大语言模型(LLMs)已经在多个领域取得了显著进展,特别是在代码补全方面。这些模型能够根据开发者的先前输入预测和建议代码,显著提高了开发者的生产力。然而,大型模型在速度和准确性之间难以平衡,较大的模型虽然更准确,但引入了延迟,影响了实时编码任务的效率。这一挑战促使研究人员开发更小、更高效的模型,以在保持高性能的同时减少计算负担。
- 官网:https://www.aixcoder.com
- GitHub:https://github.com/aixcoder-plugin/aixcoder-7b
- 模型:https://huggingface.co/aiXcoder/aixcoder-7b-base
- 插件: VS Code Plugin/Jetbrains Plugin
来自 aiXcoder(硅心科技)和北京大学的研究团队推出了 aiXcoder-7B,这是一个轻量级且高效的代码补全模型。aiXcoder-7B 拥有70亿参数,与较大的模型相比,实现了显著的准确性,使其成为实时编码环境的理想选择。
关键特点
- 平衡大小和性能
- 参数数量:aiXcoder-7B 仅有70亿参数,远小于 CodeLlama-34B 和 StarCoder2-15B 等大型模型。
- 响应时间:较小的模型尺寸显著减少了计算时间和延迟,提高了实时编码任务的效率。
- 多目标训练
- NextToken Prediction (NTP):预测下一个标记,提高代码生成的准确性。
- Fill-In-the-Middle (FIM):预测代码中间缺失的部分,增强模型对代码结构的理解。
- Structured Fill-In-the-Middle (SFIM):进一步考虑代码的语法和结构,使模型在广泛的编码场景中更准确地预测。
- 大规模数据集
- 数据量:aiXcoder-7B 使用了1.2万亿个唯一 Token 的数据集进行训练。
- 数据来源:数据集包括来自多种编程语言的3.5TB源代码,确保模型可以处理 Python、Java、C++ 和 JavaScript 等多种语言。
- 数据处理:严格的采集、清理、去重和质量检查流程保证了数据的质量。
- 创新采样技术
- 多样化采样策略:基于文件内容相似性、文件间依赖性和文件路径相似性的采样策略,帮助模型理解跨文件上下文,提高代码补全的准确性。
实验结果
aiXcoder-7B 在多个基准测试中表现出色,优于其他类似大小的 LLMs:
- HumanEval:在 HumanEval 基准测试中,aiXcoder-7B 达到了54.9%的 Pass@1 分数,超过了 CodeLlama-34B(48.2%)和 StarCoder2-15B(46.3%)。
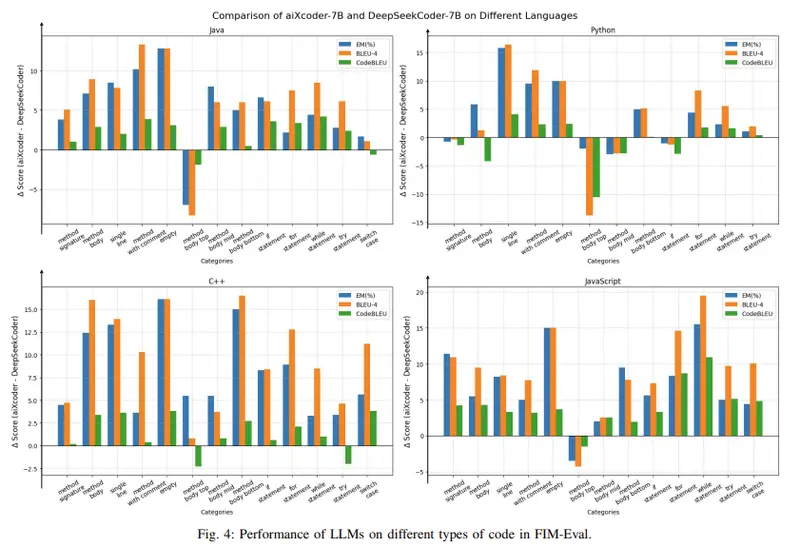
- FIM-Eval:在 FIM-Eval 基准测试中,aiXcoder-7B 在 Java 和 Python 等语言中表现出色,展示了强大的泛化能力。
- 代码风格匹配:生成的代码在风格和长度上与人类编写代码高度匹配。例如,在 Java 中,aiXcoder-7B 生成的代码仅是人类编写代码大小的0.97倍。
潜在影响
aiXcoder-7B 的推出解决了 LLMs 在代码补全领域的一个关键差距,通过提供高效且准确的模型,提高了开发者的生产力。其主要优点包括:
- 高效性:较小的模型尺寸和快速的响应时间,适用于实时编码任务。
- 准确性:在多个基准测试中表现出色,生成的代码质量高。
- 多语言支持:能够处理多种编程语言,适应不同的开发环境。
aiXcoder-7B 通过创新的多目标训练、大规模数据集和先进的采样技术,实现了在保持高性能的同时减少计算负担的目标。它在多个基准测试中的优秀表现使其成为需要可靠、实时代码补全的开发者的理想选择。aiXcoder-7B 的研究为未来轻量级 LLMs 的发展提供了宝贵的经验和方向。