
文章目录[隐藏]
Meta 宣布推出其首个开源多模态语言模型——Spirit LM,这一模型能够无缝集成文本和语音的输入和输出,直接与OpenAI的GPT-4o、Hume的EVI 2以及其他多模态模型竞争,同时也包括专门的文本转语音和语音转文本产品如ElevenLabs。
- 项目主页:https://speechbot.github.io/spiritlm
- GitHub:https://github.com/facebookresearch/spiritlm
- 模型:https://huggingface.co/spirit-lm/Meta-spirit-lm
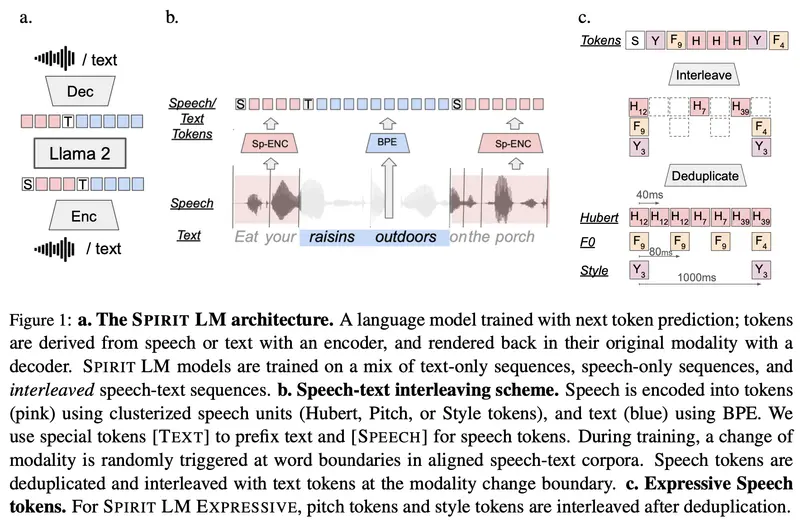
Meta Spirit LM 的特点
多模态集成
- 自动语音识别(ASR):将口语转换为书面文本。
- 文本转语音(TTS):从书面文本生成口语。
- 语音分类:根据内容或情感语调识别和分类语音。
更自然的表现力
- 音素、音高和语调Token:通过引入这些Token,Meta Spirit LM能够更好地捕捉和生成人类语音中的细微情感状态,如兴奋、悲伤、愤怒、惊讶或喜悦。
两个版本
- Spirit LM Base:使用音素Token来处理和生成语音。
- Spirit LM Expressive:包括额外的音高和语调Token,使模型能够更准确地捕捉和生成情感丰富的语音。
开源非商业用途
Meta Spirit LM 目前仅在Meta的FAIR非商业研究许可证下提供非商业用途。该许可证允许用户使用、复制、修改和创建模型的衍生作品,但仅限于非商业目的。任何分发也必须遵守非商业限制。
技术细节
1. 训练数据
- 这两个模型都在文本和语音数据集的组合上进行训练,使其能够执行跨模态任务,如语音转文本和文本转语音,同时保持语音的自然表现力。
2. 架构和能力
- Meta 发布了一份详细的研究论文,介绍了模型的架构和能力。这些资料为研究人员和开发者提供了全面的技术支持。
应用和未来潜力
1. 虚拟助手和客户服务机器人
- Meta Spirit LM Expressive 模型通过在语音生成中融入情感线索,使与AI的互动更加人性化和引人入胜。这对于虚拟助手和客户服务机器人尤其重要。
2. 医疗和教育
- 在医疗和教育领域,更自然和表现力的语音生成可以提高患者的治疗体验和学生的学习效果。
3. 内容创作
- 作家和内容创作者可以利用Meta Spirit LM生成更丰富、更有表现力的语音内容,提升用户体验。
更广泛的努力
Meta Spirit LM 是Meta FAIR向公众发布的一系列研究工具和模型的一部分。这包括对Meta的Segment Anything Model 2.1(SAM 2.1)的更新,用于图像和视频分割,该模型已在医学成像和气象学等领域得到应用。Meta 的总体目标是实现高级机器智能(AMI),强调开发既强大又可访问的AI系统。