
文章目录[隐藏]
Whisper 是 OpenAI 旗下的开源语音识别模型,可以将语音转换为文字,支持多种语言,目前网上有非常多开发者基于此开源模型打造语音识别产品,之前小编就给大家介绍过不少,今天就给大家做一个合集,大家可以根据自己需求进行选择,一起来看看吧!

Buzz
Buzz 是一款基于 OpenAI Whisper 的开源的实时语音转文字工具,不同点在于其可离线运行,支持 Windows、macOS、Linux,它可以将麦克风的语音实时转换为文字,也支持将视频、音频文件转换为文字、字幕。
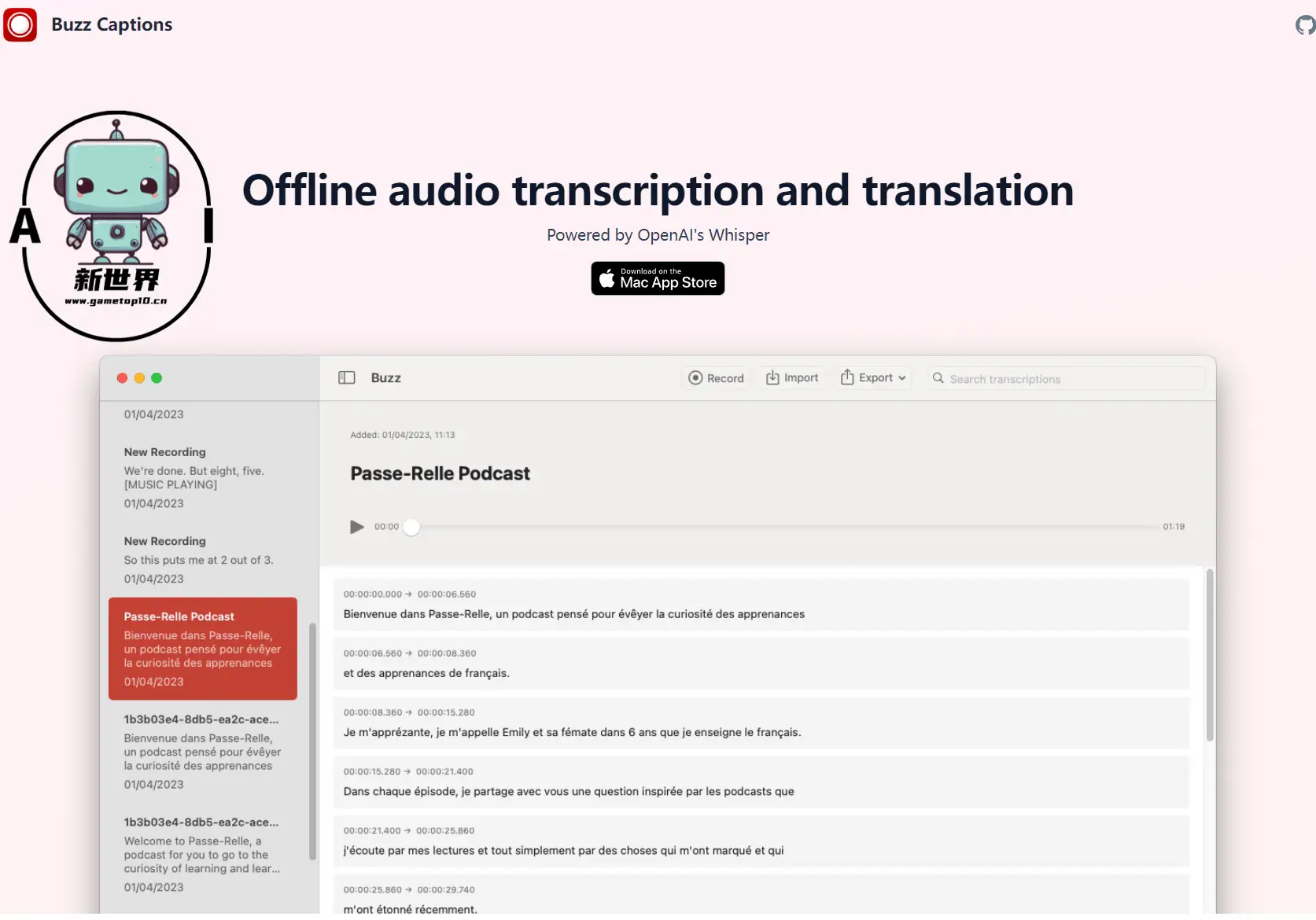
Transcribe Audio
Transcribe Audio 是一个非常简易的开源 Whisper 客户端,它只有三个文件:index.html、index.js、style.css,只需要下载、解压缩,将 index.html 拖到浏览器里就可以使用,也可以将这些文件上传到主机空间绑定域名进行访问。在顶部输入你的 OpenAI API key(和 ChatGPT 同一个),就可以选择音频文件进行转换,支持保存为文本、.srt、.vtt 三种格式。
支持上传音频格式:mp3、mp4、mpeg、mpga、m4a、wav、webm、mp4、mpeg、webm
开源地址:https://github.com/felixbade/transcribe
官方 DEMO:https://transcribe.bloat.app
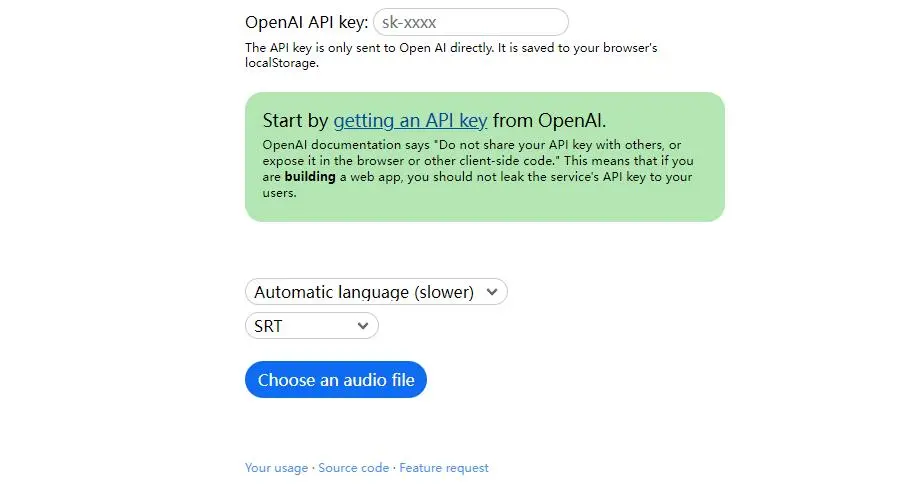
GPT-Subtitle
「GPT-Subtitle」是结合了 Whisper 和 OpenAI 的 GPT-3 语言模型 的开源应用,为大家提供音频和视频的本地翻译功能。此应用不仅能够将字幕转换成对话并进行翻译,而且支持多种语言的翻译,并能方便地将字幕翻译成其他语言。此应用支持 Docker 部署,具体可查看 Github 页面。

