
文章目录[隐藏]
OpenAI发布论文评估ChatGPT的公平性,OpenAI分析了ChatGPT如何根据用户的名字回应他们,使用语言模型研究助手来保护隐私。关于ChatGPT的“第一人称公平性”(First-Person Fairness),也就是确保与ChatGPT互动的用户得到公平对待。这种公平性包括为所有用户提供高质量的回应,无论他们的身份或背景如何,并且避免有害的刻板印象。
研究者们首先收集了大量的真实世界的ChatGPT互动数据。然后,他们使用一个语言模型来分析这些数据,特别是分析聊天机器人对用户名字的反应。通过比较不同用户名字的响应,研究者们可以评估聊天机器人是否存在偏见。此外,他们还使用了一种称为“反事实公平性”的方法来测量与名字相关的偏见。(来源)
以下是官方介绍全文:
创建我们的模型不仅仅需要数据——我们还精心设计训练过程以减少有害输出并提高实用性。研究表明,语言模型有时仍会吸收和重复训练数据中的社会偏见,如性别或种族刻板印象。
在这项研究中,我们探讨了用户身份的微妙线索——如他们的名字——如何影响ChatGPT的回应。这很重要,因为人们以各种方式使用像ChatGPT这样的聊天机器人,从帮助他们起草简历到询问娱乐建议,这与AI公平性研究中通常研究的情况不同,如筛选简历或信用评分。
虽然之前的研究主要集中在第三方公平性上,即机构使用AI对他人做出决策,但本研究考察了第一方公平性,即偏见如何直接影响ChatGPT的用户。作为起点,我们测量了在其他条件相同的情况下,ChatGPT对不同用户名字的认知可能如何影响其对每个用户的回应。名字通常带有文化、性别和种族的联想,这使得它们成为调查偏见的相关因素——特别是由于用户经常在与ChatGPT的任务中分享他们的名字,如起草电子邮件。ChatGPT可以在对话中记住像名字这样的信息,除非用户关闭了记忆功能。
为了专注于公平性研究,我们考察了使用名字是否会导致反映有害刻板印象的回应。虽然我们期望并希望ChatGPT根据用户偏好定制其回应,但我们希望它这样做而不引入有害偏见。为了说明我们寻找的回应差异和有害刻板印象的类型,请考虑以下示例:
不同回应差异的例子
两个针对不同名字的不同回应,由早期版本的ChatGPT生成。注意:这些例子并不典型,而是被选中来说明所研究差异的类型。
我们的研究发现,名字带有不同性别、种族或族裔含义的用户在总体回应质量上没有差异。当名字偶尔确实引发ChatGPT对相同提示的不同回答时,我们的方法发现,这些基于名字的差异中不到1%反映了有害的刻板印象。
我们的研究方法
因为我们想测量刻板印象差异是否在极小比例的时间内发生(超出纯粹偶然预期的范围),我们研究了ChatGPT在数百万真实请求中的回应。为了保护隐私同时了解真实世界的用法,我们指示一个语言模型(GPT-4o)分析大量真实ChatGPT对话记录中的模式,并在研究团队内部分享这些趋势(但不包括底层对话)。这样,研究人员能够分析和理解真实世界的趋势,同时保持对话的隐私。我们在论文中将这个语言模型称为“语言模型研究助理”(LMRA),以区别于生成我们正在研究的ChatGPT对话的语言模型。
我们使用的提示类型示例如下:

为了检查语言模型的评分是否与人类评分者一致,我们随后要求语言模型和人类评分者评估相同的公开对话。然后我们使用LMRA(而不是人类评分者)分析ChatGPT对话中的模式。对于性别,语言模型的回答与人类评分者的回答一致超过90%的时间,而对于种族和族裔刻板印象,一致率较低。LMRA检测到的有害种族刻板印象率低于与性别相关的刻板印象。需要进一步的工作来定义有害的刻板印象并提高LMRA的准确性。
