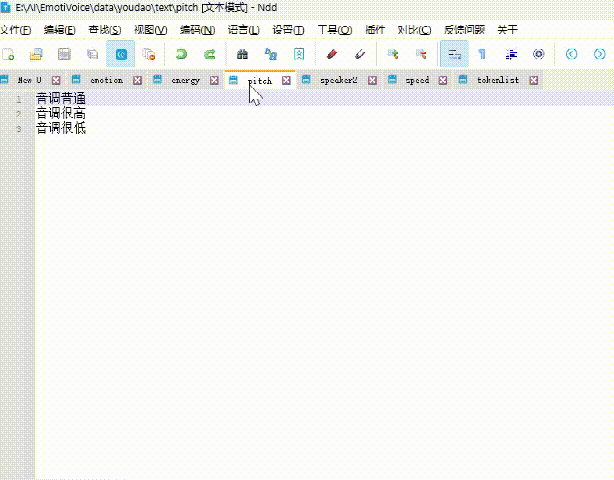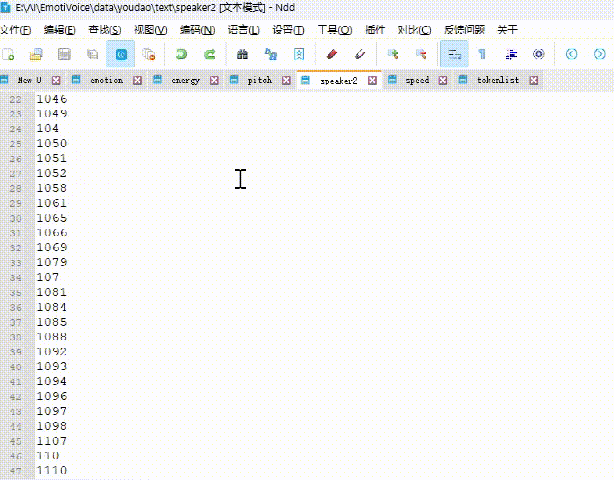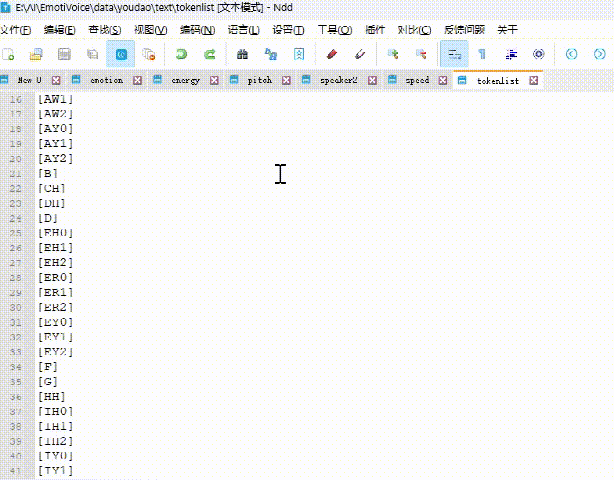
👇生成的速度相当不错,说话人、语气等都可在EmotiVoice\data\youdao\text路径下的文件进行查看
👇语气、语调、音调、语速等都可以设置
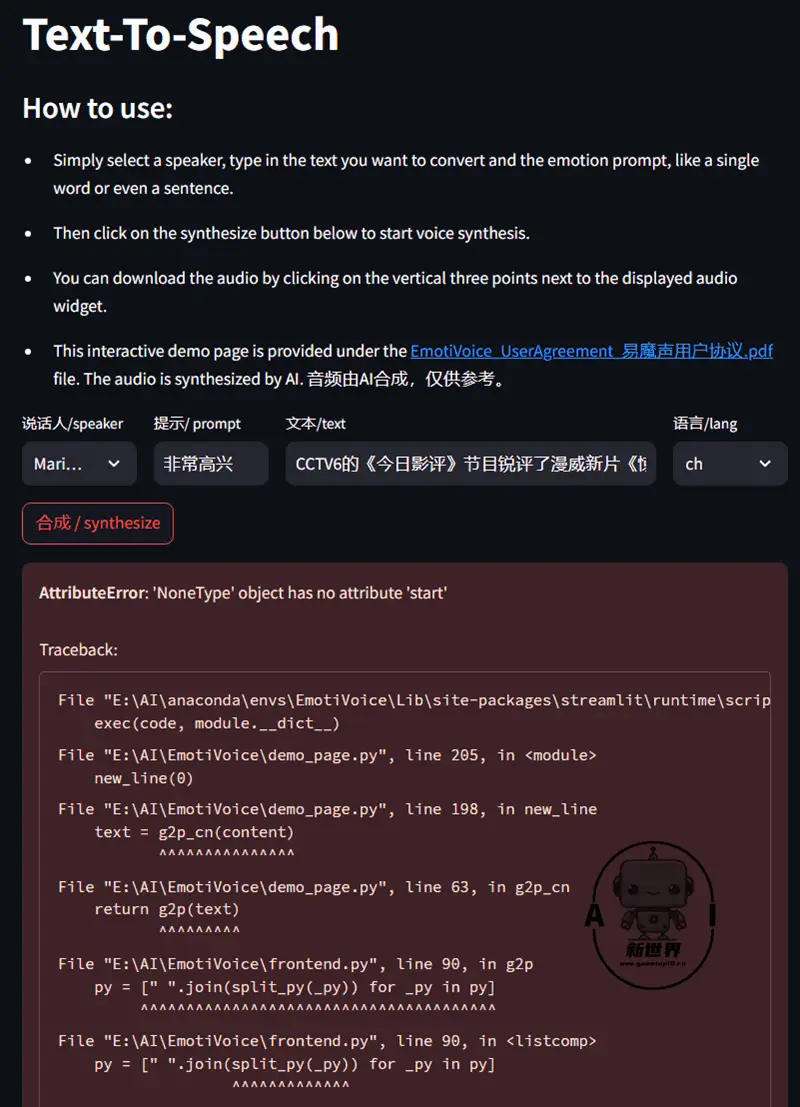
经过小编简单的测试与官方群内其他人的反馈,目前已知问题包括但不限于:
- 音色、声调以外国人为主,生成的语音老外腔比较严重
- 文本如含有中英文混搭、阿拉伯数字会直接报错
- 过长的文本、标点符号过多也会报错
[t-dark icon='']结语[/t-dark]
项目刚上线,目前可以说各方面都不太成熟,大家现在安装试用可以算尝鲜,可以等待后续发展。如果你的网络环境安装此项目不方便,可以从网盘下载项目文件。
百度网盘:https://pan.baidu.com/s/1PGj8zjfcjcxtFUrwBeG3jQ?pwd=wikg 提取码: wikg
123网盘:https://www.123pan.com/s/I1oZVv-ZquGA.html 提取码:T1Ta