Whisper JAX
「Whisper JAX」是一款基于 Whisper API 的在线语音转文字工具,此工具托管在 Hugging Face 平台,直接在浏览器打开网页使用即可,目前支持麦克风、录音文件、YouTube 三种音频来源,单文件 2 小时以内免费使用。

Whisper Desktop
「Whisper Desktop」是一款基于 OpenAI 旗下开源语音识别系统 Whisper 的免费开源可可离线使用的「影音文件转文字、字幕」桌面端软件,可以在 Windows 上简单执行,它会利用电脑当中的显卡(GPU)当作算力,在离线的本机端完成语音转文字的功能。

VoiceStreamAI
VoiceStreamAI 是一款可以自己托管的 开源 Whisper 解决方案,服务端是 Python,客户端是 JavaScript,基于 WebSocket 实时通信,可以做到语音的实时传输和文本转换。该系统采用 Huggingface 的声活动检测(VAD)和 OpenAI 的 Whisper 模型进行准确的语音识别和处理。

语音识别转文字工具(tts)
一个离线运行的本地语音识别转文字工具,基于 openai-whipser 开源模型,可将视频/音频中的人类声音识别并转为文字,可输出json格式、srt字幕带时间戳格式、纯文字格式。可用于自行部署后替代 openai 的语音识别接口或百度语音识别等,准确率基本等同openai官方api接口。
GitHub地址:https://github.com/jianchang512/stt
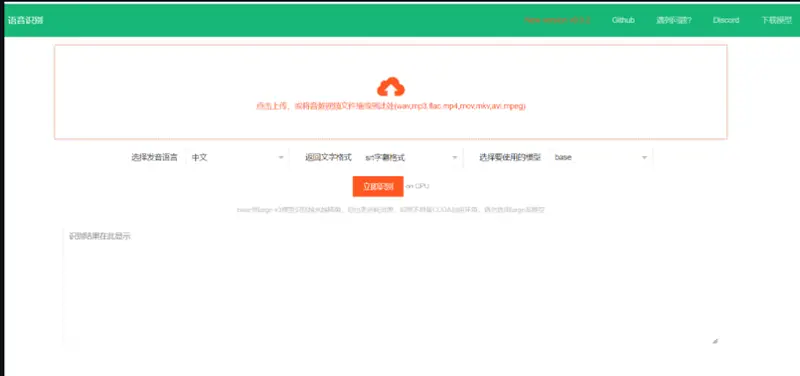
Faster Whisper
faster-whisper是基于OpenAI的Whisper模型的高效实现,它利用CTranslate2,一个专为Transformer模型设计的快速推理引擎。这种实现不仅提高了语音识别的速度,还优化了内存使用效率。faster-whisper的核心优势在于其能够在保持原有模型准确度的同时,大幅提升处理速度,这使得它在处理大规模语音数据时更加高效。
Whisper-WebUI
一个基于Gradio的Whisper浏览器界面,您可以将其用作简易字幕生成器。