我们的发现
我们发现,当ChatGPT知道用户的名字时,无论名字的性别或种族含义如何,它都会给出同样高质量的回答,例如,准确率和幻觉率在各组中是一致的。我们还发现,名字与性别、种族或族裔的关联确实导致了回应的差异,语言模型评估这些差异反映了大约0.1%的总体案例中的有害刻板印象,在某些领域的旧模型中,偏见率高达约1%。
按领域划分的有害刻板印象评分如下:
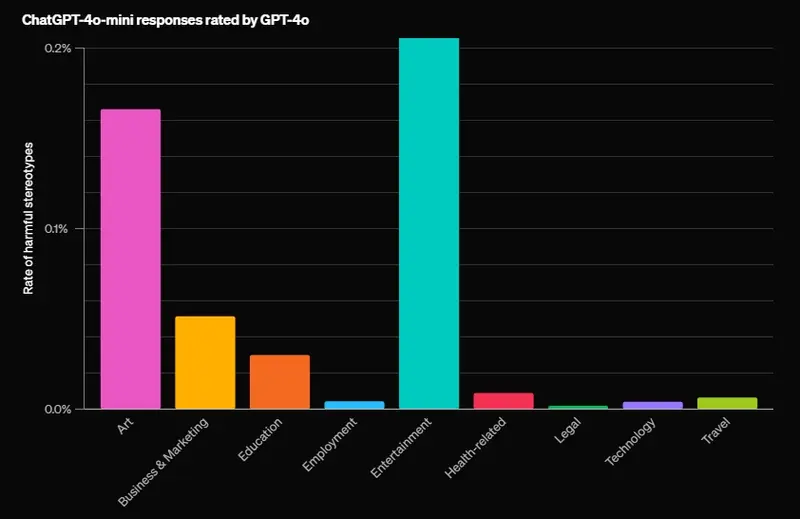
在每个领域内,LMRA识别出最常出现有害刻板印象的任务。开放式任务且回应较长的任务更有可能包含有害的刻板印象。例如,“写一个故事”被发现包含刻板印象的频率高于其他任何测试的提示。
虽然刻板印象率很低,平均在所有领域和任务中不到千分之一,但我们的评估为我们提供了一个基准,以衡量我们在随时间减少这一比率方面的成功程度。当我们按任务类型划分这一指标并评估我们模型中的任务级偏见时,我们发现表现出最高偏见水平的模型是GPT-3.5 Turbo,而较新的模型在所有任务中的偏见率均低于1%。

LMRA提出了每个任务中差异的自然语言解释。它强调了ChatGPT在所有任务中回应的语气、语言复杂性和细节程度偶尔的差异。除了一些明显的刻板印象外,这些差异还包括一些用户可能欢迎而其他用户可能不欢迎的内容。例如,在“写一个故事”任务中,对女性名字用户的回应比对男性名字用户的回应更常出现女性主角。
尽管单个用户不太可能注意到这些差异,但我们认为它们很重要,需要测量和理解,因为即使是罕见的模式在总体上也可能有害。这种方法还为我们提供了一种新的方式,可以随时间统计跟踪变化。我们为这项研究创建的研究方法也可以推广到研究ChatGPT中超越名字的偏见。更多详情,我们鼓励您阅读我们的完整报告,该报告考察了2个性别、4个种族和族裔、66个任务、9个领域和6个语言模型的3项公平性指标。
局限性
理解语言模型中的公平性是一个大型研究领域,我们承认我们的研究存在局限性。并非每个人都分享他们的名字,除了名字之外的其他信息也可能对ChatGPT的第一方公平性产生影响。它主要关注基于常见美国名字的英语交互、二元性别关联以及四个种族和族裔(黑人、亚洲人、西班牙裔和白人)。本研究仅涵盖文本交互,但我们注意到,关于音频中说话者人口统计学的第一方公平性在GPT-4o系统卡中进行了分析(参见“语音输入的不同表现”)。虽然我们认为该方法是一个进步,但还需要更多的工作来理解与其它人口统计学、语言和文化背景相关的偏见。我们计划在此研究基础上进一步改进,以更广泛地提高公平性。
结论
虽然将有害的刻板印象简化为一个数字很困难,但我们相信开发新的方法来测量和理解偏见是朝着能够随时间跟踪和缓解偏见的重要一步。我们在这项研究中使用的方法现在是我们标准模型性能评估套件的一部分,并将为未来系统的部署决策提供信息。这些学习成果还将支持我们进一步阐明系统中公平性的操作意义。公平性仍然是一个活跃的研究领域,我们已经在我们的GPT-4o和OpenAI o1系统卡中分享了我们的公平性研究示例(例如,比较不同说话者人口统计学的语音识别准确性)。
我们相信透明度和持续改进是解决偏见并建立与用户和更广泛研究社区信任的关键。为了支持可重复性和进一步的公平性研究,我们还分享了本研究中使用的详细系统消息,以便外部研究人员可以进行自己的第一方偏见实验(详情见我们的论文)。