
文章目录[隐藏]
GPT-4o 是一个包罗万象的多模态语言模型,能够理解视觉、听觉和文本模态,并直接输出音频,支持灵活的双工交互。尽管开源社区已经实现了一些类似的功能,但训练一个包含所有模态的统一模型仍然极具挑战性。这主要是由于多模态数据的复杂性、复杂的模型架构和训练过程。
Mini-Omni2
为了解决这一挑战,清华大学和启元世界的研究人员介绍了一个名为 Mini-Omni2 的多模态语言模型。Mini-Omni2旨在模拟一个能够理解视觉、听觉和文本信息,并且能够直接输出音频,支持灵活的双向交互的全能模型GPT-4o。Mini-Omni2是一个视觉-音频助手,能够实时、端到端地对视觉和音频查询做出语音响应。
例如,你正在使用一个智能家居设备,你可以通过语音询问设备:“今天的天气怎么样?”设备上的Mini-Omni2模型会接收到你的语音指令,理解你的问题,然后生成并播放相应的语音回答,告诉你天气情况。同时,如果你在设备上看到某个不理解的图标,你也可以问:“这个图标是什么意思?”模型会分析图标的视觉信息,并给出语音解释。这样的交互使得用户体验更加自然和流畅。
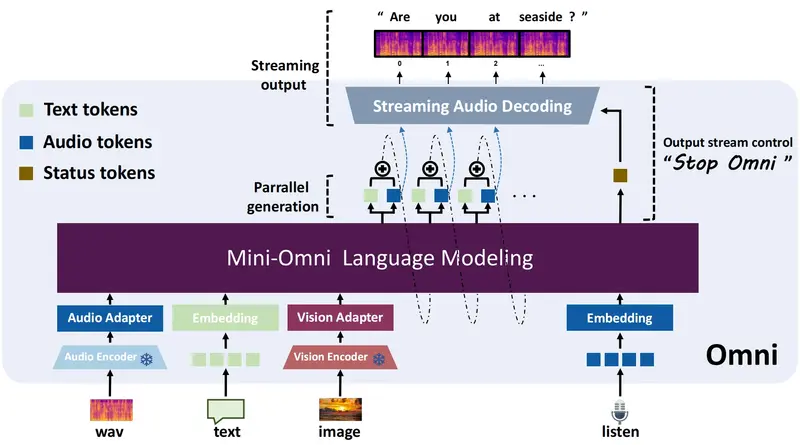
主要特点
- 多模态理解:
- 视觉理解:集成预训练的视觉编码器,能够理解图像和视频内容。
- 听觉理解:集成预训练的听觉编码器,能够理解音频和语音内容。
- 文本理解:支持文本输入,能够理解和生成文本。
- 实时端到端语音响应:
- 语音合成:能够生成高质量的语音响应,支持实时交互。
- 三阶段训练过程:
- 模态对齐:通过三阶段的训练过程对齐不同的模态,使语言模型能够在有限的数据集上训练后处理多模态输入和输出。
- 第一阶段:单独训练每个模态的编码器。
- 第二阶段:跨模态对齐,通过多模态数据对齐不同模态的表示。
- 第三阶段:联合训练,整合所有模态的编码器和解码器,优化整体性能。
- 模态对齐:通过三阶段的训练过程对齐不同的模态,使语言模型能够在有限的数据集上训练后处理多模态输入和输出。
- 基于命令的中断机制:
- 灵活交互:引入了一种基于命令的中断机制,使用户能够进行更灵活的交互,例如中断当前对话并发起新的查询。
工作原理:
Mini-Omni2的工作原理基于以下几个关键步骤:
- 预训练编码器:使用预训练的视觉编码器(如CLIP)和语音编码器(如Whisper)来提取视觉和音频输入的特征。
- 特征融合:将预训练编码器的输出与文本嵌入向量拼接,形成模型的输入。
- 多模态建模:模型通过一个特殊的词汇表,将文本、语音和视觉特征统一建模,实现多模态输入和输出。
- 双向能力:模型能够实时编码接收到的音频波形,并生成控制自身输出的标记,允许在每次生成时控制输出流。
实验结果
- 模态性能:Mini-Omni2 在各个模态中保持了良好的性能,特别是在视觉理解和听觉理解方面。
- 多模态交互:实验表明,Mini-Omni2 能够有效地处理多模态输入,并生成高质量的多模态输出。
- 实时响应:Mini-Omni2 支持实时端到端的语音响应,用户可以进行流畅的对话交互。